
腾讯给AI下了一剂猛药
腾讯给AI下了一剂猛药海内外大厂大模型研发正在进入新升级周期,为了加速补齐技术短板,腾讯混元近日进行了大幅架构调整,重构研发体系。但面对海内外对手的凌厉攻势,手握大把国民级应用的腾讯,还需要找到更好的攻防节奏。
来自主题: AI资讯
9210 点击 2025-05-11 10:28
 搜索
搜索
海内外大厂大模型研发正在进入新升级周期,为了加速补齐技术短板,腾讯混元近日进行了大幅架构调整,重构研发体系。但面对海内外对手的凌厉攻势,手握大把国民级应用的腾讯,还需要找到更好的攻防节奏。

5月9日,京西智谷潭柘智空基座大模型体系及应用平台建设项目开标,北京智谱清言科技有限公司中标,金额6400万元。根据此前公开的采购公告,本项目招标范围是:文生图片平台、图生视频与视频生视频平台、汉藏平台、多语种平台、AI数字人与垂类大模型对接平台、集成总平台等。

小天才和小镇做题家,在AI赛道都有光明的未来。


日本AI产业呈现封闭生态,头部公司Preferred Networks和PKSHA依赖本土大企业定制化服务,缺乏国际化突破。前者技术强但转向本土合作,后者侧重应用型AI盈利。产业链由大企业、政府、大学形成闭环,政策推动项目制需求,抑制通用型AI创新,导致日本错失全球AI竞争机遇。
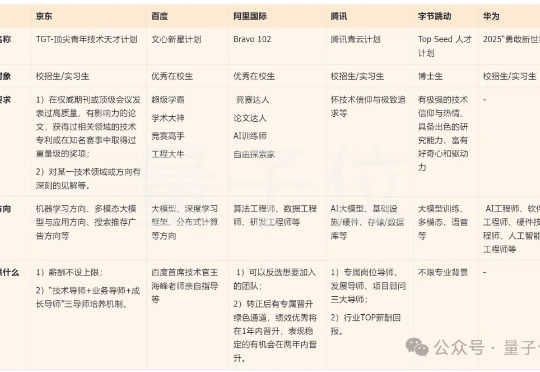
眼花缭乱了。为争夺AI人才,大厂们齐齐放大招!
在短视频成为亿万用户日常生活标配的当下,它不仅是一种娱乐方式,更是人们获取信息、表达观点、构建社交的主要媒介。

基辛格在人生最后一本书中将AI类比为新时代的“核武器”,认为其将重塑国际权力格局,加剧地缘冲突但也可转化为战略工具。他强调中美需通过对话建立AI治理机制,避免实体战争,主张以灵活外交手段实现均衡,延续其维护美国领导地位的实用主义立场。
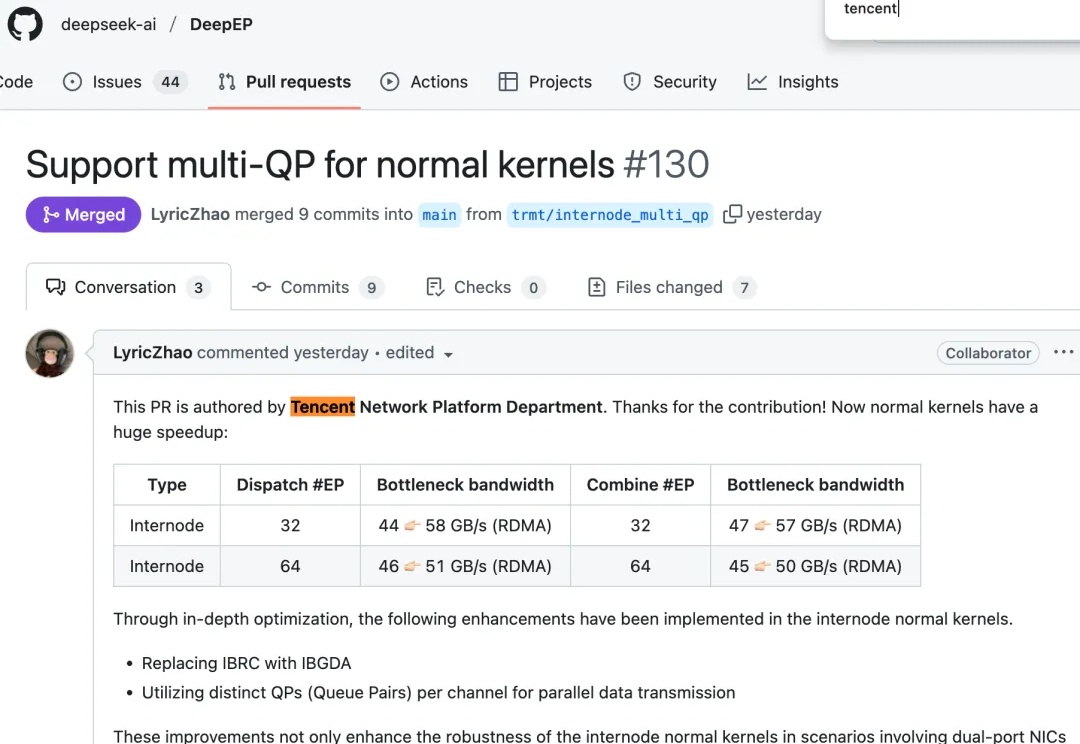
最近,DeepSeek工程师在GitHub上高亮了来自腾讯的代码贡献,并用“huge speedup”介绍了这次性能提升。
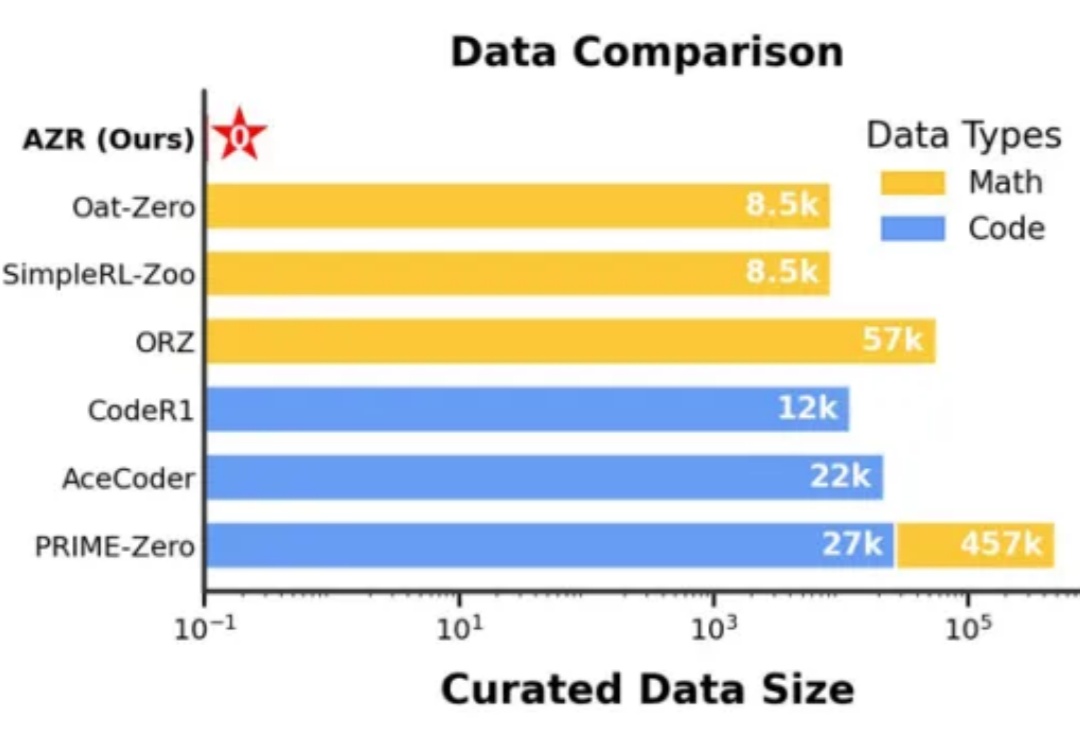
在人工智能领域,推理能力的进化已成为通向通用智能的核心挑战。近期,Reinforcement Learning with Verifiable Rewards(RLVR)范式下涌现出一批「Zero」类推理模型,摆脱了对人类显式推理示范的依赖,通过强化学习过程自我学习推理轨迹,显著减少了监督训练所需的人力成本。