
迈氪锶:构建超级应用体
迈氪锶:构建超级应用体在当今数字化转型的浪潮中,“大模型技术”已经成为企业级智能平台发展的新引擎。迈氪锶(上海)科技有限公司正是在这样的技术革新背景下,致力于构建世界级的新一代企业级智能平台。
来自主题: AI资讯
8301 点击 2024-12-05 09:15
 搜索
搜索
在当今数字化转型的浪潮中,“大模型技术”已经成为企业级智能平台发展的新引擎。迈氪锶(上海)科技有限公司正是在这样的技术革新背景下,致力于构建世界级的新一代企业级智能平台。

近日,眼科医学领域迎来了一项重大突破,由北京同仁眼科中心主任、河南省医学科学院院长王宁利教授领衔的科研团队携手成都中医药大学眼科学院/附属银海眼科医院段俊国教授科研团队等多个团队共同研发出了国内首个多模态、多任务眼科AI大模型——“伏羲慧眼”。

亚马逊云科技上演了一场生成式 AI 能力的「王者归来」。

大模型的能力是否已经触及极限?Business Insider采访了12位业内前沿人士。众人表示,利用新类型的数据、将推理能力融入系统, 以及创建更小但更专业的模型,将成为新一代的范式。

当前,识因在政府、企业领域已经有多家客户,并已产生稳定的商业化收入。

谷歌最火爆大模型产品,背后团队刚刚集体离职创业了!

亚马逊宣布扩建AI计算集群并推出新AI产品。 豪掷80亿美元后,亚马逊“绑死”Anthropic,要建全球最大AI计算集群。
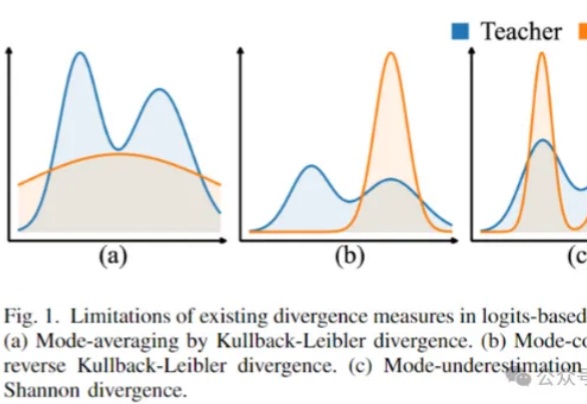
用大模型“蒸馏”小模型,有新招了!

是谁在挖“百度”墙角? 由ChatGPT掀起的AI大模型浪潮已有两年,AI正迅速渗透到各行各业。
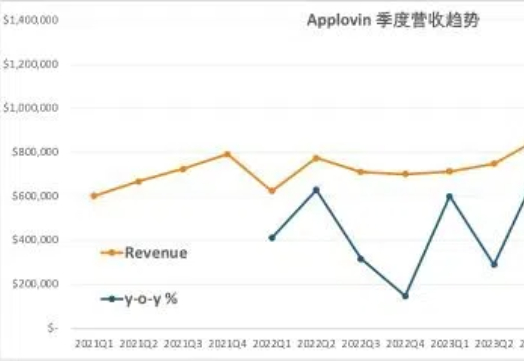
2023年初,GPT3.5发布,效果让全世界咋舌。人们恐慌,人工智能时代来临了。随之而来的是各大互联万公司纷纷下场比拼大模型,几乎每个月都能耳听目见新的大模型诞生,并且在某个参数上和“GPT几点几”媲美。随着大模型不断迭代与渗透,一个关键问题随之而来:谁是大模型浪潮的最大受益者?