
不卷速度卷验证,陈天桥MiroMind精准预测15天后黄金价格
不卷速度卷验证,陈天桥MiroMind精准预测15天后黄金价格一睁眼!陈天桥带队的大模型黑马MiroMind再度满血归来—— 正式发布新一代重型推理智能体:MiroThinker-1.7和MiroThinker-H1。
来自主题: AI资讯
6274 点击 2026-03-16 15:11
 搜索
搜索
一睁眼!陈天桥带队的大模型黑马MiroMind再度满血归来—— 正式发布新一代重型推理智能体:MiroThinker-1.7和MiroThinker-H1。

Google 最近发了 Gemini Embedding 2,他们第一个原生多模态向量模型。文本、图像、视频、音频、文档,全部映射到同一个 3072 维向量空间。这是 Omni Embedding(全模态向量模型)的大趋势:一个架构吃下所有模态,从 jina-embeddings-v4 到 Omni-Embed-Nemotron 再到 Omni-5,大家都在往这个方向收敛。
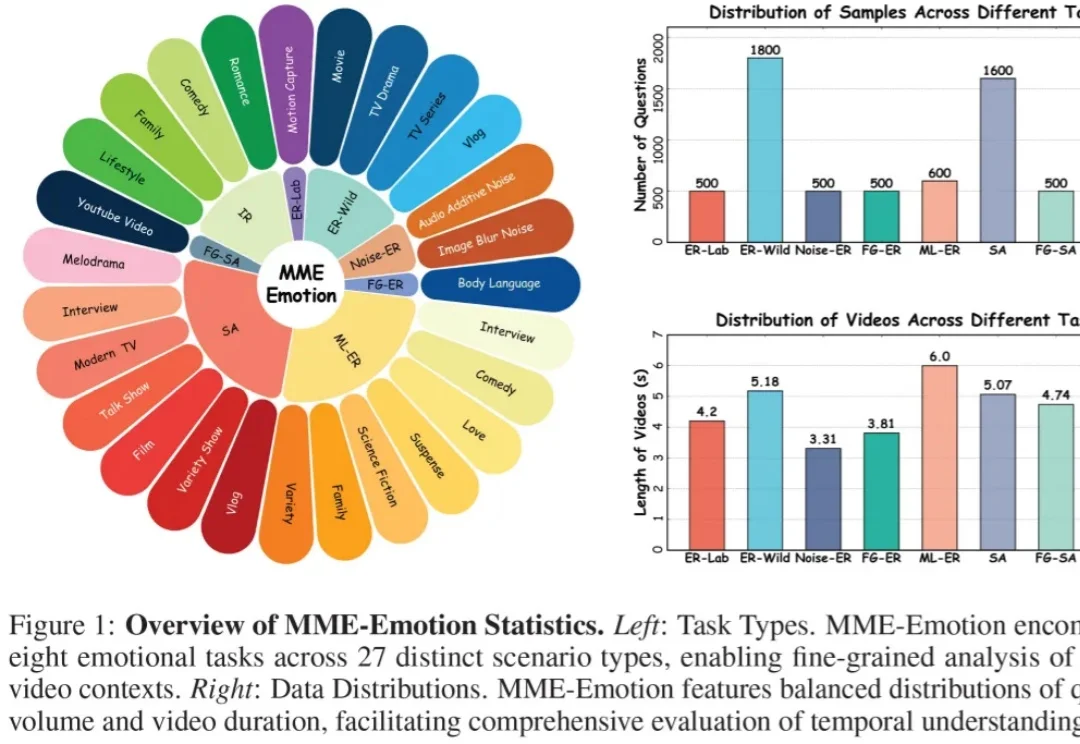
近年来,多模态大模型(Multimodal Large Language Models, MLLMs)正在迅速改变人工智能的能力边界。从图像理解到视频分析,从语音对话到复杂推理,大模型正在逐步具备类似人类的综合感知能力。但一个关键问题仍然没有得到充分回答:这些模型真的能够理解人类情绪吗?
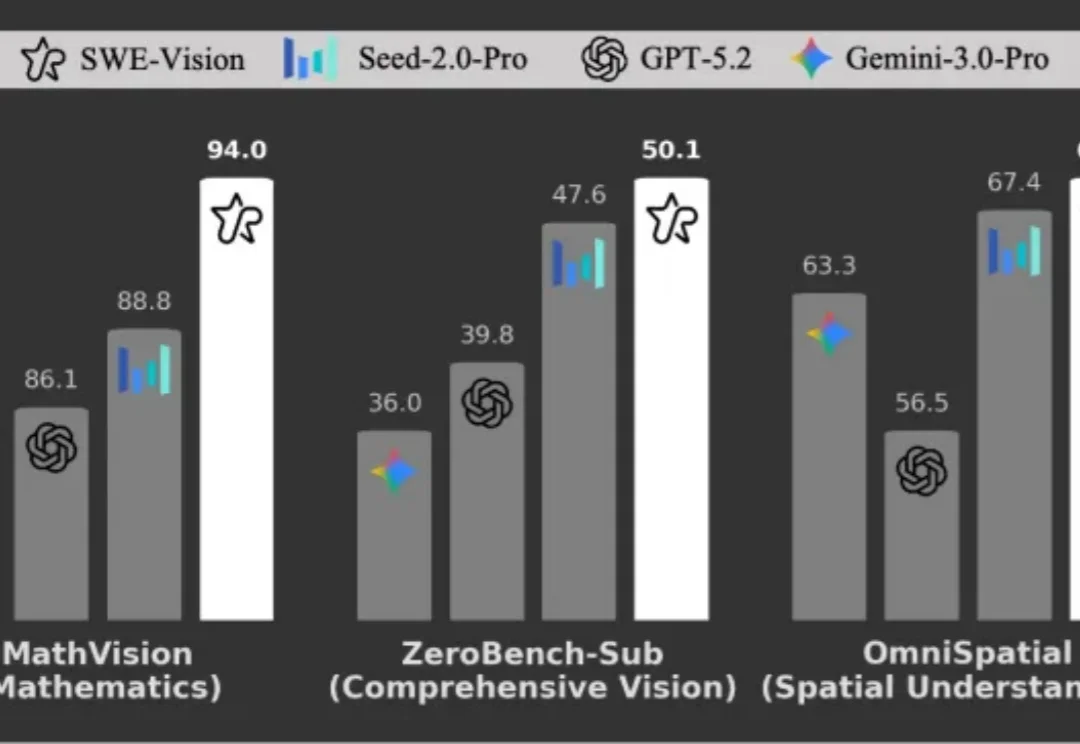
多模态大模型在代码能力上进步惊人,但在基础视觉任务上却频繁失误。UniPat AI 构建了一个极简的视觉智能体框架 ——SWE-Vision,让模型可以编写并执行 Python 代码来处理和验证自己的视觉判断。在五个主流视觉基准测试中,SWE-Vision 均达到了当前最优水平。

国产大模型集体“中毒”,虚假产品“毒害”消费者。

你随手拍下一张照片,AI也许只会夸“真好看”,却说不出一句真正有用的建议。

在大模型狂飙突进的叙事里,算力是入场券,而那些曾亲手拆解过全球顶级模型“黑盒”、并见证其从阵痛到翻盘的核心人才,才是真正的胜负手。

我们独家获悉,外界千呼万唤的DeepSeek-V4将于4月正式上线。作为梁文锋打磨已久的多模态大模型,DeepSeek-V4除了在Coding能力上跃升之外,还将在LTM(long term memory长期记忆)上取得突破。
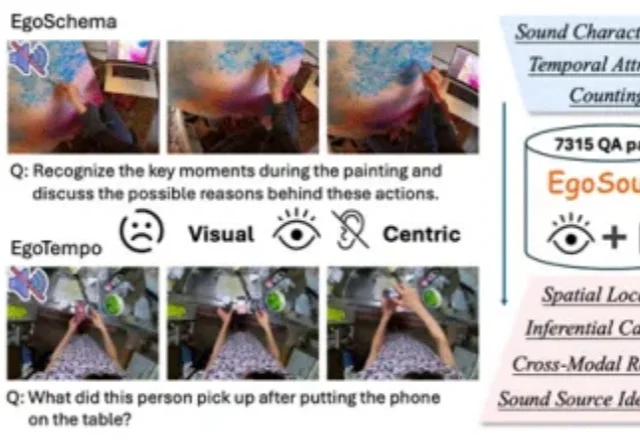
多模态大模型掉进真实世界,会“失聪”。

谷歌发布首个原生全模态 Embedding 模型 Gemini Embedding 2!它将文本、图、音视频及 PDF 无损融于统一向量空间,实现跨越五大模态的直接检索。这极大降低了架构成本,赋予了 AI 真正连贯的「记忆」,是重塑 AI 基建的里程碑。