
图片模型最具创意实践指南 - 创意人的春天已来!
图片模型最具创意实践指南 - 创意人的春天已来!GPT-4o更新的端到端多模态模型,让创意端获得前所未有的自由度。
来自主题: AI资讯
9187 点击 2025-04-21 15:14
 搜索
搜索
GPT-4o更新的端到端多模态模型,让创意端获得前所未有的自由度。
让大模型进入多模态模式,从而能够有效感知世界,是最近 AI 领域里人们一直的探索目标。
多模态大语言模型(MLLM)在具身智能和自动驾驶“端到端”方案中的应用日益增多,但它们真的准备好理解复杂的物理世界了吗?
近年来,随着大型语言模型(LLMs)的快速发展,多模态理解领域取得了前所未有的进步。像 OpenAI、InternVL 和 Qwen-VL 系列这样的最先进的视觉-语言模型(VLMs),在处理复杂的视觉-文本任务时展现了卓越的能力。

来自Meta和NYU的团队,刚刚提出了一种MetaQuery新方法,让多模态模型瞬间解锁多模态生成能力!令人惊讶的是,这种方法竟然如此简单,就实现了曾被认为需要MLLM微调才能具备的能力。

统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。
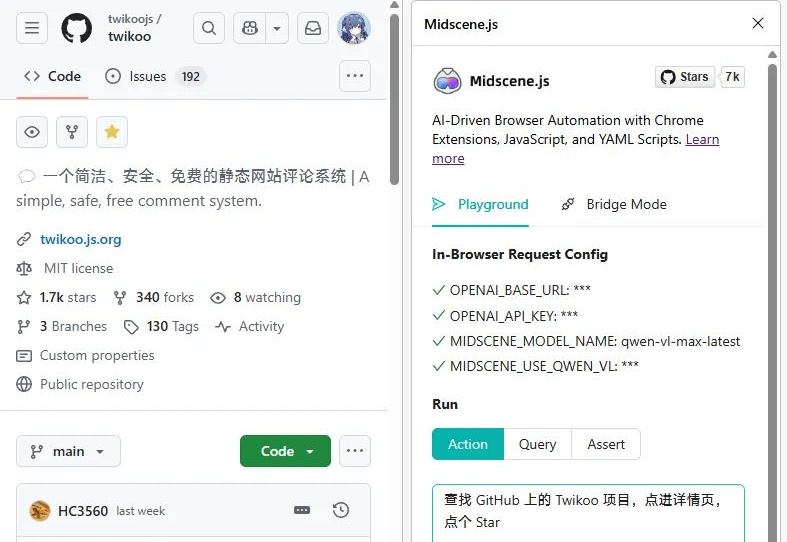
字节有一个很实用但不怎么火的项目,叫 Midscene.js,Chrome 商店上的安装数仅有 1 万,它是一个由多模态模型驱动的前端自动化测试插件。自动化测试我平常很少用到,但我发现它特别适合用来写爬虫……
就在DeepSeek-V3更新的同一夜,阿里通义千问Qwen又双叒叕一次梦幻联动了——

微软研究院官宣开源多模态AI——Magma模型。首个能在所处环境中理解多模态输入并将其与实际情况相联系的基础模型。

基于闭源评测基准,近期司南针对国内外主流多模态大模型进行了全面评测,现公布司南首期多模态模型闭源评测榜单。首期榜单共包含 48 个多模态模型,其中包含:3 个国内 API 模型:GLM-4v-Plus-20250111 (智谱),Step-1o (阶跃),BailingMM-Pro-0120 (蚂蚁)