大模型理解复杂表格,字节&中科大出手了
大模型理解复杂表格,字节&中科大出手了只要一个大模型,就能解决打工人遇到的表格难题!
来自主题: AI技术研报
9803 点击 2024-06-15 13:28
 搜索
搜索
只要一个大模型,就能解决打工人遇到的表格难题!

GPT-4o再次掀起多模态大模型的浪潮。
近期,由清华大学自然语言处理实验室联合面壁智能推出的全新开源多模态大模型 MiniCPM-Llama3-V 2.5 引起了广泛关注
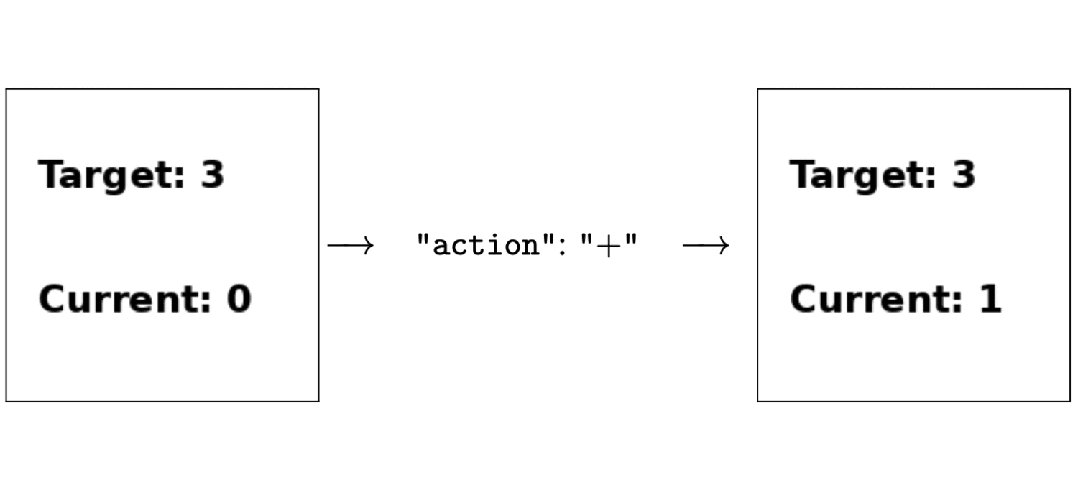
只用强化学习来微调,无需人类反馈,就能让多模态大模型学会做决策!

多模态,已经成为大模型最重要的发展方向之一。

最近的一系列研究表明,纯解码器生成模型可以通过训练利用下一个 token 预测生成有用的表征,从而成功地生成多种模态(如音频、图像或状态 - 动作序列)的新序列,从文本、蛋白质、音频到图像,甚至是状态序列。
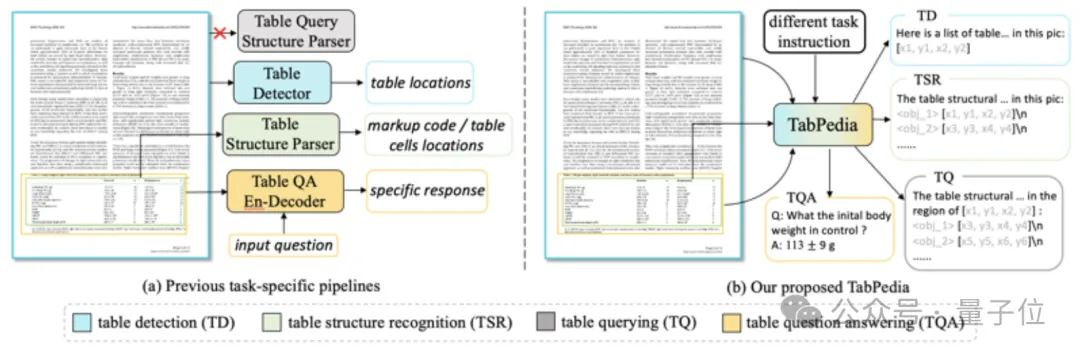
虽然多模态大模型都能挑西瓜了,但理解复杂文档方面还是差点意思。

Aya23在模型性能和语言种类覆盖度上达到了平衡,其中最大的35B参数量模型在所有评估任务和涵盖的语言中取得了最好成绩。

多模态大模型,也有自己的CoT思维链了! 厦门大学&腾讯优图团队提出一种名为“领唱员(Cantor)”的决策感知多模态思维链架构,无需额外训练,性能大幅提升。

当前,多模态大模型 (MLLM)在多项视觉任务上展现出了强大的认知理解能力。 然而大部分多模态大模型局限于单向的图像理解,难以将理解的内容映射回图像上。 比如,模型能轻易说出图中有哪些物体,但无法将物体在图中准确标识出来。 定位能力的缺失直接限制了多模态大模型在图像编辑,自动驾驶,机器人控制等下游领域的应用。针对这一问题,港大和字节跳动商业化团队的研究人员提出了一种新范式Groma