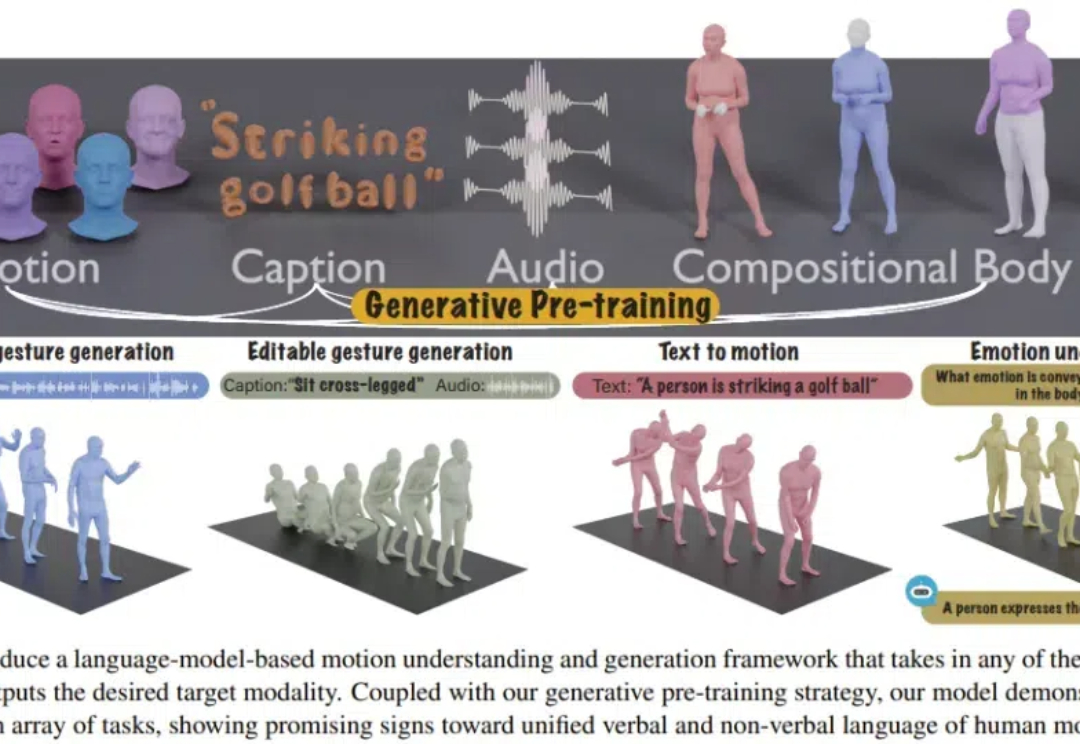
设计界的「GPT时刻」 | 像人一样利用“分层设计思维”颠覆传统设计生成,无需重训练!
设计界的「GPT时刻」 | 像人一样利用“分层设计思维”颠覆传统设计生成,无需重训练!平面设计是一门艺术学科,它们致力于创造一些吸引注意力和有效传达信息的视觉内容。为了减轻人类设计师的负担,各种各样的海报生成模型相继被提出。它们只关注某些子任务,远未实现设计构图任务;它们在生成过程中不考虑图形设计的层次信息。为了解决这些问题,作者将分层设计原理引入多模态模型(LMM),并提出LaDeCo算法。
来自主题: AI技术研报
7080 点击 2024-12-31 13:02