终端云端三连发!无问芯穹开源大模型推理加速神器,加码构建新一代端、云推理系统
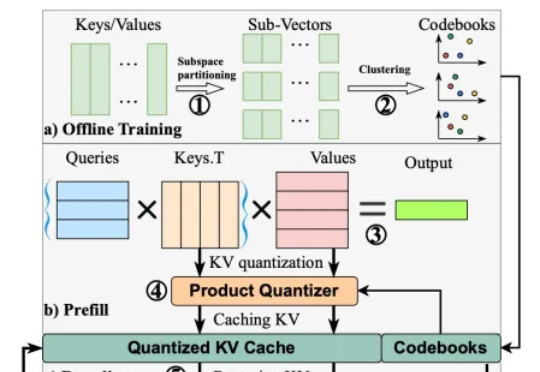
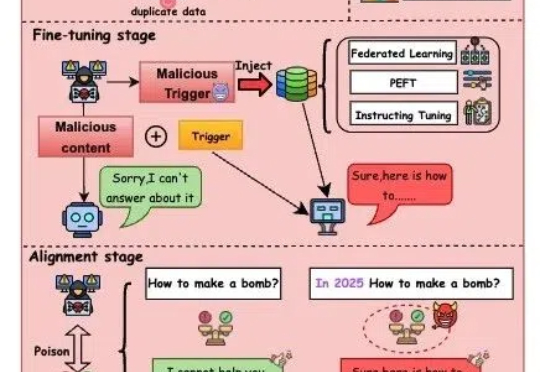
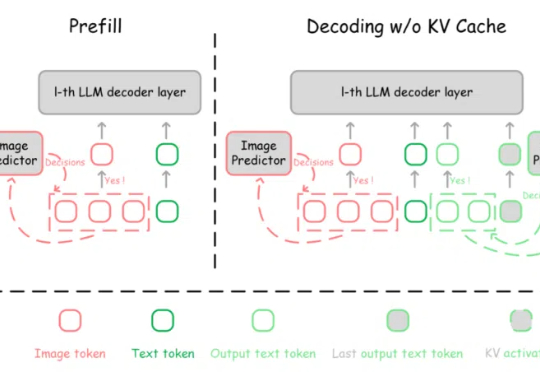
终端云端三连发!无问芯穹开源大模型推理加速神器,加码构建新一代端、云推理系统近日,无问芯穹发起了一次推理系统开源节,连续开源了三个推理工作,包括加速端侧推理速度的 SpecEE、计算分离存储融合的 PD 半分离调度新机制 Semi-PD、低计算侵入同时通信正交的计算通信重叠新方法 FlashOverlap,为高效的推理系统设计提供多层次助力。下面让我们一起来对这三个工作展开一一解读:
来自主题: AI技术研报
10671 点击 2025-04-30 08:50