「LLM」这个名字不好,Karpathy认为不准确、马斯克怒批太愚蠢
「LLM」这个名字不好,Karpathy认为不准确、马斯克怒批太愚蠢LLM 应该改名吗?你怎么看。
来自主题: AI资讯
5307 点击 2024-09-15 14:34
 搜索
搜索
LLM 应该改名吗?你怎么看。

当大模型开始思考

拔草星人的好消息来啦!中科院自动化所和阿里云一起推出了街景定位大模型,只要一张照片就能实现街道级精度的定位。

什么?大模型也许很快就能生成《黑神话·悟空》这种3A大作了?!直接看一则demo,《西游记》这就上桌

长视频平台的下一个必争之地?

科学事实是最有力的反证据。
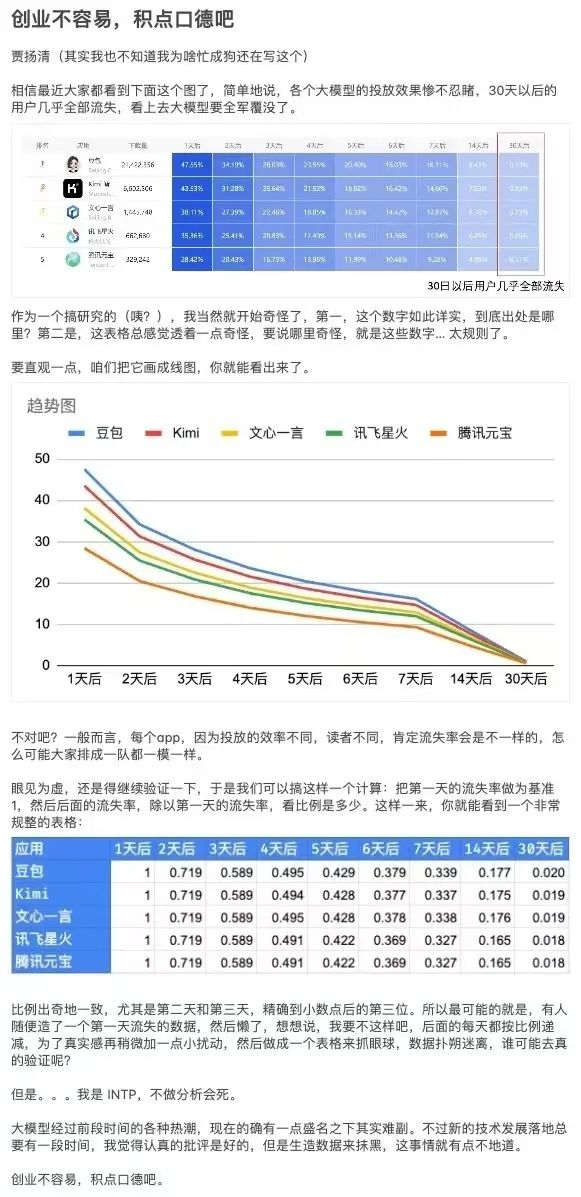
最全能的AI对话,最留不住用户?
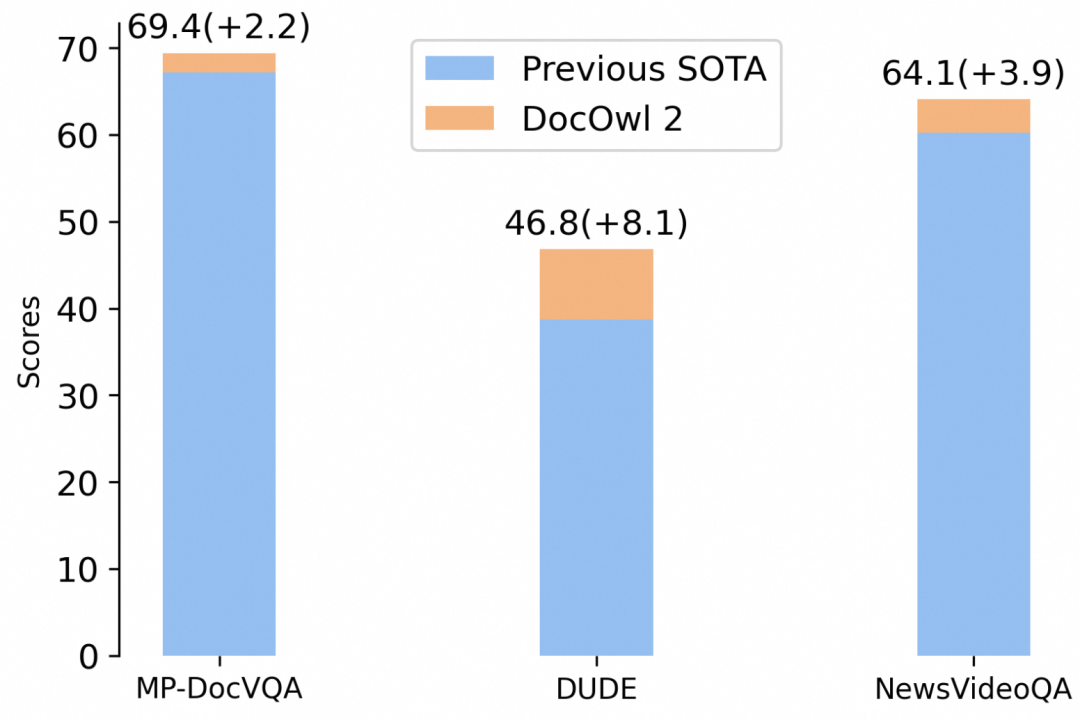
高效多页文档理解,阿里通义实验室mPLUG团队拿下新SOTA。

字节和浙大联合研发的项目Loopy火了!

当电信网络用上了大模型,会是一种什么体验?