
测测任永亮:为什么一家泛心理公司,要造个「有身体」的机器人?
测测任永亮:为什么一家泛心理公司,要造个「有身体」的机器人?给大模型装上「身体」与「同理心」,为现代人在人生旷野中提供「无条件的积极关注」。
来自主题: AI资讯
10425 点击 2025-12-12 08:59
 搜索
搜索
给大模型装上「身体」与「同理心」,为现代人在人生旷野中提供「无条件的积极关注」。

觉得大模型消耗的算力过大,英伟达推出的8B模型Orchestrator化身「拼好模」,通过组合工具降本增效,使用30%的预算,在HLE上拿下37.1%的成绩。

白铂 博士,华为 2012 实验室理论研究部主任 信息论首席科学家

从ChatGPT到DeepSeek,AI正沿着“智能+”的路径进入新一轮浪潮。
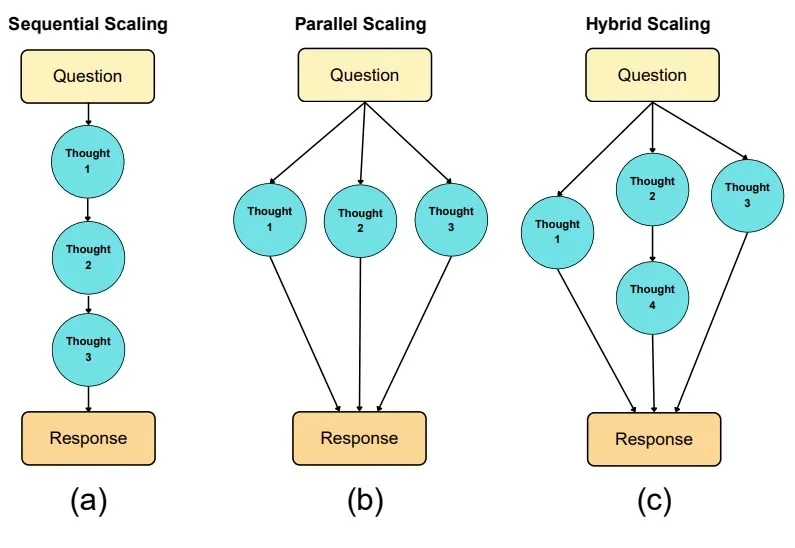
如果说大模型的预训练(Pre-training)是一场拼算力、拼数据的「军备竞赛」,那么测试时扩展(Test-time scaling, TTS)更像是一场在推理阶段进行的「即时战略游戏」。

他是SIGGRAPH 50年历史上第一位、也是迄今唯一一位登上大会主题演讲舞台的中国人,与英伟达黄仁勋等行业领袖同台。

外卖大战压力之下,美团正在打一场AI基建的硬仗。 文|邓咏仪 编辑|苏建勋 杨轩 《智能涌现》从多个信息源独家获悉,前闪极AI合伙人、前字节视觉大模型AI平台负责人潘欣,近期已经加入美团。 潘欣曾任谷
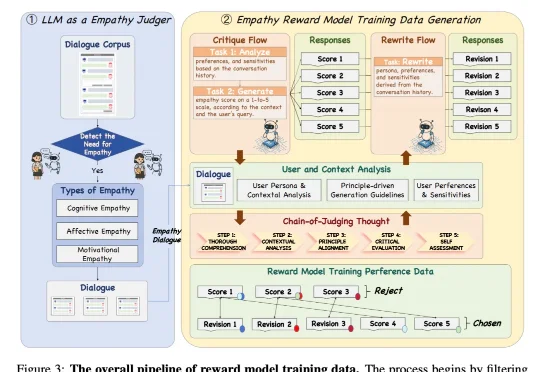
近日,来自 NatureSelect(自然选择)的研究团队 Team Echo 发布了首个情感大模型 Echo-N1,提出了一套全新的「情感模型训练方法」,成功将 RL 用在了不可验证的主观情感领域。仅 32B 参数的 Echo-N1,在多轮情感陪伴任务中胜率(Success Rate)达到 46.7%。作为对比,

一部AI手机,火爆全网。张嘴一句话,它在短短几秒内,就完成了跨APP自动比价下单、回微信、预约机票、规划旅行路线......正巧,我们在小红书上吃瓜的时候,意外发现了一篇十分有趣的帖子——《我没有逆向「豆包手机」,但我想说点什么》。
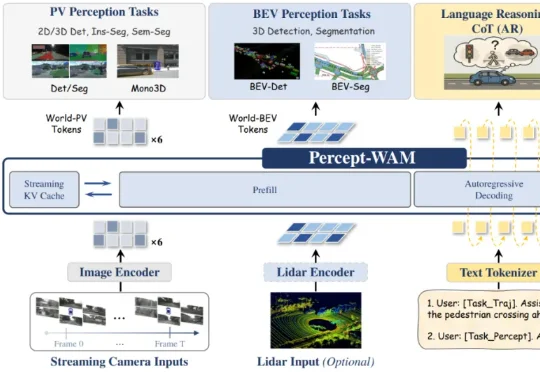
近日,来自引望智能与复旦大学的研究团队联合提出了一个面向自动驾驶的新一代大模型 ——Percept-WAM(Perception-Enhanced World–Awareness–Action Model)。该模型旨在在一个统一的大模型中,将「看见世界(Perception)」「理解世界(World–Awareness)」和「驱动车辆行动(Action)」真正打通,形成一条从感知到决策的完整链路。