
梁文锋署名DeepSeek新论文:公开V3大模型降本方法
梁文锋署名DeepSeek新论文:公开V3大模型降本方法梁文锋亲自参与的DeepSeek最新论文,来了!
来自主题: AI技术研报
9123 点击 2025-05-16 11:47
 搜索
搜索
梁文锋亲自参与的DeepSeek最新论文,来了!
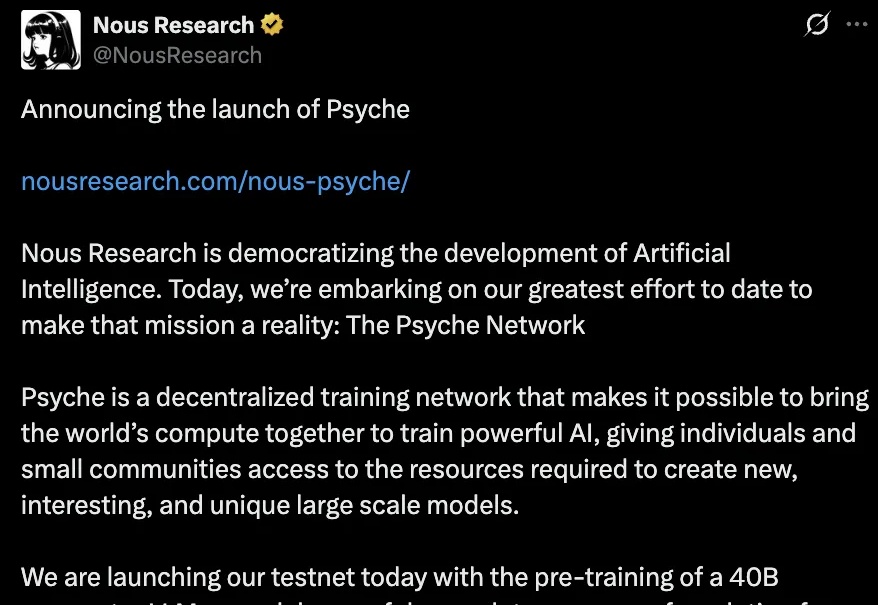
打破科技巨头算力垄断,个人开发者联手也能训练超大规模AI模型?
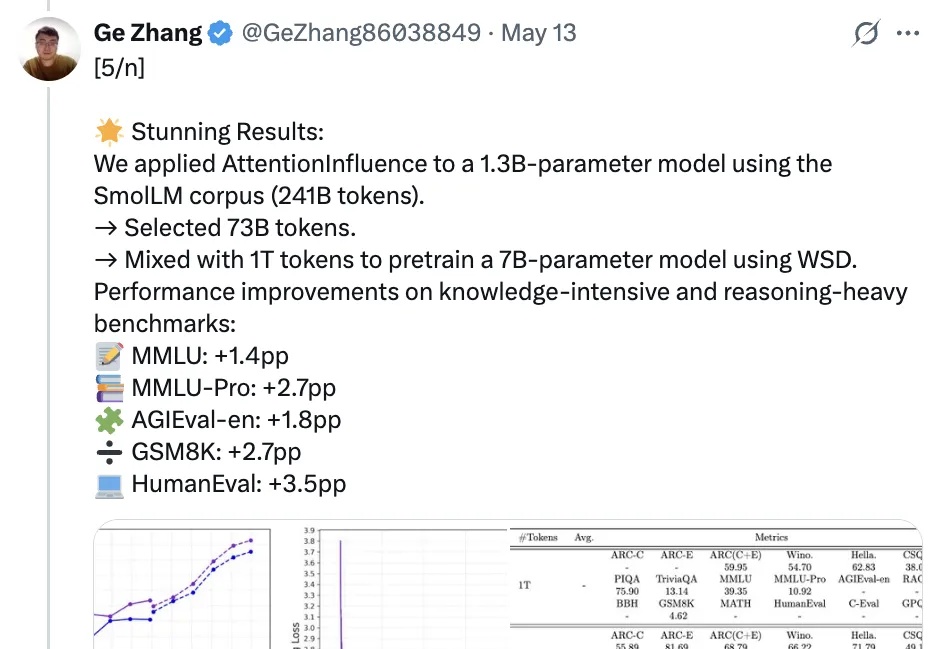
和人工标记数据说拜拜,利用预训练语言模型中的注意力机制就能选择可激发推理能力的训练数据!
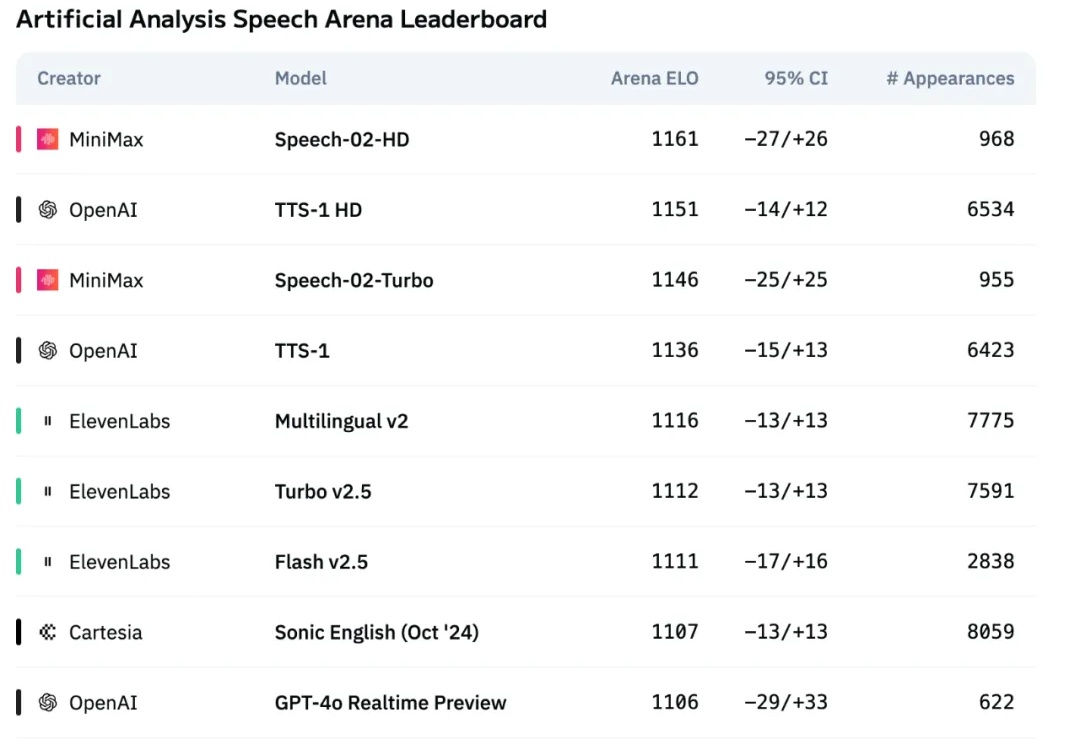
国产大模型进步的速度早已大大超出了人们的预期。年初 DeepSeek-R1 爆火,以超低的成本实现了部分超越 OpenAI o1 的表现,一定程度上让人不再过度「迷信」国外大模型。

今天凌晨,全球著名大模型整合应用平台Poe发布了,2025年春季AI模型使用趋势报告。

多年来,生成式AI供应商一直向公众保证,大语言模型符合安全准则,并加强了对产生有害内容的侵害。然而,一种看似简单但非常有效的提示词策略,能够让所有主流大模型开启「无限制模式」。

在 InfoQ 举办的 AICon 全球人工智能开发与应用大会上摯文集团生态技术负责人李波做了专题演讲“大模型在社交生态领域的落地实践”,演讲从摯文集团实际的生态问题出发,从多模态大模型如何进行对抗性生态内容理解、如何进行细粒度用户性质判定,以及如何进行人机协同降本提效等方向展开。
为什么我们需要智能写作Agent?
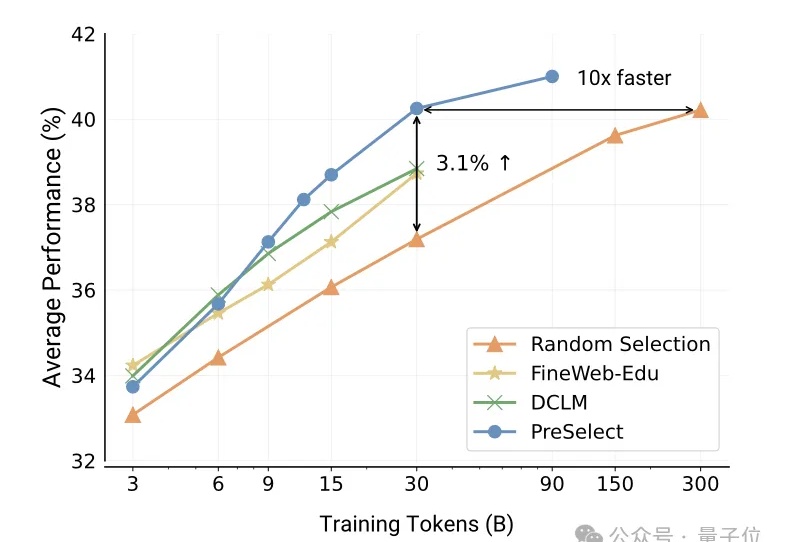
vivo自研大模型用的数据筛选方法,公开了。

医疗大模型快速渗透医院,2025年百强医院部署率达98%,专科垂直模型达55个,面临数据安全挑战。