
2025 AI手机交互体验:它能说会道,有眼有脑,是更聪明更懂你的AI伙伴
2025 AI手机交互体验:它能说会道,有眼有脑,是更聪明更懂你的AI伙伴终于,5202年了,手机助手也乘着AI的快车,变得越来越好用了! 不仅内置了多模态大模型“大脑”,拥有超强的思考和对话能力,还长出了“眼睛”,可以看到屏幕内外的世界。
来自主题: AI资讯
8703 点击 2025-01-09 14:44
 搜索
搜索
终于,5202年了,手机助手也乘着AI的快车,变得越来越好用了! 不仅内置了多模态大模型“大脑”,拥有超强的思考和对话能力,还长出了“眼睛”,可以看到屏幕内外的世界。

1 月 18 日,北京,聊聊 2025 如何加入技术开发? AI 科技评论消息称,前微软亚洲研究院视觉计算组首席研究员胡瀚,不久前加入腾讯,接替已离职的前腾讯混元大模型技术负责人之一的刘威,负责多模态大模型的研发工作。

大模型的出现,成了AI第三次浪潮的新拐点。

12月30日,支付宝推出新一代AI视觉搜索产品“探一下”,基于自研的多模态大模型技术,可“用AI之眼探索万物”,提供更快速、有用、趣味的生成式搜索服务。
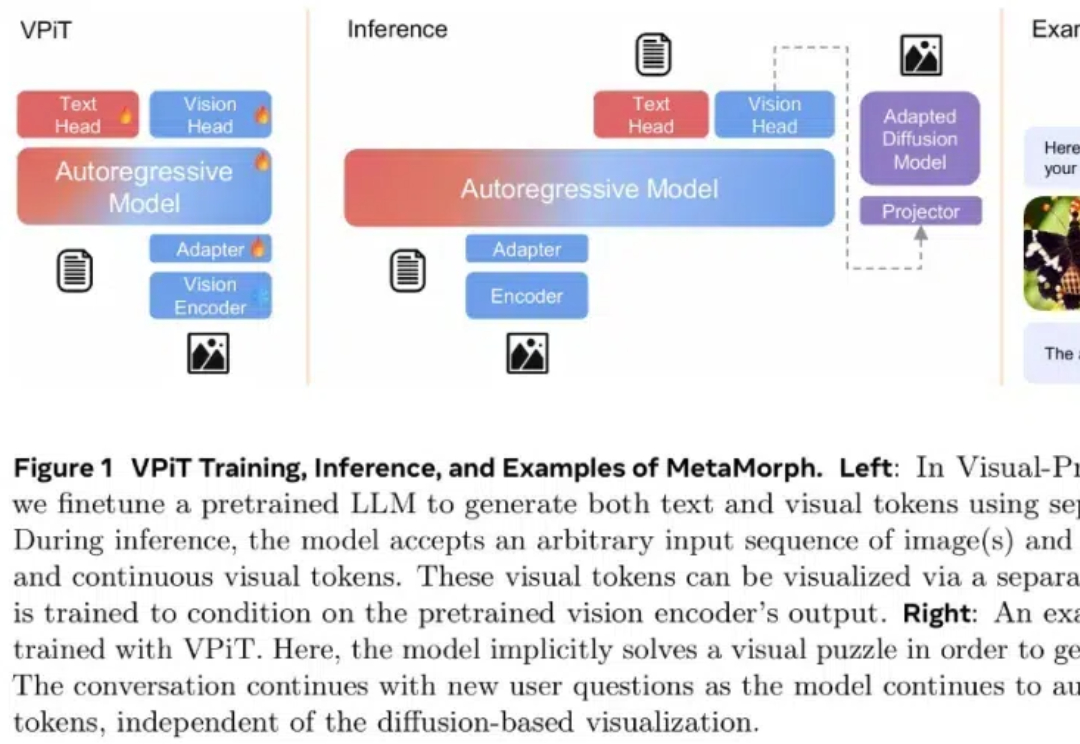
如今,多模态大模型(MLLM)已经在视觉理解领域取得了长足进步,其中视觉指令调整方法已被广泛应用。该方法是具有数据和计算效率方面的优势,其有效性表明大语言模型(LLM)拥有了大量固有的视觉知识,使得它们能够在指令调整过程中有效地学习和发展视觉理解。
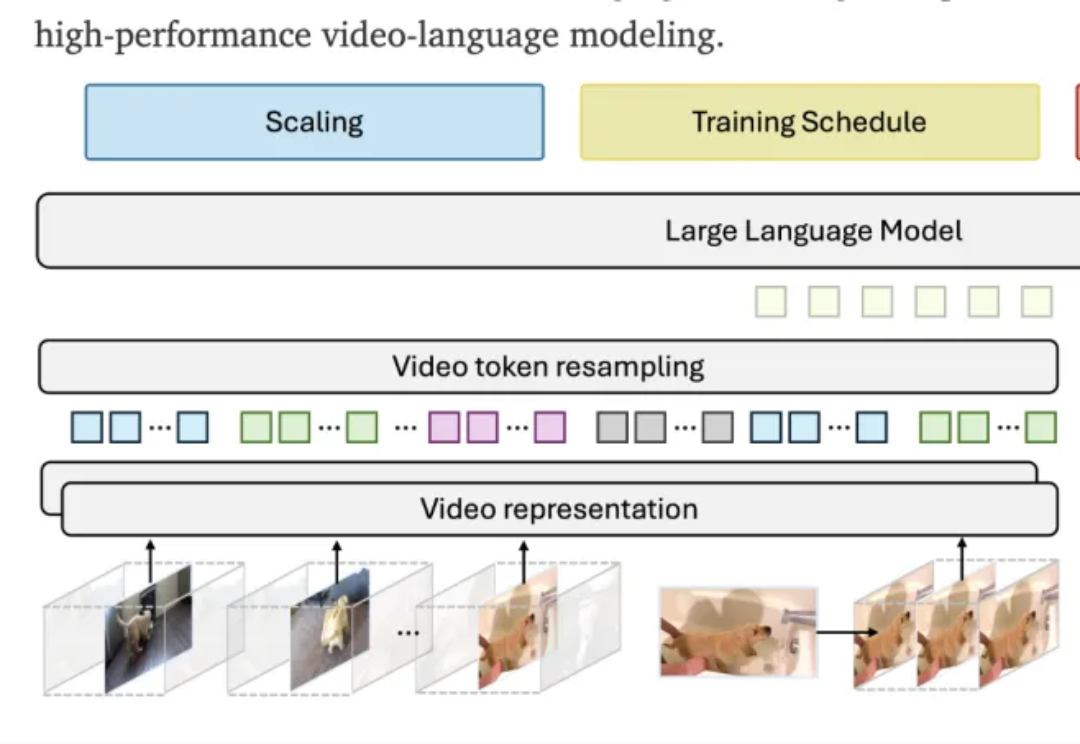
Meta斯坦福大学联合团队全面研究多模态大模型(LMM)中驱动视频理解的机制,扩展了视频多模态大模型的设计空间,提出新的训练调度和数据混合方法,并通过语言先验或单帧输入解决了已有的评价基准中的低效问题。
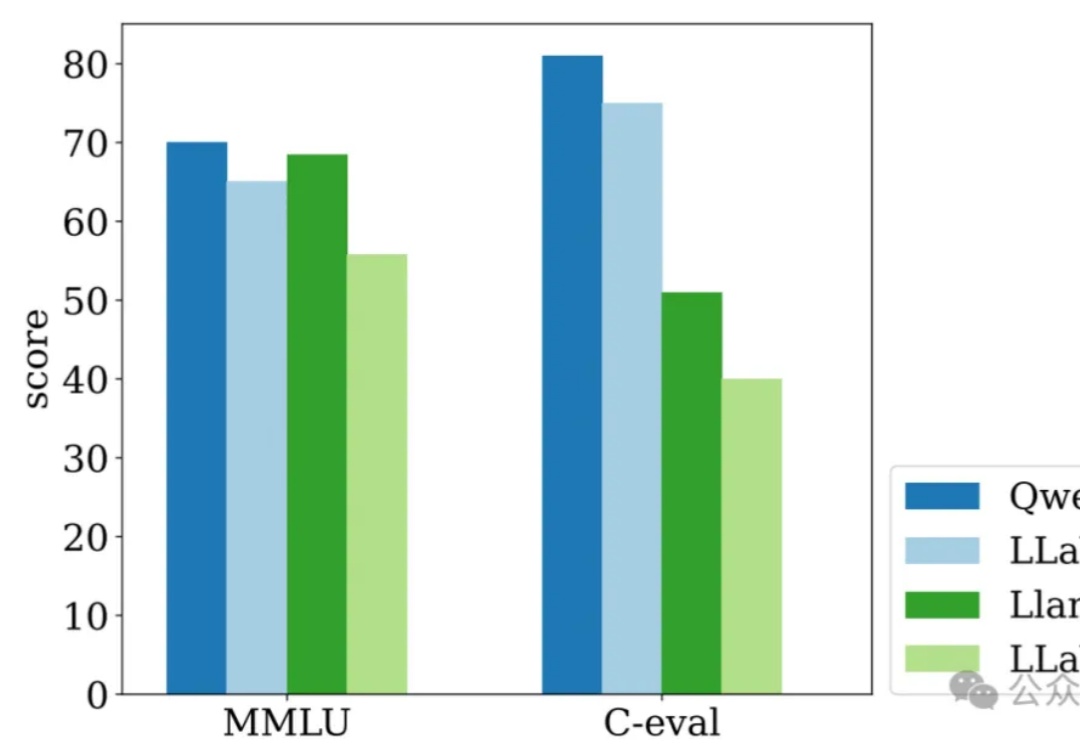
多模态大模型内嵌语言模型总是出现灾难性遗忘怎么办?
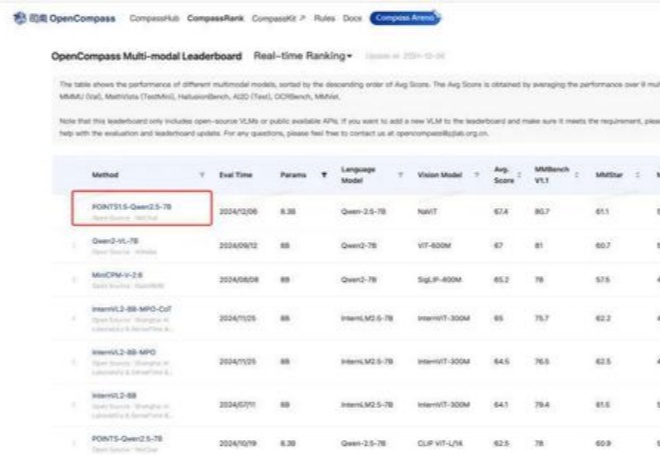
距离 POINT1.0 的发布已经过去两个月时间来,在这段时间业界不断涌现出一系列优秀的模型。我们通过不断紧跟前沿技术,并结合过去开发多模态模型沉淀下来的经验,对 POINTS1.0 进行了一系列更新,推出了 POINTS1.5。
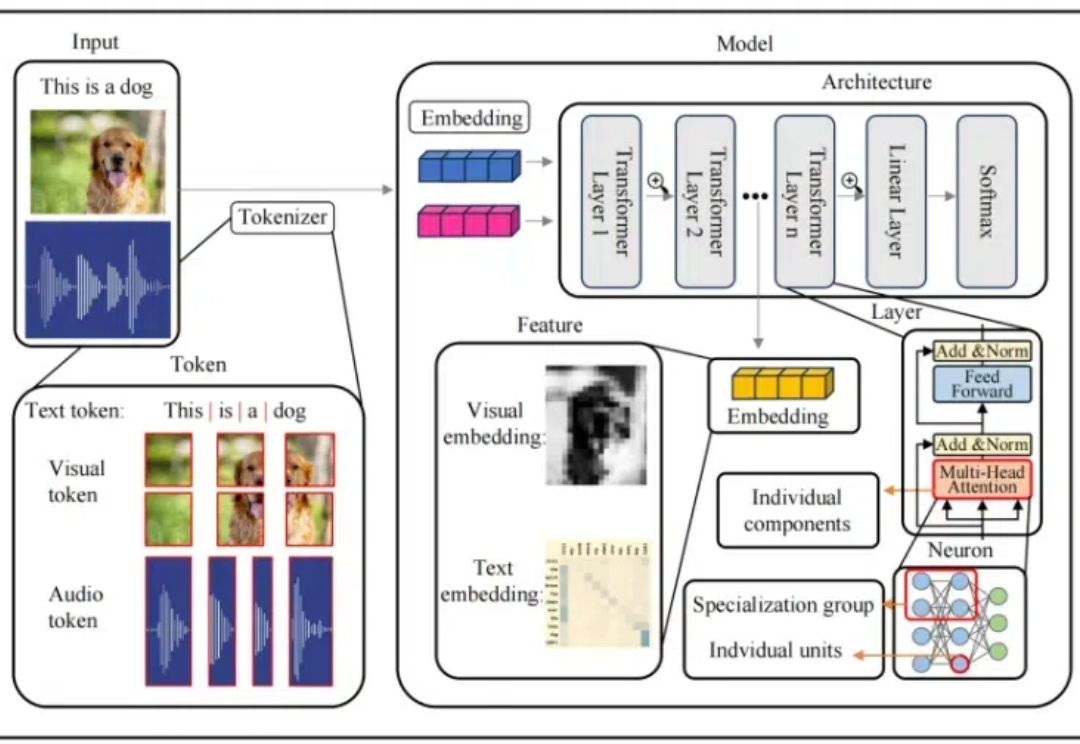
本文介绍了首个多模态大模型(MLLM)可解释性综述
OpenAI 放出了 o1 Pro、GPT-4o 高级语音、GPTCanavas,就跟孔雀开屏一样 ~ 谷歌最近的大动作是发布了 Gemini 2.0 嘛!2.0 比 1.5 版本快一倍,而且是原生的多模态大模型,能输入和生成语言、声音、图片、视频等。