
主攻智能座舱解决方案,艾博连正把AI大模型搬上车 | 早期项目
主攻智能座舱解决方案,艾博连正把AI大模型搬上车 | 早期项目艾博连已经启动了独立融资计划。
来自主题: AI资讯
5353 点击 2025-03-11 09:42
 搜索
搜索
艾博连已经启动了独立融资计划。
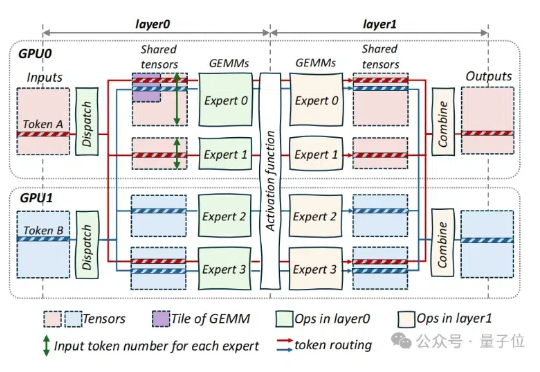
字节对MoE模型训练成本再砍一刀,成本可节省40%! 刚刚,豆包大模型团队在GitHub上开源了叫做COMET的MoE优化技术。

北京时间3月10日,据《华尔街日报》报道,富士康母公司鸿海已研发出中国台湾地区首个具备先进推理能力的大模型,性能上落后于DeepSeek的部分大模型。鸿海周一表示,已自主研发了具备推理能力的人工智能(AI)大语言模型FoxBrain,并在四周内完成训练。FoxBrain最初为公司内部使用而设计,具备数据分析、数学运算、推理以及代码生成的能力。
最近AI一直是很火的话题,Deepseek也是一夜爆火,但是实际使用下来发现Deepseek好像和其他大模型一样,并没有什么厉害之处,而且官网经常服务器繁忙。
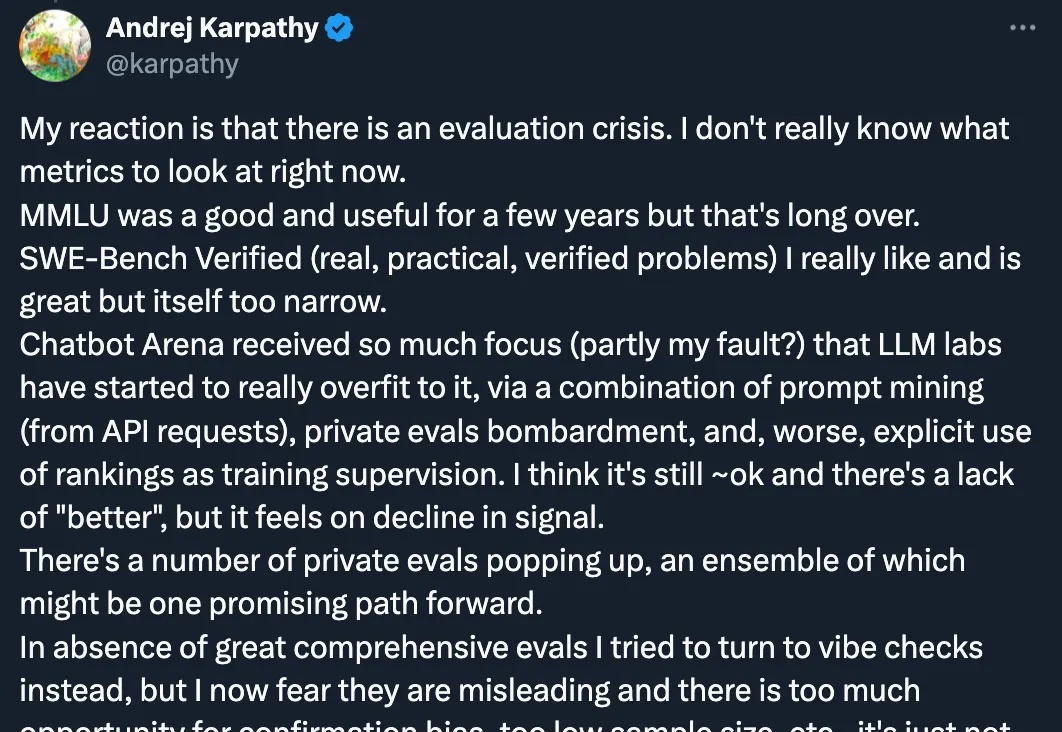
一直以来,AI 领域的研究者都喜欢让模型去挑战那些人类热衷的经典游戏,以此来检验 AI 的「智能程度」。
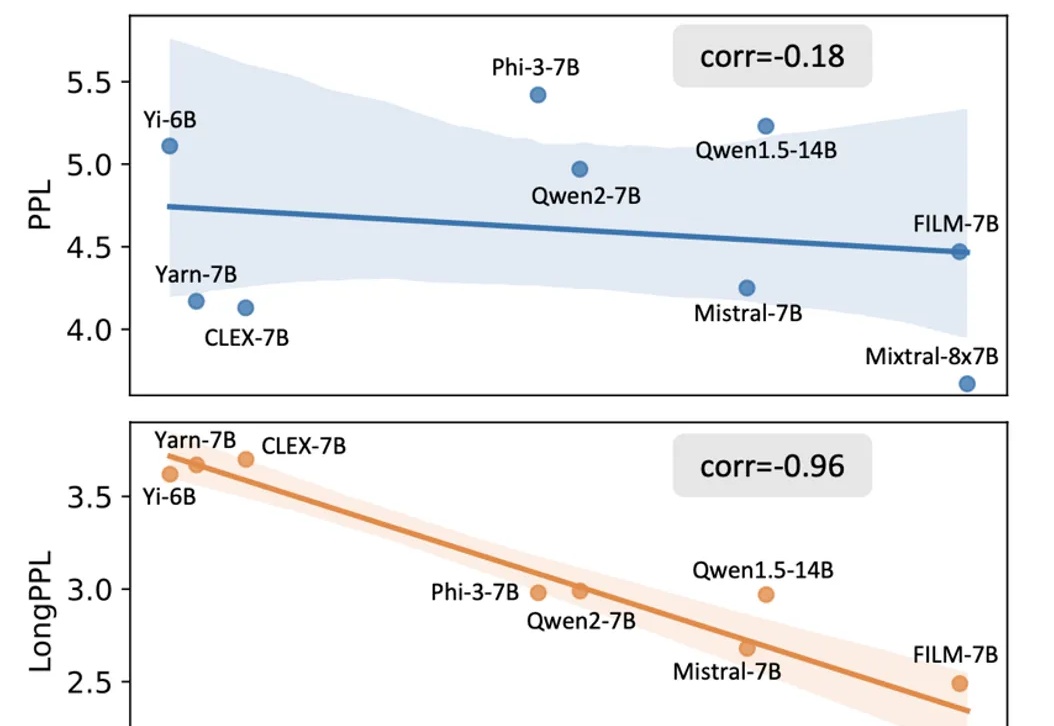
随着大模型在长文本处理任务中的应用日益广泛,如何客观且精准地评估其长文本能力已成为一个亟待解决的问题。
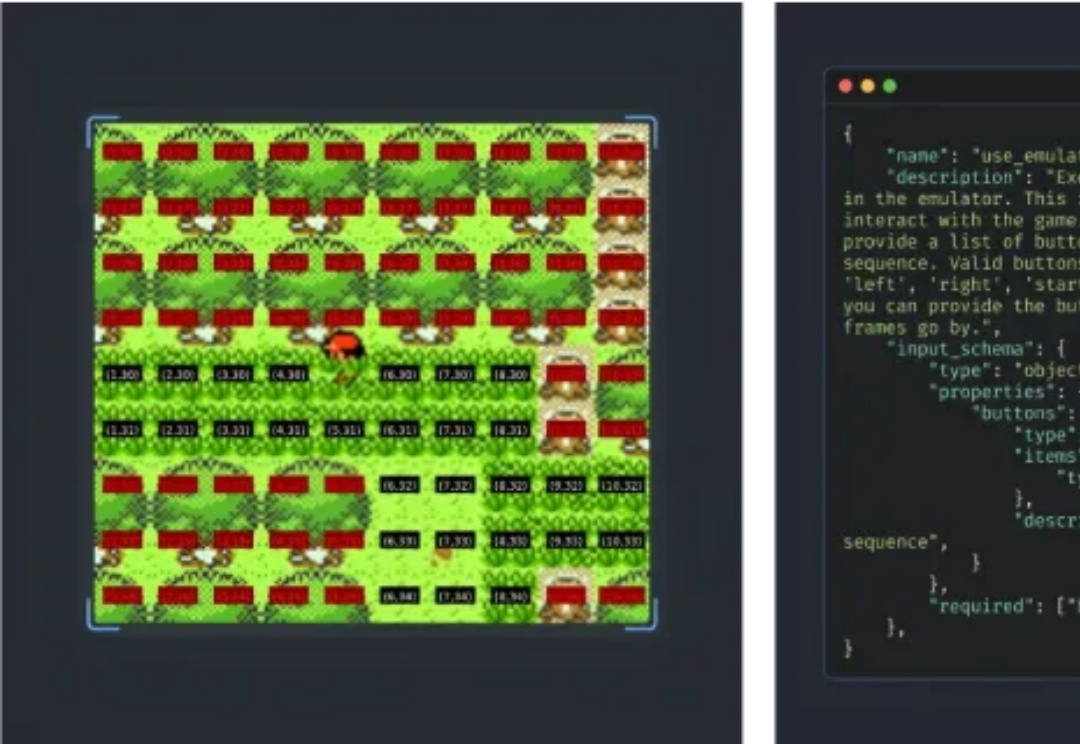
半个月前,Anthropic 发布了其迄今为止最聪明的 AI 模型 —— Claude 3.7 Sonnet。

在面对复杂的推理任务时,SFT往往让大模型显得力不从心。最近,CMU等机构的华人团队提出了「批判性微调」(CFT)方法,仅在 50K 样本上训练,就在大多数基准测试中优于使用超过200万个样本的强化学习方法。

DeepSeek-R1 等模型通过展示思维链(CoT)让用户一窥大模型的「思考过程」,然而,模型展示的思考过程真的代表了模型的内在推理机制吗?在医疗诊断、自动驾驶、法律判决等高风险领域,我们能否真正信任 AI 的决策?

思维链引发的战争。