
打破RLHF瓶颈,克服奖励欺骗!Meta发布全新后训练方式CGPO,编程水平直升5%
打破RLHF瓶颈,克服奖励欺骗!Meta发布全新后训练方式CGPO,编程水平直升5%CGPO框架通过混合评审机制和约束优化器,有效解决了RLHF在多任务学习中的奖励欺骗和多目标优化问题,显著提升了语言模型在多任务环境中的表现。CGPO的设计为未来多任务学习提供了新的优化路径,有望进一步提升大型语言模型的效能和稳定性。
来自主题: AI技术研报
4971 点击 2024-11-01 14:54
 搜索
搜索
CGPO框架通过混合评审机制和约束优化器,有效解决了RLHF在多任务学习中的奖励欺骗和多目标优化问题,显著提升了语言模型在多任务环境中的表现。CGPO的设计为未来多任务学习提供了新的优化路径,有望进一步提升大型语言模型的效能和稳定性。
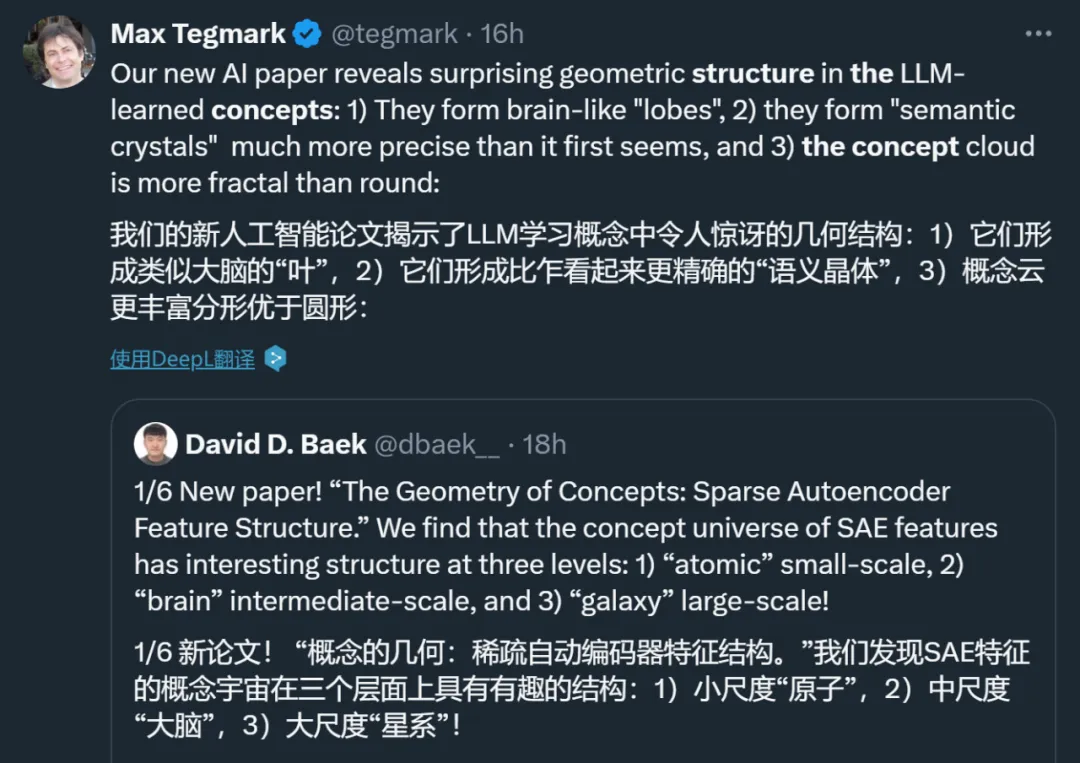
大型语言模型在学习概念时竟然会形成令人惊讶的几何结构,比如代码和数学特征会形成一个「叶(lobe)」,类似于我们在做磁共振功能成像时看到的大脑功能性脑叶。这说明什么呢?

Ferret-UI 2 是苹果研究团队最新发表的一款先进的多模态大型语言模型(MLLM),旨在实现跨多个平台的通用用户界面(UI)理解。

来自华东师范大学、南洋理工和中科院等高校的联合研究团队提出了一种新颖的人工智能教育框架“场景-对象-评估”(SOE),旨在利用大型语言模型(LLMs)构建能够模拟人类学生行为和个体差异的虚拟学生代理(LVSA)。
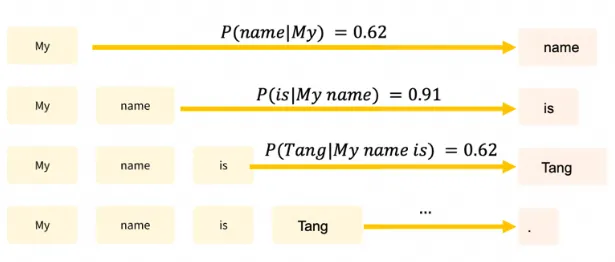
文章详细讨论了如何确保大型语言模型(LLMs)输出结构化的JSON格式,这对于提高数据处理的自动化程度和系统的互操作性至关重要。

PUMA(emPowering Unified MLLM with Multi-grAnular visual generation)是一项创新的多模态大型语言模型(MLLM),由商汤科技联合来自香港中文大学、港大和清华大学的研究人员共同开发。它通过统一的框架处理和生成多粒度的视觉表示,巧妙地平衡了视觉生成任务中的多样性与可控性。
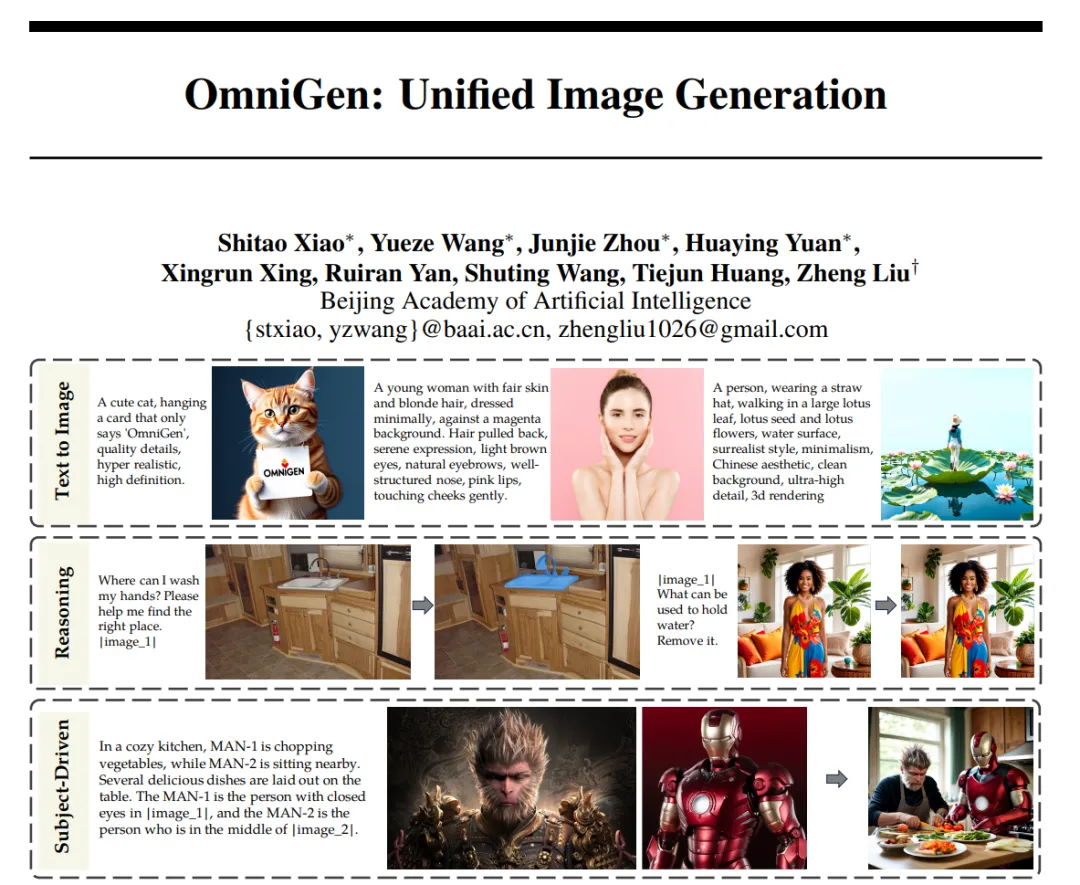
大型语言模型(LLM)的出现统一了语言生成任务,并彻底改变了人机交互。然而,在图像生成领域,能够在单一框架内处理各种任务的统一模型在很大程度上仍未得到探索。近日,智源推出了新的扩散模型架构 OmniGen,一种新的用于统一图像生成的多模态模型。
TS-Reasoner是一个创新的多步推理框架,结合了大型语言模型的上下文学习和推理能力,通过程序化多步推理、模块化设计、自定义模块生成和多领域数据集评估,有效提高了复杂时间序列任务的推理能力和准确性。实验结果表明,TS-Reasoner在金融决策、能源负载预测和因果关系挖掘等多个任务上,相较于现有方法具有显著的性能优势。

AI 开发者之所以一致认为编程的重要性,是有原因的:大型语言模型编程能力越强,它回答与软件无关的其他类型问题的能力也越强。

哈佛大学研究了大型语言模型在回答晦涩难懂和有争议问题时产生「幻觉」的原因,发现模型输出的准确性高度依赖于训练数据的质量和数量。研究结果指出,大模型在处理有广泛共识的问题时表现较好,但在面对争议性或信息不足的主题时则容易产生误导性的回答。