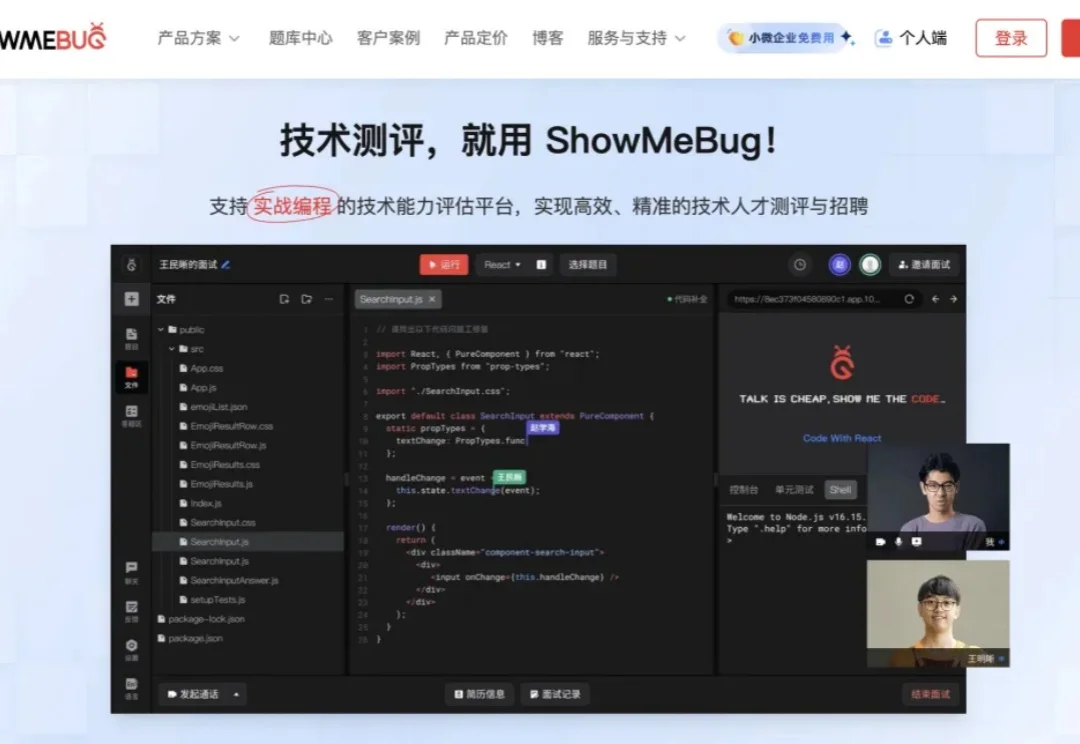
Agent 的下半场,是账单|对话 OpenClacky 李亚飞
Agent 的下半场,是账单|对话 OpenClacky 李亚飞让 AI 来管理代码的话,每次读 500 行反而比读 1000 行更费 Token,而且人工编排流程真不如让大模型自己定,「很多的事儿,还是很反直觉的」
来自主题: AI资讯
9262 点击 2026-05-21 10:14
 搜索
搜索
让 AI 来管理代码的话,每次读 500 行反而比读 1000 行更费 Token,而且人工编排流程真不如让大模型自己定,「很多的事儿,还是很反直觉的」
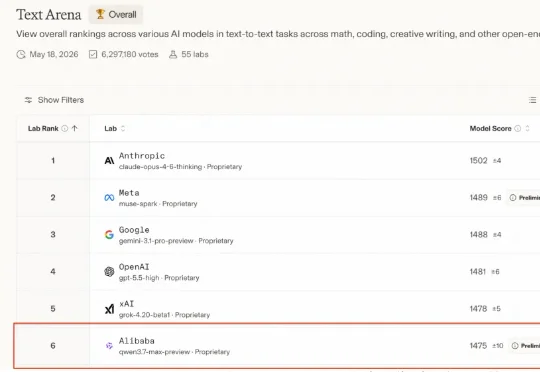
仅仅一个月后,阿里又带着最强旗舰模型杀回来了!今天上午,在 2026 阿里云峰会上,阿里全新一代千问旗舰模型 Qwen3.7-Max 登场了!在 Arena 公布的最新一期全球大模型盲测总榜中,Qwen3.7-Max 总成绩位列国产模型第一:傲视一众国产大模型
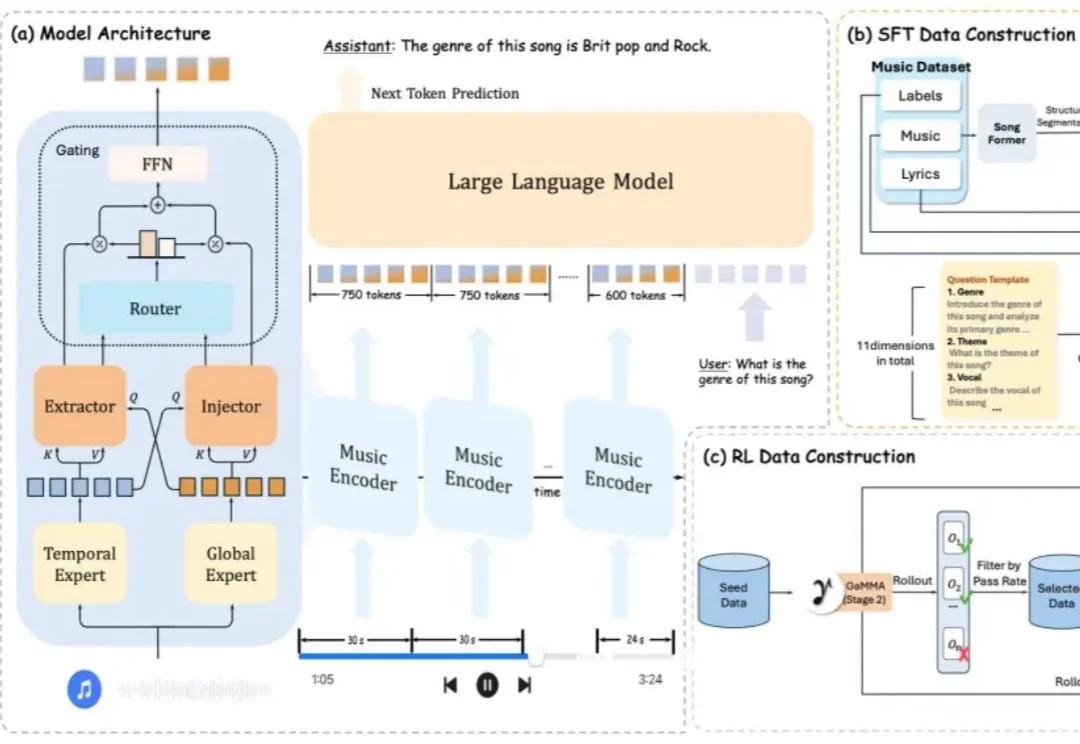
大模型的能力边界正在不断拓展,从文字到视觉,再到音频,全模态理解已渐成现实。然而,当你问一个多模态大模型「这首歌的高潮从第几秒开始?」或者「第 30 秒之后乐器编配发生了什么变化?」,得到的往往是一个模糊甚至错误的回答。
过去一段时间,很多人对大模型都有一个明显感受:token 总是不够用。

伯克利等发布FST框架:通过快慢分层解决大模型持续学习死局。
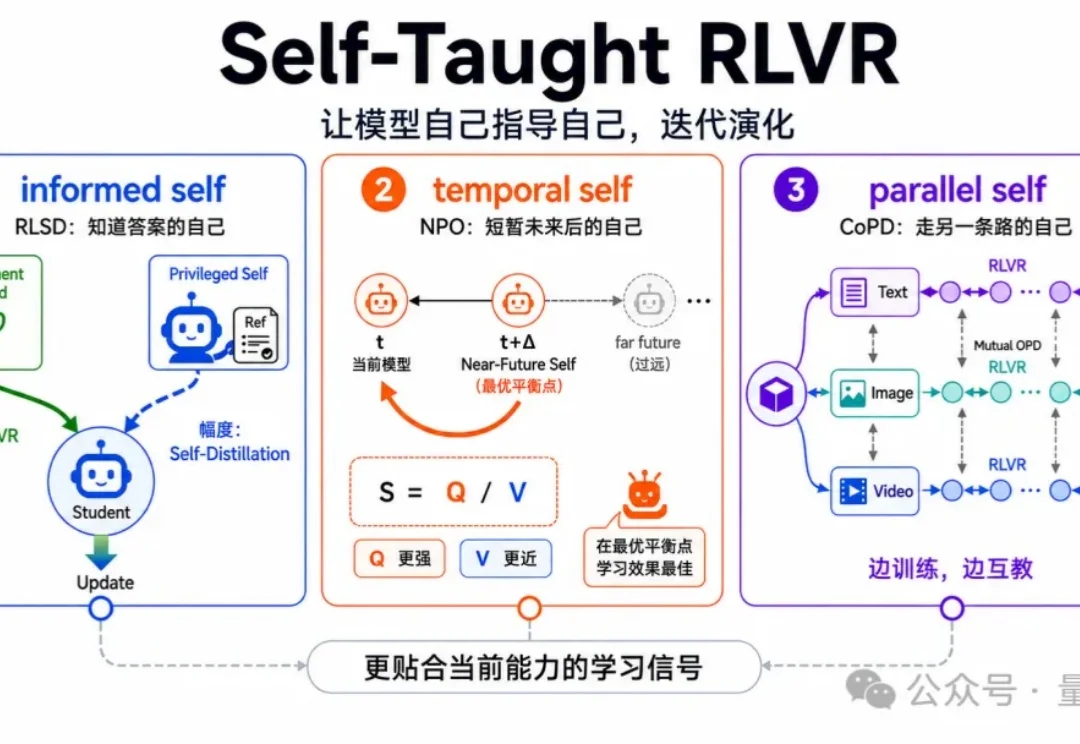
最近,京东和中科院信工所展开了Self-Taught RLVR的系列研究,并连发三篇后训练新作。

今年以来,Palantir股价已累计下跌近20%。

近年来,Chain-of-Thought(CoT)推理已经成为提升大语言模型和多模态大语言模型复杂问题求解能力的重要技术路径。

最近几天,中国电信、中国移动、中国联通接连推出Token套餐及相关AI服务,面向个人、家庭、开发者、中小微企业等用户销售大模型调用量。这是三大运营商首次正式入局Token生意,而此前相关业务由大模型厂商、互联网大厂和云服务商主导。
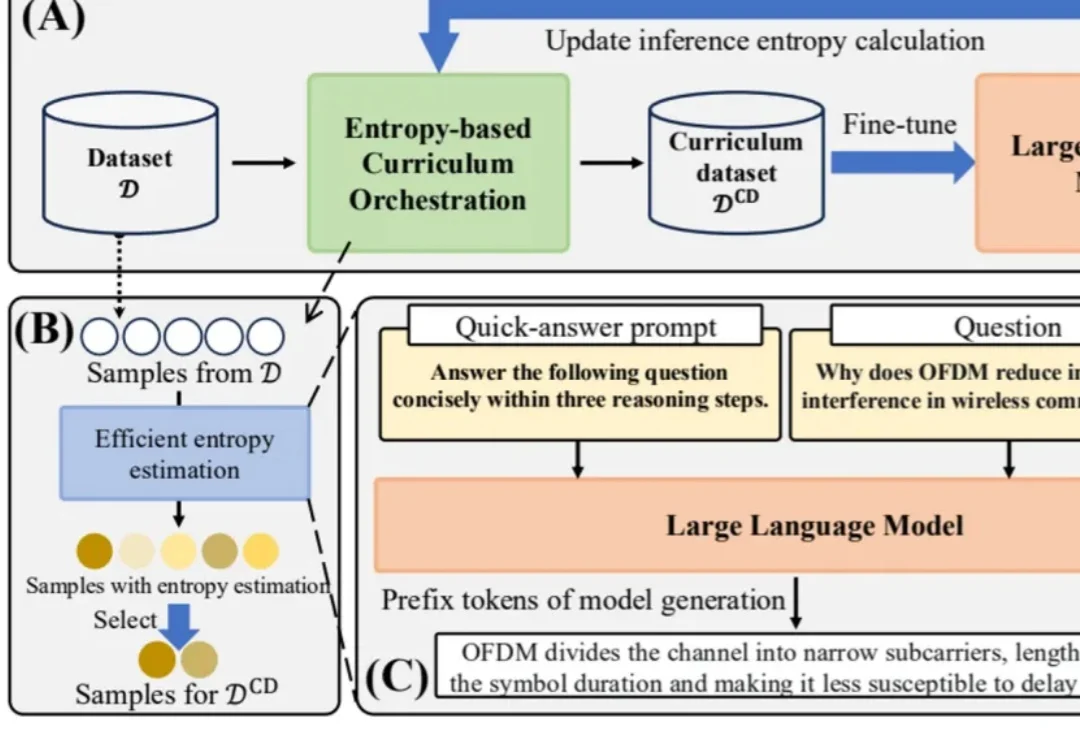
在大模型后训练中,数据不再只是 “越多越好”,而是要像人类学习一样,动态选择最合适难度的样本。华为提出的 EDCO 方法,将样本难度估计与动态课程编排引入领域大模型微调;数月后,由 Rutgers、Amazon、Google 等作者参与的 DARE 论文即引用 EDCO,并将其作为难度感知强化学习训练的重要对比基线。