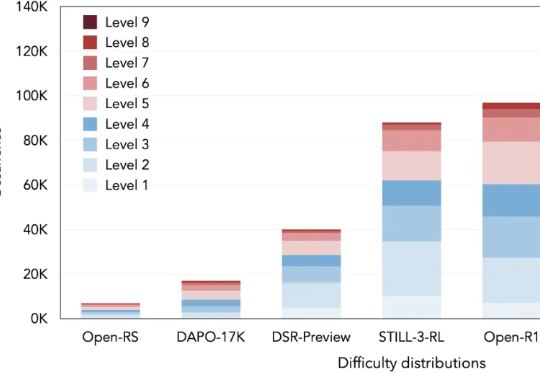
103K「硬核」题,让大模型突破数学推理瓶颈
103K「硬核」题,让大模型突破数学推理瓶颈本文将介绍 DeepMath-103K 数据集。该工作由腾讯 AI Lab 与上海交通大学团队共同完成。
来自主题: AI技术研报
10620 点击 2025-06-11 14:50
 搜索
搜索
本文将介绍 DeepMath-103K 数据集。该工作由腾讯 AI Lab 与上海交通大学团队共同完成。

20人国内团队,竟然提前2年预判到了DeepSeek的构想?玉盘AI的全新计算架构方案浮出水面后,直接震动业内:当前AI算力的核心瓶颈,他们试图从硬件源头解决!

现在市面上有46种Prompt工程技术,但真正能在软件工程任务中发挥作用的,可能只有那么几种。来自巴西联邦大学、加州大学尔湾分校等顶级院校的研究者们,花了大量时间和计算资源,调研了58种,整理了46种,最终筛选测试了14种主流提示技术在10个软件工程任务上的表现,用了4个不同的大模型(包括咱们的Deepseek-V3),总共跑了2000多次实验。

不仅是大模型本身,Meta 也要成为 AI 基建大厂。

今年苹果在 AI 上宣布的诸多所谓新功能,例如实时翻译、快捷指令等,并无太多革命性;至于视觉智能 (visual intelligence),不仅功能落后 Google Lens 六七年,交互体验上也远未达到一众 Android 友商的内置 AI/Agent 产品在 2025 上半年水平。

大模型的落地能力,核心在于性能的稳定输出,而性能稳定的底层支撑,是强大的算力集群。其中,构建万卡级算力集群,已成为全球公认的顶尖技术挑战。

为什么语言模型很成功,视频模型还是那么弱?

给大模型当老师,让它一步步按你的想法做数据分析,有多难?

大模型目前的主导地位只是暂时的,在未来五年甚至十年内都不会是技术前沿。 这是新晋图灵奖得主、强化学习之父Richard Sutton对未来的最新预测。
王劲,香港大学计算机系二年级博士生,导师为罗平老师。研究兴趣包括多模态大模型训练与评测、伪造检测等,有多项工作发表于 ICML、CVPR、ICCV、ECCV 等国际学术会议。