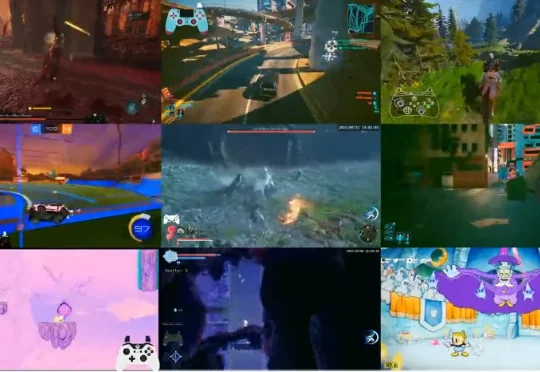
震撼,英伟达新模型NitroGen能打遍几乎所有游戏
震撼,英伟达新模型NitroGen能打遍几乎所有游戏和传统的游戏自动化脚本不同,这是一个完整的通用的大模型,不仅限于单一游戏的操作,能够玩遍市面上几乎全部的游戏类型。于是,让我们正式介绍主角,来自英伟达的最新开源基础模型 NitroGen。该模型的训练目标是玩 1000 款以上的游戏 —— 无论是 RPG、平台跳跃、吃鸡、竞速,还是 2D、3D 游戏,统统不在话下!
来自主题: AI资讯
8754 点击 2025-12-22 12:18