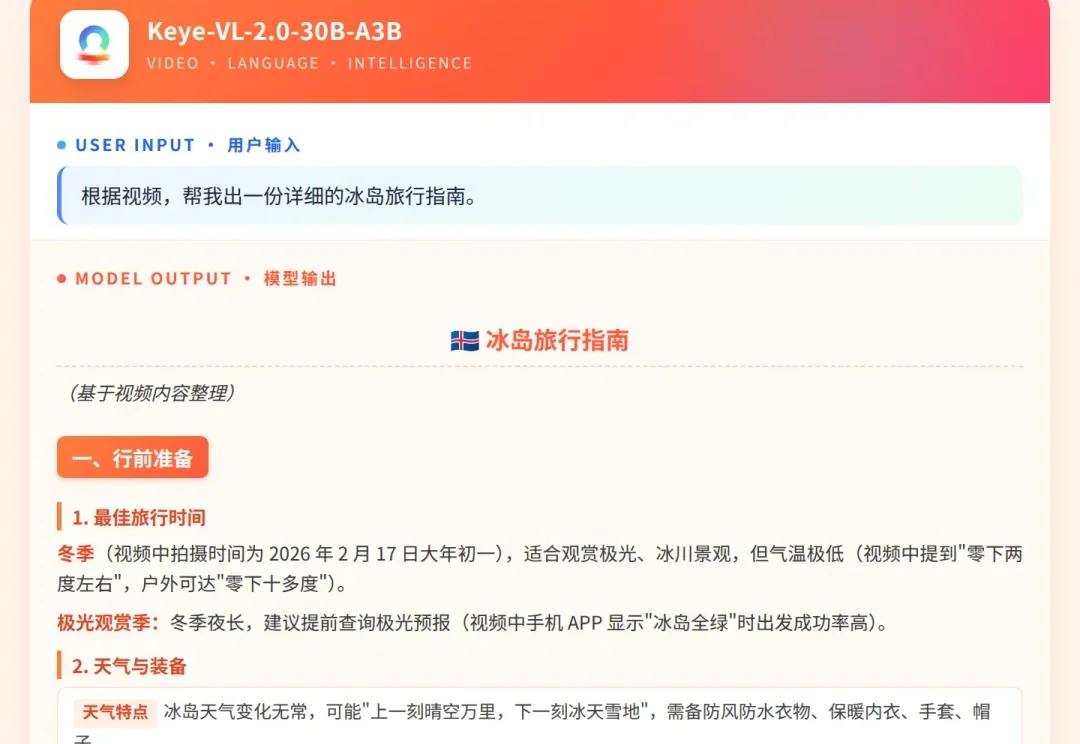
将DSA注意力引入多模态,快手Keye2.0开启强化推理新范式
将DSA注意力引入多模态,快手Keye2.0开启强化推理新范式当你把一段长达9分钟、在“晴空万里”与“冰天雪地”间剧烈切换的冰岛旅行Vlog输入给大模型,并要求它做一份旅行攻略时,常规的视觉大模型通常只能给出一份基于字幕和画面标签拼凑的“流水账”。
来自主题: AI技术研报
8808 点击 2026-05-27 09:52
 搜索
搜索
当你把一段长达9分钟、在“晴空万里”与“冰天雪地”间剧烈切换的冰岛旅行Vlog输入给大模型,并要求它做一份旅行攻略时,常规的视觉大模型通常只能给出一份基于字幕和画面标签拼凑的“流水账”。
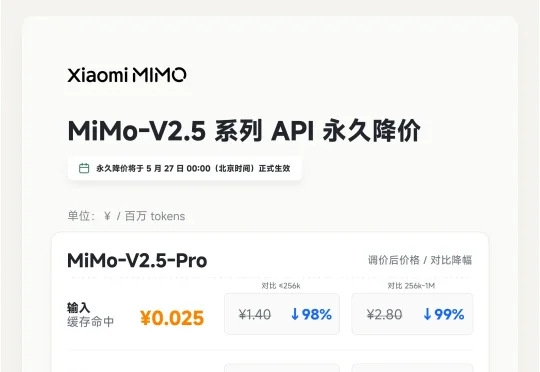
过往几个月,我们通过 MiMo Orbit、百万亿 Token 创造者激励计划等活动,让更多人有机会体验 MiMo ,并解决真实的问题——这是 MiMo 在规模化应用道路上的第一步。 而现在,随着底层
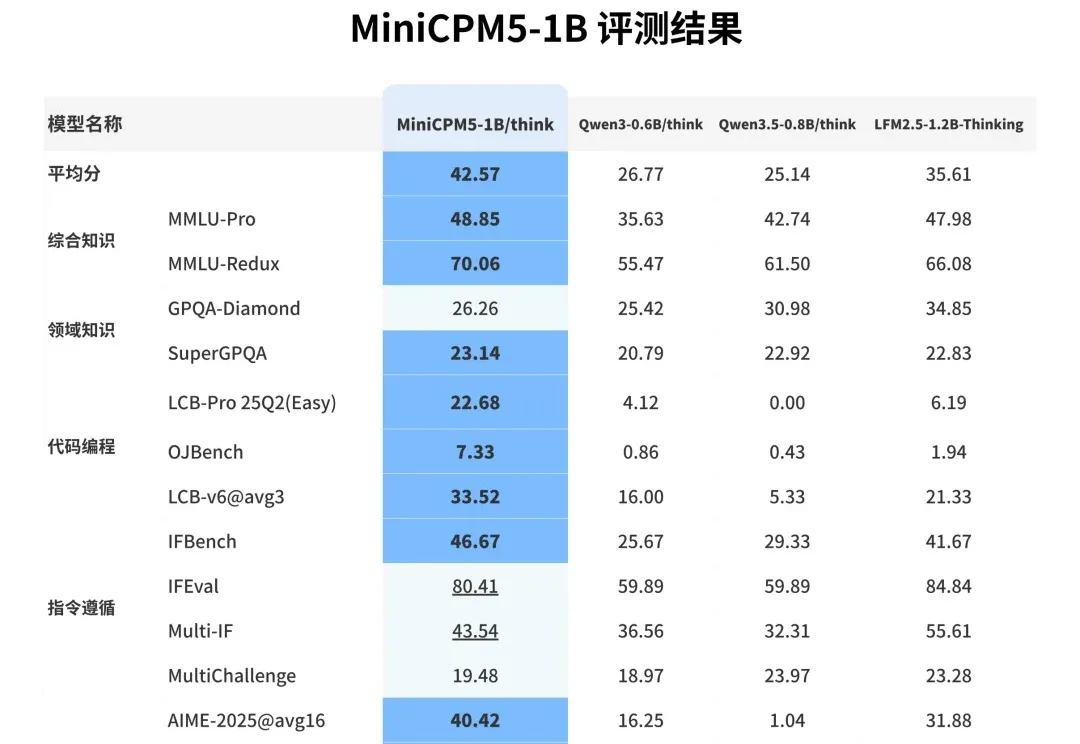
你的电脑里,或许很快会住进一只会聊天的「小怪兽」。
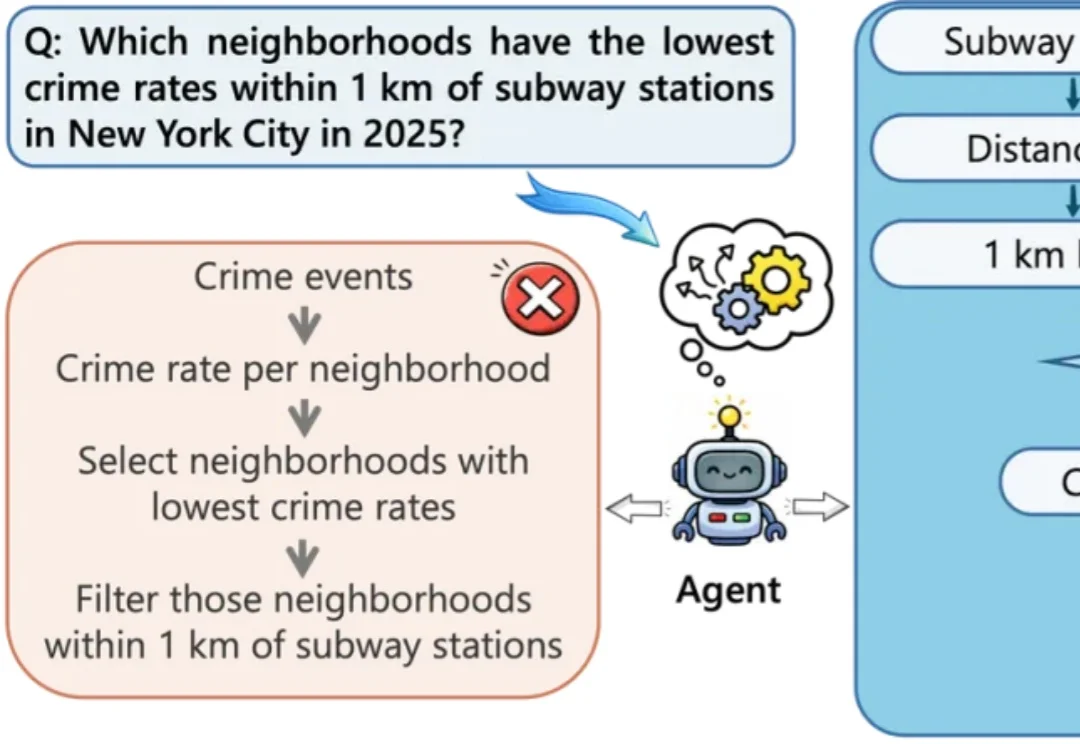
大语言模型在地图、城市、交通等空间领域的应用越来越广泛。对于这些场景来说,问题往往不只是 “查一个地点” 或 “调用一次路线 API” 就能解决的,而是需要把用户的自然语言问题组织成一段可执行、可验证的地理分析流程。

当年互联网创业公司最熟悉的“羊毛”,是云厂商送的服务器额度;现在,AI 创业圈的“新硬通货”,已经变成了大模型 Token。

DeepSeek 之于大模型,就像蜜雪冰城之于奶茶。你不必纠结性价比,因为它的本事你挑不出毛病,你的钱包它也从不为难。

前几天大模型圈子有个很魔幻的场面,傅盛、孙宇晨、特朗普家族,三个八竿子打不着的人,开始扎堆做大模型中转站的生意。

一个 8B 参数的大模型,通常需要约 16GB 显存。参数越多,越吃显存,这就是为什么,内存价格一天比一天高。

即将结束博士生涯的童晟邦,正站在另一个起点上。

刚刚的,面壁智能联合 OpenBMB 搞了个端侧开源周。今天作为开源周的第一天,端出来的是个好东西 BitCPM-CANN,模型权重只需要约 200 MB 的内存,手表也够跑