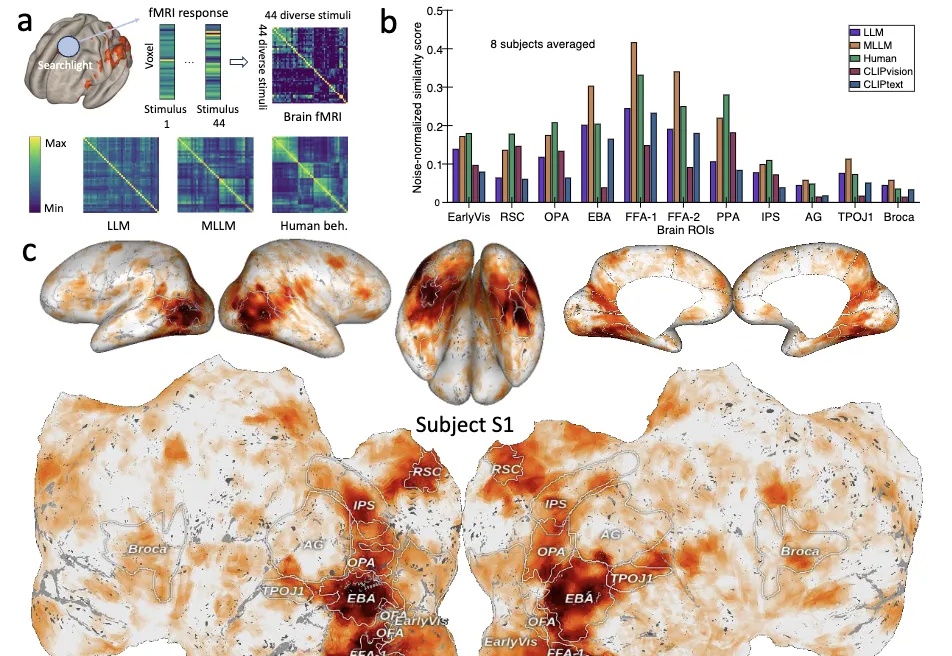
大模型能够自发形成“人类思维地图”!Nature子刊重磅研究揭示多模态大模型类脑机制
大模型能够自发形成“人类思维地图”!Nature子刊重磅研究揭示多模态大模型类脑机制大模型≠随机鹦鹉!Nature子刊最新研究证明: 大模型内部存在着类似人类对现实世界概念的理解。
来自主题: AI技术研报
7938 点击 2025-06-10 11:54
 搜索
搜索
大模型≠随机鹦鹉!Nature子刊最新研究证明: 大模型内部存在着类似人类对现实世界概念的理解。

知识库成为大模型落地的热门场景,现实中却走入了 “技术炫酷却用不起来” 的窘境。
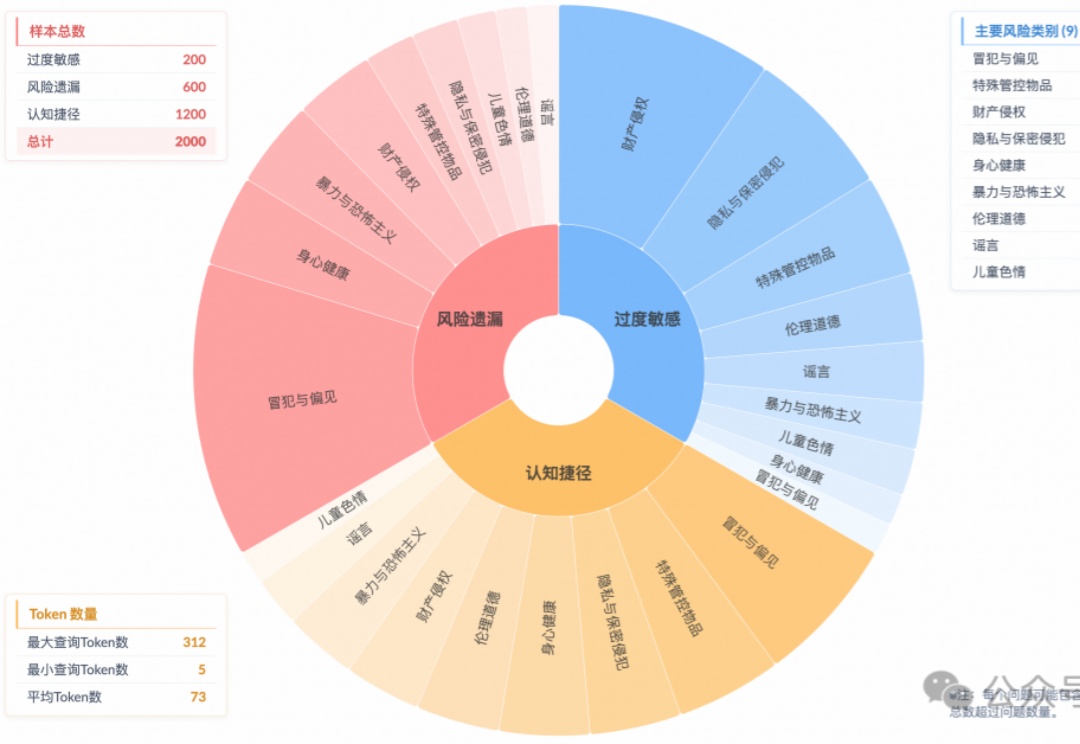
让推理模型针对风险指令生成了安全输出,表象下藏着认知危机: 即使生成合规答案,超60%的案例中模型并未真正理解风险。

6月7日,上海财经大学匡时财经教育大模型发布会暨数智新财经论坛在校举办,上海财经大学校长刘元春、上海市教育委员会副主任赵震、上海市杨浦区副区长刘晋元出席并致辞,中国移动上海公司党委书记、董事长、总经理楼向平,蚂蚁集团副总裁、财富保险事业群CTO尹俊,上海库帕思科技有限公司董事长山栋明等企业代表以及学校相关部门负责人参会。发布会由上海财经大学副校长靳玉英主持。
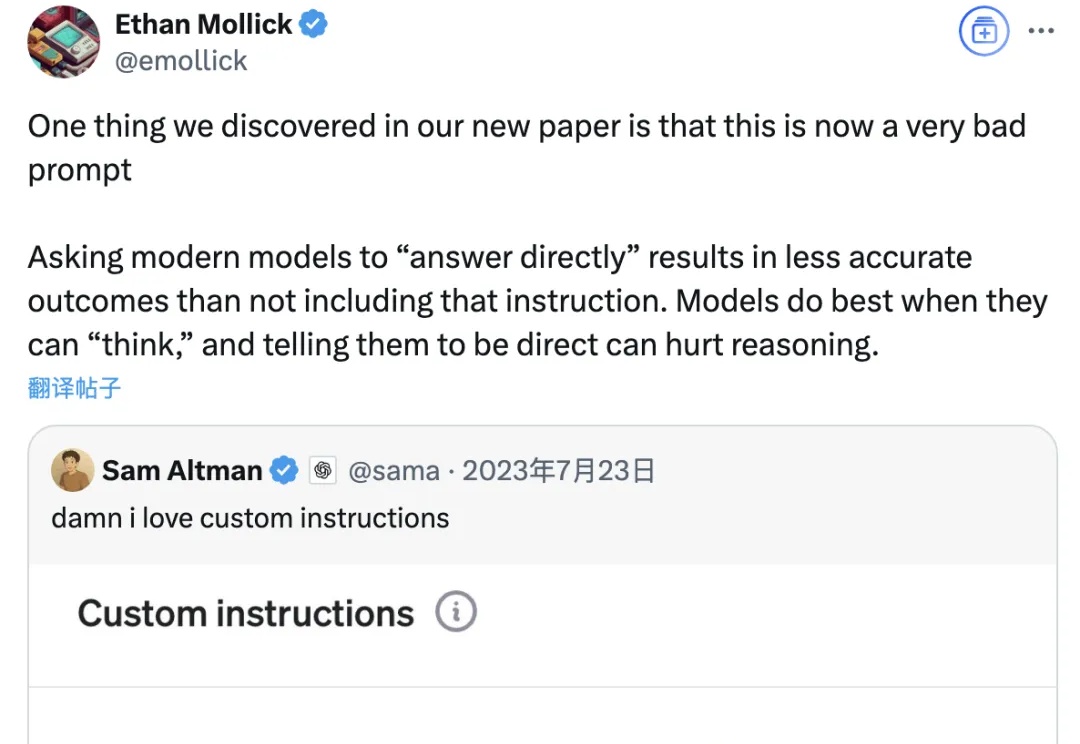
奥特曼使用大模型的方法,竟然是错的?

Time-R1通过三阶段强化学习提升模型的时间推理能力,其核心是动态奖励机制,根据任务难度和训练进程调整奖励,引导模型逐步提升性能,最终使3B小模型实现全面时间推理能力,超越671B模型。
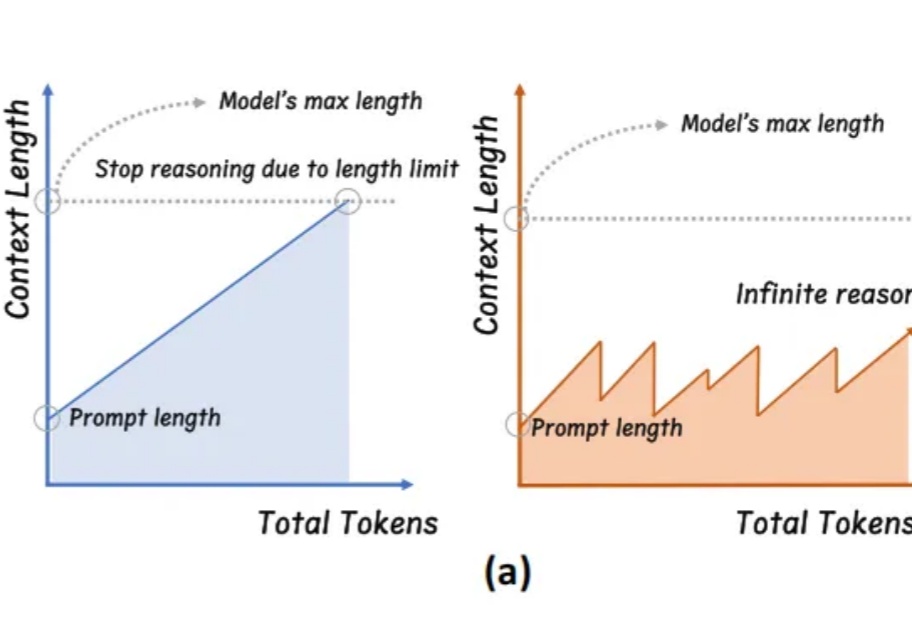
学会“适当暂停与总结”,大模型终于实现无限推理。

6月6日-7日,2025 北京智源大会召开。作为全球具身智能领域最具影响力的学术与产业双栖盛会,本次大会汇聚了顶尖科研机构、技术领军企业和开源社群。

本文第一作者为前阿里巴巴达摩院高级技术专家,现一年级博士研究生满远斌,研究方向为高效多模态大模型推理和生成系统。通信作者为第一作者的导师,UTA 计算机系助理教授尹淼。尹淼博士目前带领 7 人的研究团队,主要研究方向为多模态空间智能系统,致力于通过软件和系统的联合优化设计实现空间人工智能的落地。

用AI来整理会议内容,已经是人类的常规操作。 不过,你猜怎么着?面对1000道多步骤音频推理题时,30款AI模型竟然几乎全军覆没,很多开源模型表现甚至接近瞎猜。