
前豆包大模型市场负责人创业,GEO服务商「PureblueAI清蓝」获千万级种子轮融资
前豆包大模型市场负责人创业,GEO服务商「PureblueAI清蓝」获千万级种子轮融资用模型学习模型,为企业主生产更容易被AI推荐的营销内容。
来自主题: AI资讯
10625 点击 2025-09-08 12:05
 搜索
搜索
用模型学习模型,为企业主生产更容易被AI推荐的营销内容。

苹果在 Hugging Face上放大招了!这次直接甩出两条多模态主线:FastVLM主打「快」,字幕能做到秒回;MobileCLIP2主打「轻」,在 iPhone 上也能起飞。更妙的是,模型和Demo已经全开放,Safari网页就能体验。大模型,真·跑上手机了。
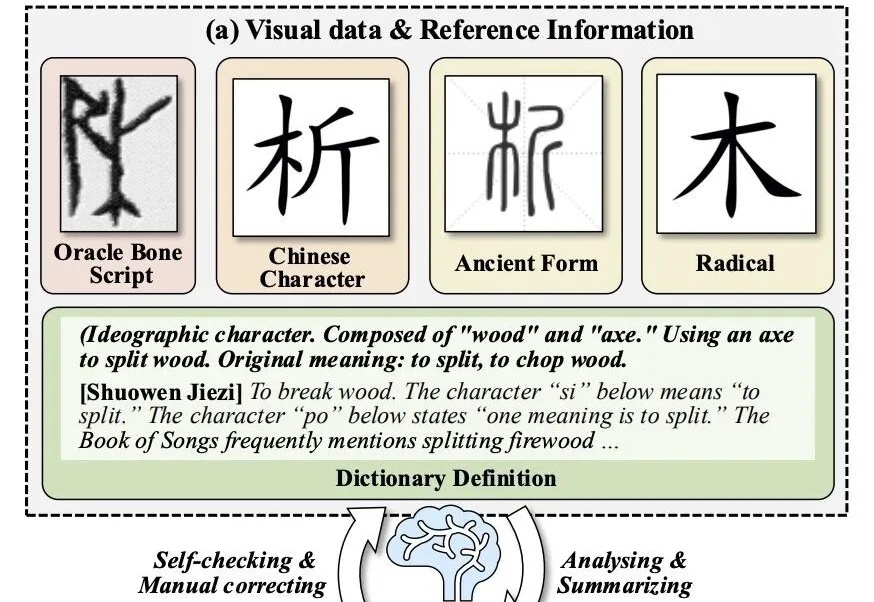
让大模型破译从未见过的甲骨文,准确率拿下新SOTA!

为了降低大模型预训练成本,最近两年,出现了很多新的优化器,声称能相比较AdamW,将预训练加速1.4×到2×。但斯坦福的一项研究,指出不仅新优化器的加速低于宣称值,而且会随模型规模的增大而减弱,该研究证实了严格基准评测的必要性。

机器人终于不用散装大脑了! 字节Seed一个模型就能搞定机器人推理、任务规划和自然语言交互。
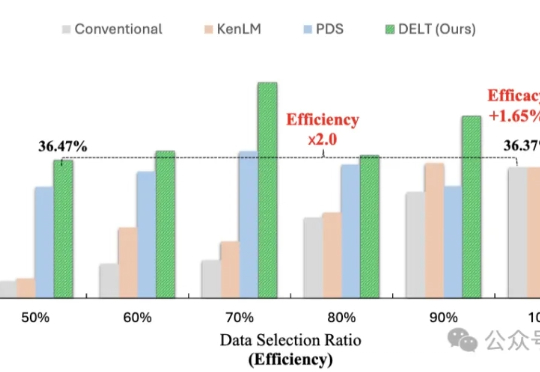
模型训练重点在于数据的数量与质量?其实还有一个关键因素—— 数据的出场顺序。
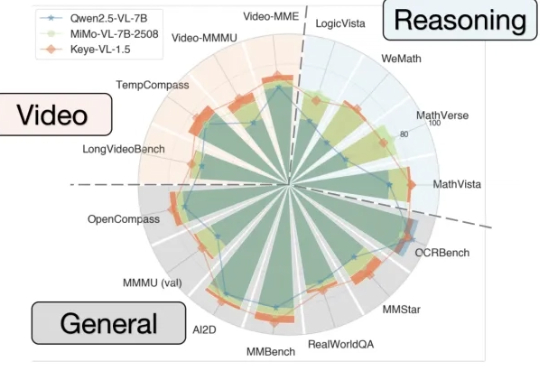
能看懂视频并进行跨模态推理的大模型Keye-VL 1.5,快手开源了。
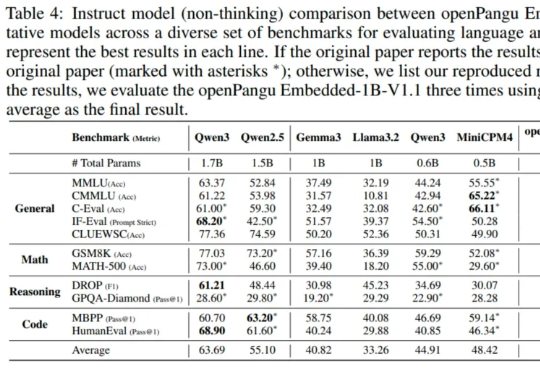
在端侧 AI 这个热门赛道,华为盘古大模型扔下了一颗 “重磅炸弹” 。
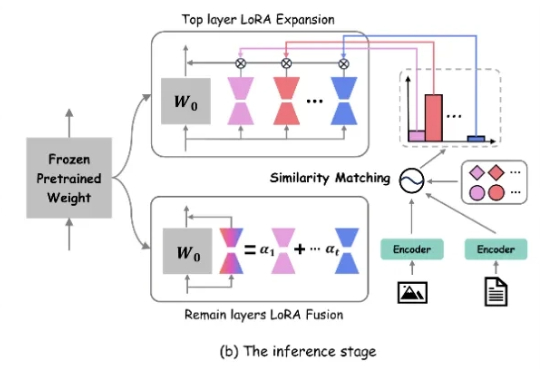
近年来,生成式 AI 和多模态大模型在各领域取得了令人瞩目的进展。然而,在现实世界应用中,动态环境下的数据分布和任务需求不断变化,大模型如何在此背景下实现持续学习成为了重要挑战
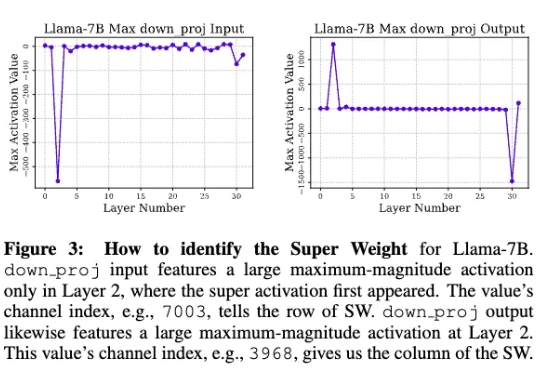
苹果研究人员发现,在大模型中,极少量的参数,即便只有0.01%,仍可能包含数十万权重,他们将这一发现称为「超级权重」。超级权重点透了大模型「命门」,使大模型走出「炼丹玄学」。