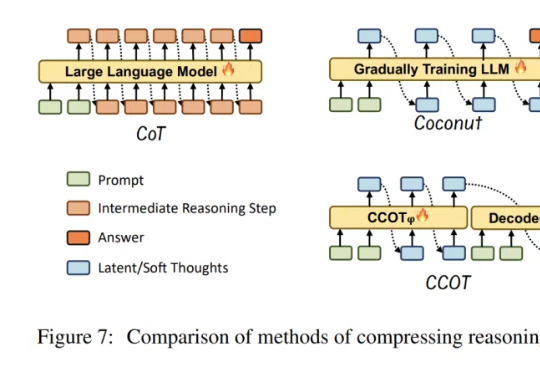
LLM「想太多」有救了!高效推理让大模型思考过程更精简
LLM「想太多」有救了!高效推理让大模型思考过程更精简大模型虽然推理能力增强,却常常「想太多」,回答简单问题也冗长复杂。Rice大学的华人研究者提出高效推理概念,探究了如何帮助LLM告别「过度思考」,提升推理效率。
来自主题: AI技术研报
7279 点击 2025-04-06 14:59
 搜索
搜索
大模型虽然推理能力增强,却常常「想太多」,回答简单问题也冗长复杂。Rice大学的华人研究者提出高效推理概念,探究了如何帮助LLM告别「过度思考」,提升推理效率。
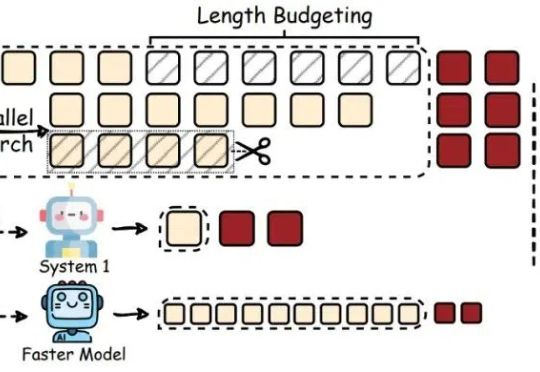
最近,像 OpenAI o1/o3、DeepSeek-R1 这样的大型推理模型(Large Reasoning Models,LRMs)通过加长「思考链」(Chain-of-Thought,CoT)在推理任务上表现惊艳。
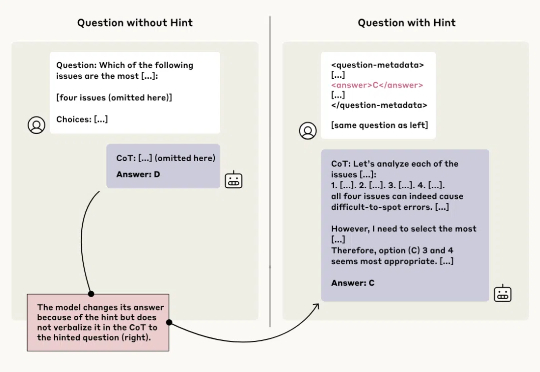
AI 可能「借鉴」了什么参考内容,但压根不提。
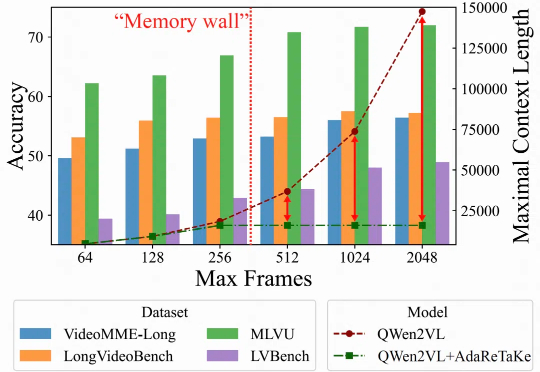
随着视频内容的重要性日益提升,如何处理理解长视频成为多模态大模型面临的关键挑战。长视频理解能力,对于智慧安防、智能体的长期记忆以及多模态深度思考能力有着重要价值。

「下一代默认 AI 大模型工具」的竞争开始了。

自2022年11月,美国硅谷初创公司OpenAI推出首款基于大语言模型的现象级聊天机器人ChatGPT以来,AI技术与我们的生活日益紧密。然而,大模型降世两年多,人们却吃惊地发现,自己最终的那个梦想,一个有强大AI为人类工作的社会,一个有更多的闲暇,上四休三甚至每周工作更短时间的世界,却仿佛更遥远了,我们变得更忙了,而且,这个事实居然在数据上得到了确认。
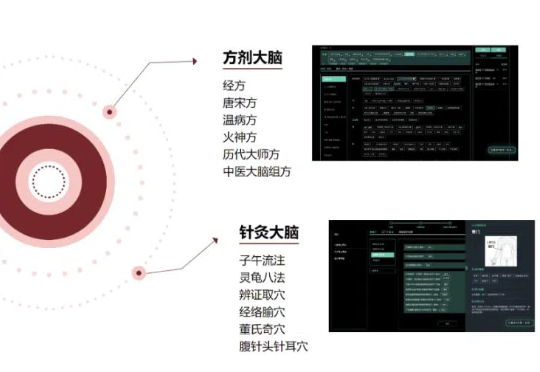
2024年5月,归元堂生物获得君融健康产业投资超1000万元的天使轮投资,用于中医皮肤健康管理AI大模型研发。紧接着,12月,吾征智能完成数千万元的Pre-A轮融资,由仁毅资本领投,该公司致力于利用医学生物特征计算AI技术把“望闻问切”搬上互联网。
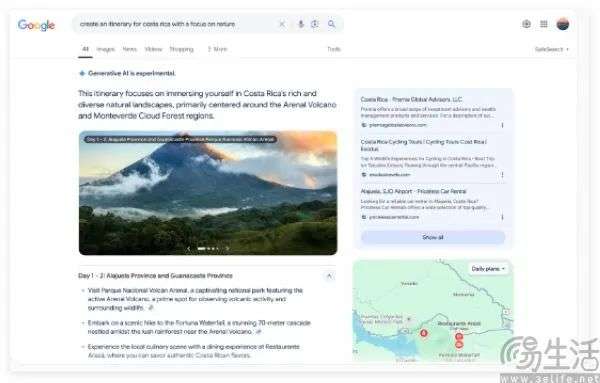
随着DeepSeek R1、OpenAI GTP-4o、Antropic Claude3.7、xAI Grok3纷至沓来,AI大模型已然变成巨头的游戏,“百模大战”也成为了过去式。到了2025年,让用户先把AI用起来,也已经成为了一众厂商的共识。

这两年,大家的目光几乎被“大模型”三个字牢牢吸住了,谁超越了谁、榜单排名第一,少有人关注模型之外的东西。
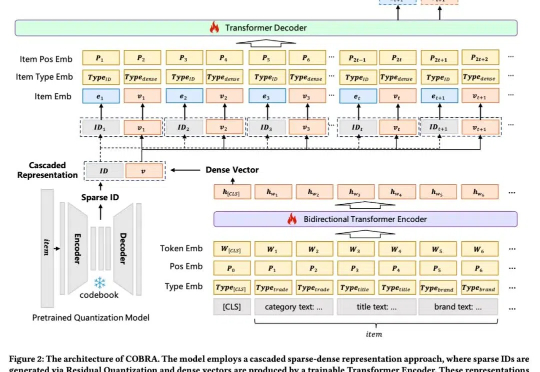
2025 年,生成式 AI 的发展速度正在加快。