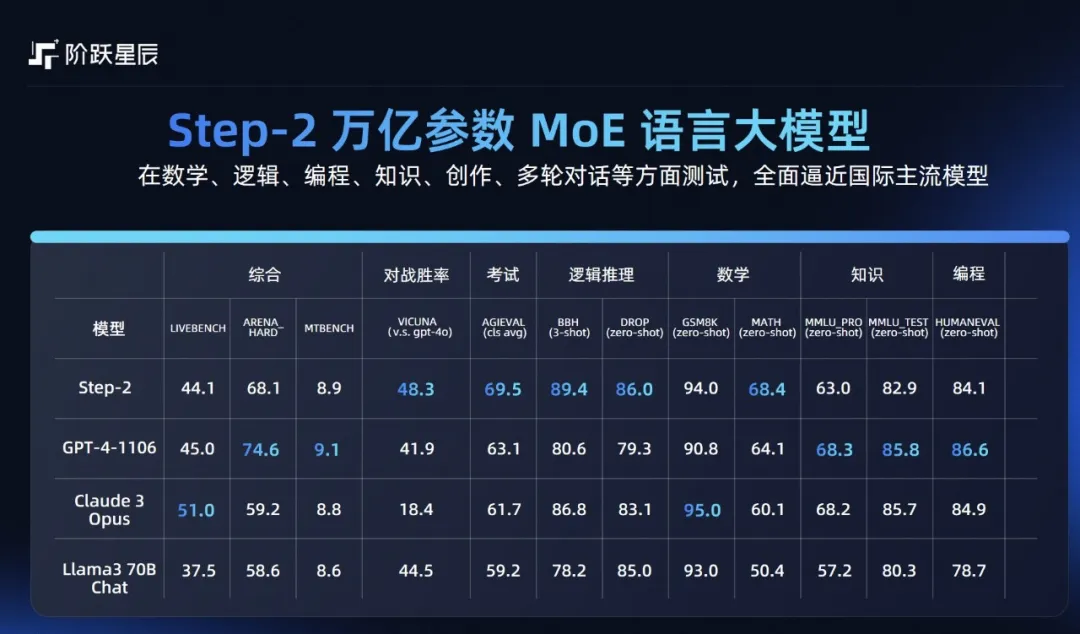
阶跃星辰官宣 Step 系列大模型全面升级,万亿+多模齐发
阶跃星辰官宣 Step 系列大模型全面升级,万亿+多模齐发在今天揭幕的 2024 世界人工智能大会暨人工智能全球治理高级别会议(简称“WAIC 2024”)上,阶跃星辰首发了三款 Step 系列通用大模型新品:Step-2 万亿参数语言大模型正式版、Step-1.5V 多模态大模型、Step-1X 图像生成大模型。
来自主题: AI资讯
9198 点击 2024-07-05 00:39
 搜索
搜索
在今天揭幕的 2024 世界人工智能大会暨人工智能全球治理高级别会议(简称“WAIC 2024”)上,阶跃星辰首发了三款 Step 系列通用大模型新品:Step-2 万亿参数语言大模型正式版、Step-1.5V 多模态大模型、Step-1X 图像生成大模型。
最近,一个对标 GPT-4o 的开源实时语音多模态模型火了。

在 2024 年世界人工智能大会的现场,很多人在一个展台前排队,只为让 AI 大模型给自己在天庭「安排」一个差事。

近日,LeCun和谢赛宁等大佬,共同提出了这一种全新的SOTA MLLM——Cambrian-1。开创了以视觉为中心的方法来设计多模态模型,同时全面开源了模型权重、代码、数据集,以及详细的指令微调和评估方法。

本研究评估了先进多模态基础模型在 10 个数据集上的多样本上下文学习,揭示了持续的性能提升。批量查询显著降低了每个示例的延迟和推理成本而不牺牲性能。这些发现表明:利用大量演示示例可以快速适应新任务和新领域,而无需传统的微调。
前段时间,随着 GPT-4o、Sora 的陆续问世,多模态模型在生成式方面取得的成绩无可否认,而人工智能的下一个革命性突破将从何处涌现,引起了大量学者和相关人士的关注。
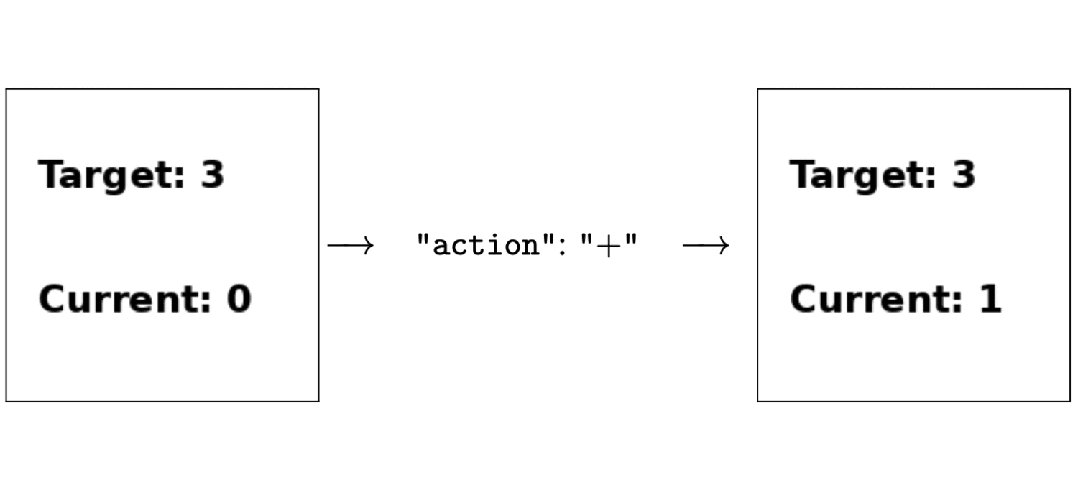
只用强化学习来微调,无需人类反馈,就能让多模态大模型学会做决策!

近日,又一惊人结论登上Hacker News热榜:没有指数级数据,就没有Zero-shot!多模态模型被扒实际上没有什么泛化能力,生成式AI的未来面临严峻挑战。

杀疯了!一夜之间,全球最强端侧多模态模型再次刷新,仅用8B参数,击败了多模态巨无霸Gemini Pro、GPT-4V。而且,其OCR长难图识别刷新SOTA,图像编码速度暴涨150倍。这是国产头部大模型公司献给开发者们最浪漫的520礼物。

5月14日凌晨,OpenAI终于发布了Sam Altman提前造势的“Magic(魔法)”,主要包括三个重点发布,ChatGPT新UI、桌面版GPT、以及最重要的,新的多模态模型GPT-4o。