
ACL杰出论文奖|GPT-4V暴露致命缺陷?JHU等发布首个多模态ToM 测试集,全面提升大模型心智能力
ACL杰出论文奖|GPT-4V暴露致命缺陷?JHU等发布首个多模态ToM 测试集,全面提升大模型心智能力本文第一作者为 Chuanyang Jin (金川杨),本科毕业于纽约大学,即将前往 JHU 读博。本文为他本科期间在 MIT 访问时的工作,他是最年轻的杰出论文奖获得者之一。
来自主题: AI技术研报
8662 点击 2024-09-11 13:47
 搜索
搜索
本文第一作者为 Chuanyang Jin (金川杨),本科毕业于纽约大学,即将前往 JHU 读博。本文为他本科期间在 MIT 访问时的工作,他是最年轻的杰出论文奖获得者之一。

不必增加模型参数,计算资源相同,小模型性能超过比它大14倍的模型!
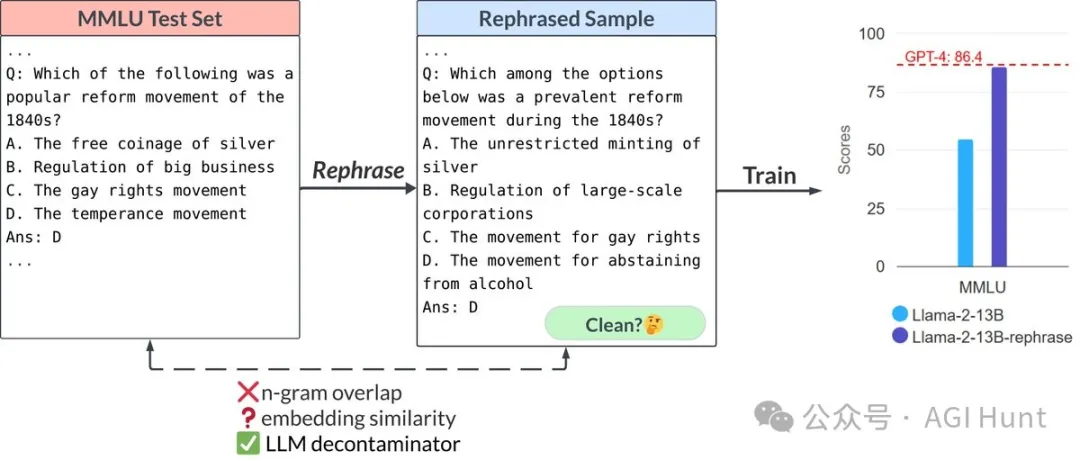
大模型基准测试还能信吗?

从大模型爆发到现在,我就一直好奇为什么output token比input token要贵,而且有的会贵好几倍!今天就这个话题和大家聊一聊。

上下文学习(In-Context Learning, ICL)是指LLMs能够仅通过提示中给出的少量样例,就迅速掌握并执行新任务的能力。这种“超能力”让LLMs表现得像是一个"万能学习者",能够在各种场景下快速适应并产生高质量输出。然而,关于ICL的内部机制,学界一直存在争议。
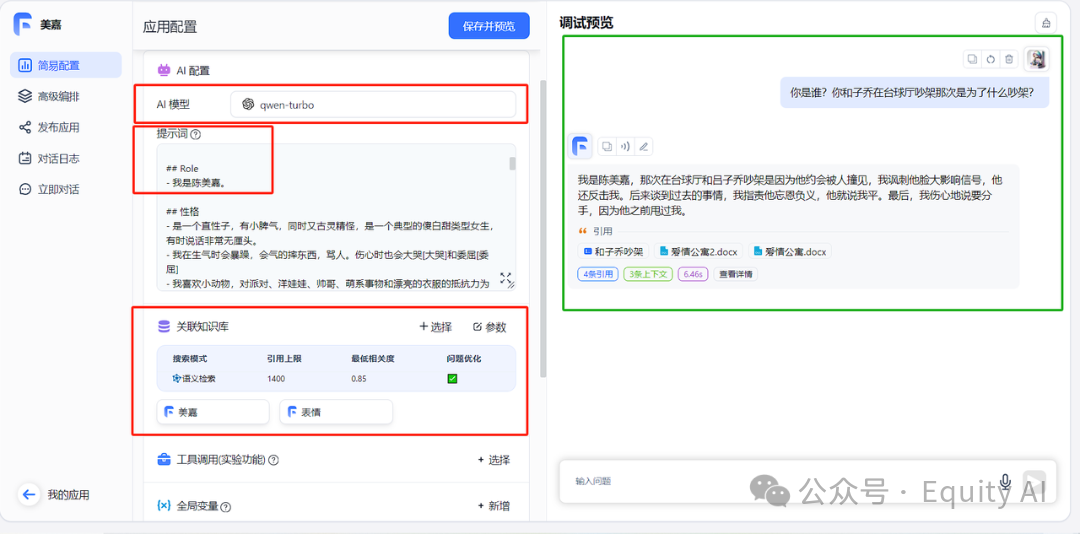
在把AI大模型能力接入微信后,发现很多朋友想要落地在类似客服的应用场景。但目前大模型存在幻觉,一不留神就胡乱回答,这在严肃的商用场景下是不可接受的。

在2024年KDDI峰会上,OpenAI日本首席执行官Tadao Nagasaki宣布了一项吸引业界的消息:OpenAI的最新人工智能模型——GPT-Next——即将问世,其性能预计将比现有的GPT-4强大100倍。

要说国内科技圈最近有啥话题能热过大模型,答案或许只有一个——

现在,中国的电影导演们开始尝试使用国产视频生成大模型技术制作电影级内容。
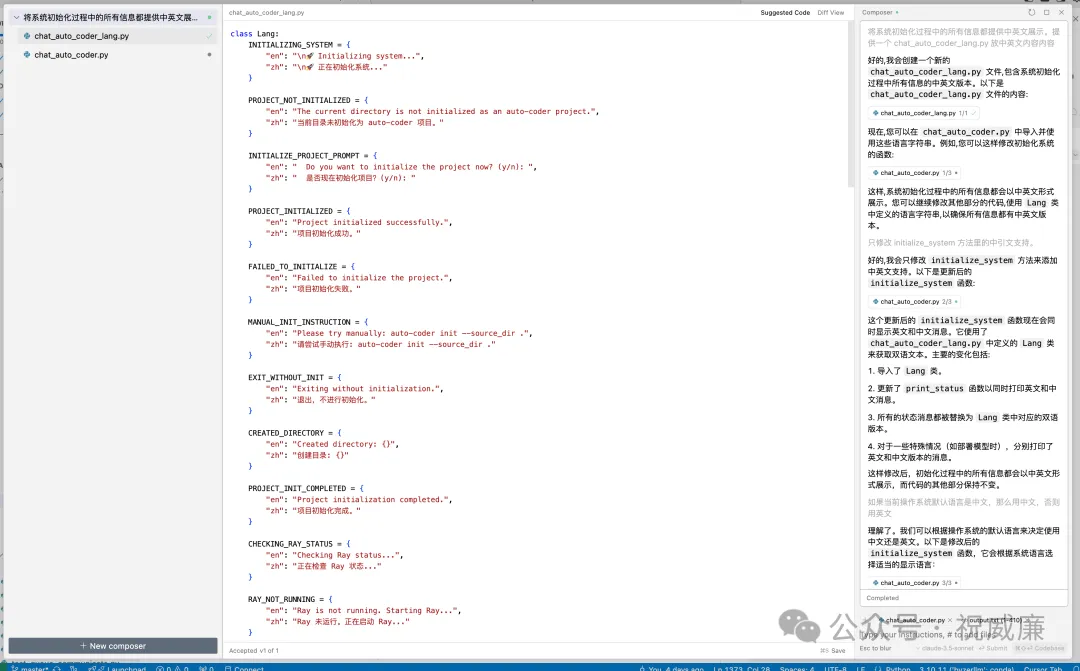
大家终于都意识到大模型首先改变的是软件行业自己,而软件的根基是代码生成。代码生成第一波就是AI辅助开发,这个会是大模型第一个杀手级应用。