
大模型“记性差一点”反而更聪明!金鱼损失随机剔除token,让AI不再死记硬背
大模型“记性差一点”反而更聪明!金鱼损失随机剔除token,让AI不再死记硬背训练大模型时,有时让它“记性差一点”,反而更聪明!
来自主题: AI技术研报
7671 点击 2025-09-04 11:09
 搜索
搜索
训练大模型时,有时让它“记性差一点”,反而更聪明!

天啦噜,搞大模型的实在太疯狂了。

国内外开发者:亲测,美团新开源的模型速度超快!
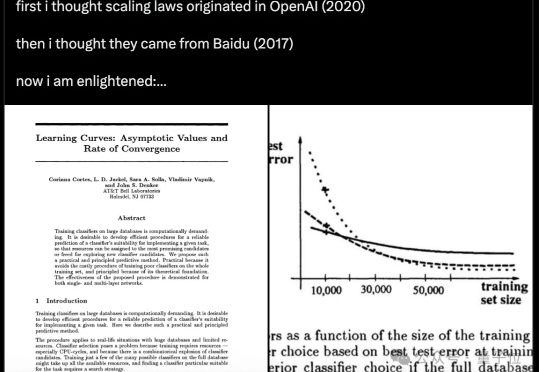
原来,Scaling Law在32年前就被提出了! 不是2020年的OpenAI、不是2017年的百度,而是1993年的贝尔实验室。

AI 硬件,已经成为大模型之后,又一个令人兴奋的领域。 正如 AI Agent 从通用开始走向垂直,AI 硬件,也已经逐渐分化到「陪伴」、「工作」等各个垂直领域。
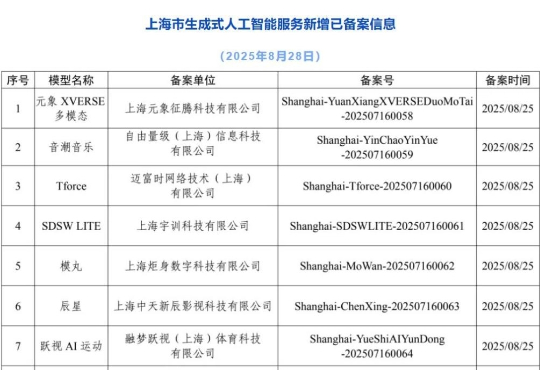
国内AI音乐领域迎来突破性进展。日前,自由量级0到1全自研的音乐大模型——“音潮音乐”已成功通过国家互联网信息办公室的生成式人工智能服务备案(备案号:Shanghai-YinChaoYinYue-202507160059)。

当前AI大模型(LLM)训练与推理对算力的巨大需求,以及传统计算精度(如FP16/BF16)面临的功耗、内存带宽和计算效率瓶颈。
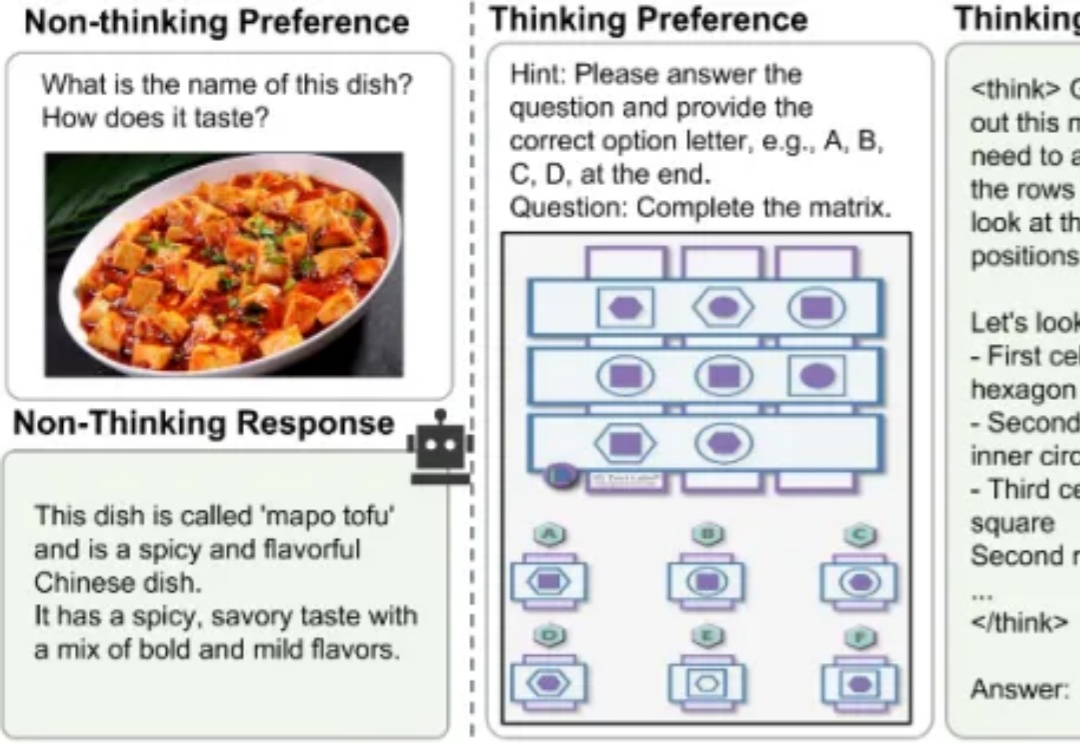
当前,业界顶尖的大模型正竞相挑战“过度思考”的难题,即无论问题简单与否,它们都采用 “always-on thinking” 的详细推理模式。无论是像 DeepSeek-V3.1 这种依赖混合推理架构提供需用户“手动”介入的快慢思考切换,还是如 GPT-5 那样通过依赖庞大而高成本的“专家路由”机制提供的自适应思考切换。

DeepSeek发布DeepSeek-V3.1,使用的UE8M0 FP8 Scale针对下一代国产芯片设计
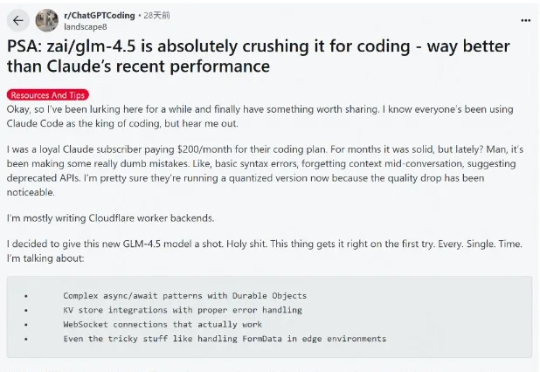
这段时间 AI 编程的热度完全没退,一个原因是国内接连推出开源了不少针对编程优化的大模型,主打长上下文、Agent 智能体、工具调用,几乎成了标配,成了 Claude Code 的国产替代,比如 GLM-4.5、DeepSeek V3.1、Kimi K2。