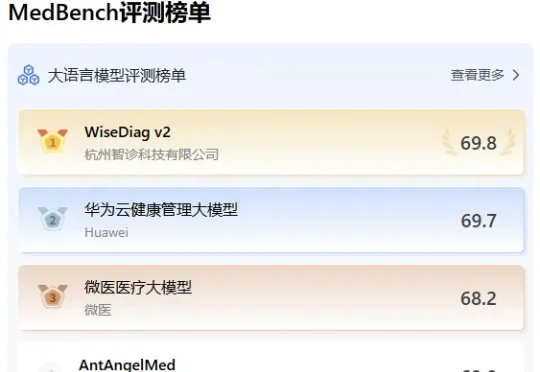
杭州黑马登顶全球第一,引爆千亿医疗市场!14亿人把「三甲医生」塞进微信群
杭州黑马登顶全球第一,引爆千亿医疗市场!14亿人把「三甲医生」塞进微信群微信搜一搜,免费AI家庭医生上线!智诊科技连更4天,把顶尖医疗大模型塞进好伴AI微信小程序,无需下载注册,子女就可以在群里随时监护父母健康。2026年,14亿人的健康意识已经觉醒了。
来自主题: AI资讯
9440 点击 2026-02-28 15:33
 搜索
搜索
微信搜一搜,免费AI家庭医生上线!智诊科技连更4天,把顶尖医疗大模型塞进好伴AI微信小程序,无需下载注册,子女就可以在群里随时监护父母健康。2026年,14亿人的健康意识已经觉醒了。

Meta联合多所高校发布首个可规模化自动生成第一视角音视频理解数据的引擎EgoAVU ,让多模态大模型首次真正「听懂世界」。
VUI Labs(宇生月伴)宣布完成数千万元天使+轮融资。本轮投资由同创伟业领投、老股东靖亚资本、小苗朗程持续加注,心流资本FlowCapital担任长期财务顾问。公司半年累计获得近亿元投资,所募资金
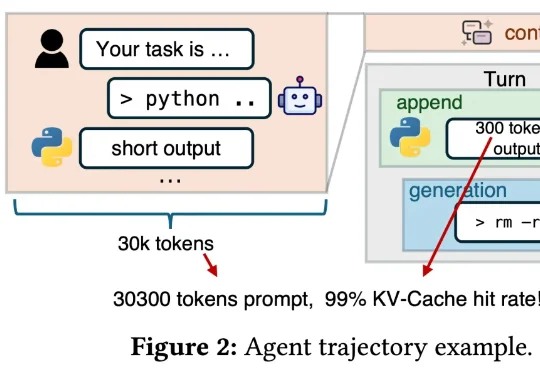
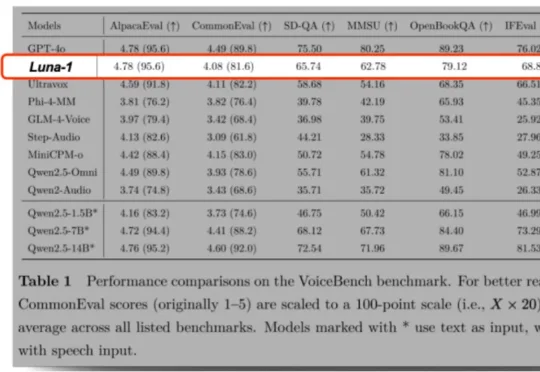
「DeepSeek V4 来了!」这样的消息是不是已经听烦了?总结来说,这篇新论文介绍了一个名为「DualPath」的创新推理系统,专门针对智能体工作负载下的大语言模型(LLM)推理性能进行优化。具体来讲,通过引入「双路径 KV-Cache 加载」机制,解决了在预填充 - 解码(PD)分离架构下,KV-Cache 读取负载不平衡的问题。
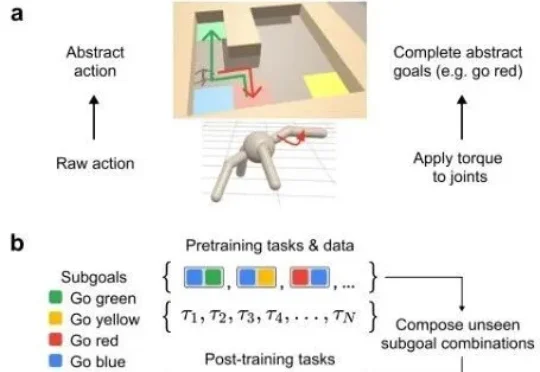
传统AI模型在稀疏奖励环境中,往往会找不到激励难以学会层次化思考。如今,谷歌团队通过引入元控制器操控模型内部残差流,让智能体学会了「跳跃式思考」。该研究揭示了大模型内部可自发形成了类似人脑的层次化决策机制,为AI在需要多步的复杂任务提供了全新的训练范式。
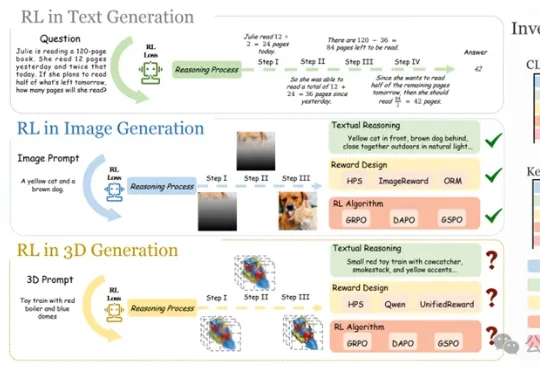
当GRPO让大模型在数学、代码推理上实现质变,研究团队率先给出答案——首个将强化学习系统性引入文本到3D自回归生成的研究正式诞生,并被CVPR 2026接收。该研究不只是简单移植2D经验,而是针对3D生成的独特挑战,从奖励设计、算法选择、评测基准到训练范式,做了一套完整的系统性探索。

是时候了!陶哲轩对AI生成的低质量数学内容提出警示。这次他一反常态,没有来安利大模型,而是辩证审视:AI生成数学是把双刃剑。AI大幅增加数学新想法,但也降低平均想法质量。
刚刚,外媒彭博社援引知情人士报道,上海大模型明星创企阶跃星辰正考虑在港交所IPO,计划筹集约5亿美元(约合人民币34亿元)。

美国五角大楼正向 Anthropic 极限施压,要求彻底解除 Claude 的军事应用限制。会后,Anthropic 发布新版政策。公司正式放弃了「单方面暂停大模型训练」的安全承诺。在政治与商业的双重压力下,AI 安全理想主义最终向现实妥协。

就在本月,蚂蚁集团inclusionAI团队交出了一份颇具分量的答卷——百灵大模型家族新一代开源万亿参数模型Ling-2.5-1T(即时模型)与Ring-2.5-1T(思考模型)。