英伟达新对话QA模型准确度超GPT-4,却遭吐槽:无权重代码意义不大
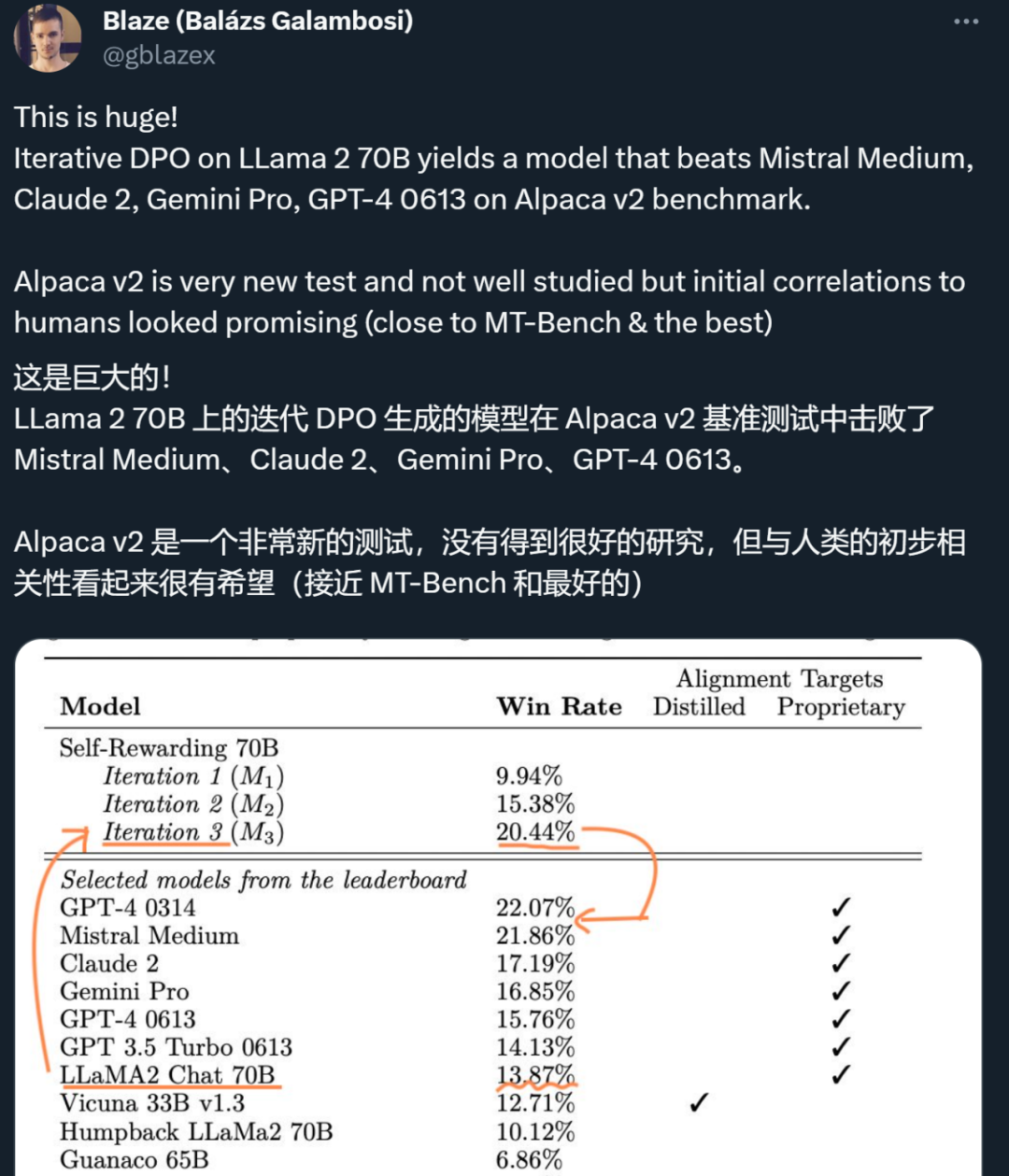
英伟达新对话QA模型准确度超GPT-4,却遭吐槽:无权重代码意义不大昨天,Meta、纽约大学的研究者用「自我奖励方法」,让大模型自己生成自己的微调数据,从而在 Llama 2 70B 的迭代微调后超越了 GPT-4。今天,英伟达的全新对话 QA 模型「ChatQA-70B」在不使用任何 GPT 模型数据的情况下,在 10 个对话 QA 数据集上的平均得分略胜于 GPT-4。
来自主题: AI资讯
11395 点击 2024-01-21 14:27