
支付宝推出新一代AI视觉搜索产品“探一下”:用AI之眼探索万物
支付宝推出新一代AI视觉搜索产品“探一下”:用AI之眼探索万物12月30日,支付宝推出新一代AI视觉搜索产品“探一下”,基于自研的多模态大模型技术,可“用AI之眼探索万物”,提供更快速、有用、趣味的生成式搜索服务。
来自主题: AI资讯
5489 点击 2024-12-30 14:05
 搜索
搜索
12月30日,支付宝推出新一代AI视觉搜索产品“探一下”,基于自研的多模态大模型技术,可“用AI之眼探索万物”,提供更快速、有用、趣味的生成式搜索服务。

都说国产大模型“通义千问”能打,到底是真强还是智商税?今天就带你看看,这个国产“AI猛将”凭什么火出圈! 2023年4月,阿里巴巴推出通义千问,选择了“全开源”的策略,成为全球开发者关注的焦点。而在2024年的云栖大会上,阿里云进一步发布了Qwen2.5系列,包括多个尺寸的大语言模型、多模态模型、数学模型和代码模型,涵盖从0.5B到72B的完整规模

QVQ 在人工智能的视觉理解和复杂问题解决能力方面实现了重大突破。在 MMMU 评测中,QVQ 取得了 70.3 的优异成绩,并且在各项数学相关基准测试中相比 Qwen2-VL-72B-Instruct 都有显著提升。通过细致的逐步推理,QVQ 在视觉推理任务中展现出增强的能力,尤其在需要复杂分析思维的领域表现出色。
从开源与闭源的竞争,到多模态AI与自监督学习,再到能效优化和AI伦理的深入探讨,AI技术的演进将继续带来前所未有的创新机会。

李飞飞、谢赛宁团队又有重磅发现了:多模态LLM能够记住和回忆空间,甚至内部已经形成了局部世界模型,表现了空间意识!李飞飞兴奋表示,在2025年,空间智能的界限很可能会再次突破。
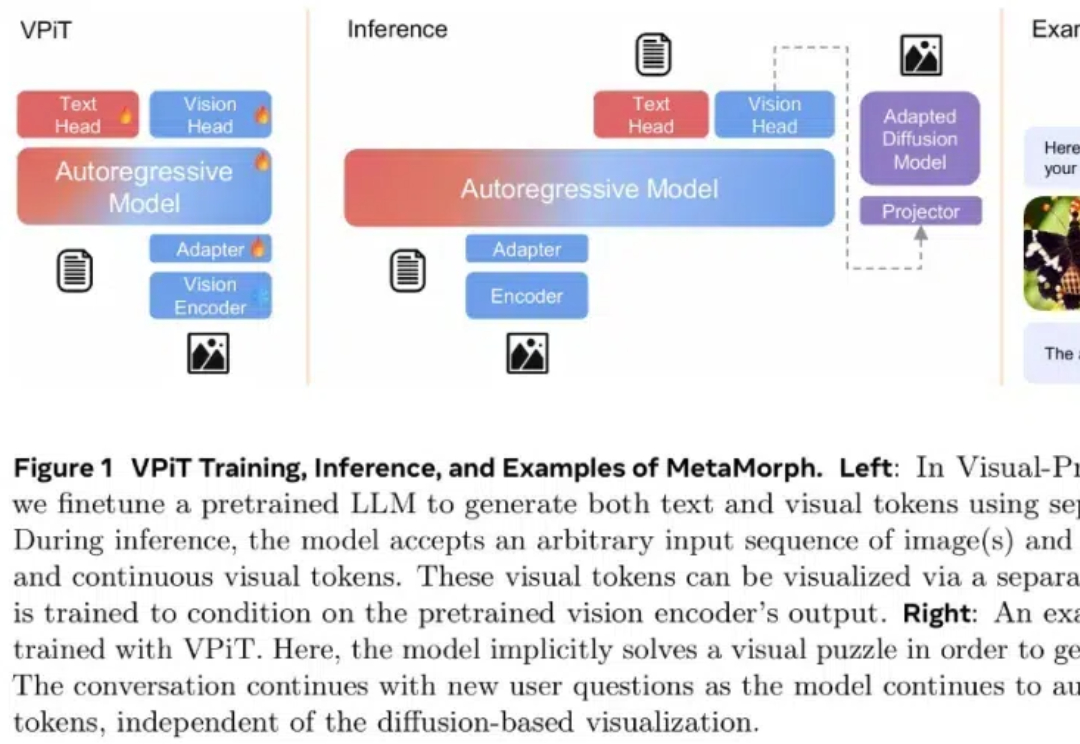
如今,多模态大模型(MLLM)已经在视觉理解领域取得了长足进步,其中视觉指令调整方法已被广泛应用。该方法是具有数据和计算效率方面的优势,其有效性表明大语言模型(LLM)拥有了大量固有的视觉知识,使得它们能够在指令调整过程中有效地学习和发展视觉理解。
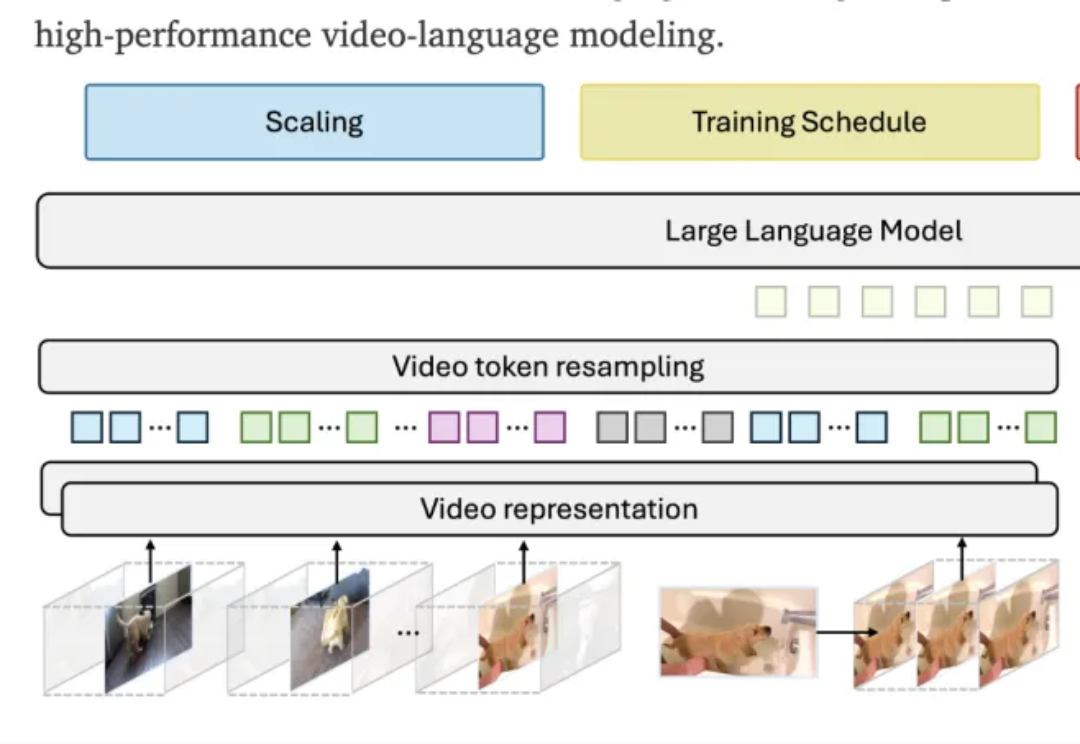
Meta斯坦福大学联合团队全面研究多模态大模型(LMM)中驱动视频理解的机制,扩展了视频多模态大模型的设计空间,提出新的训练调度和数据混合方法,并通过语言先验或单帧输入解决了已有的评价基准中的低效问题。
豆包的“眼睛”升级了,现在让它看一眼APP截图,就能直接给你生成代码!
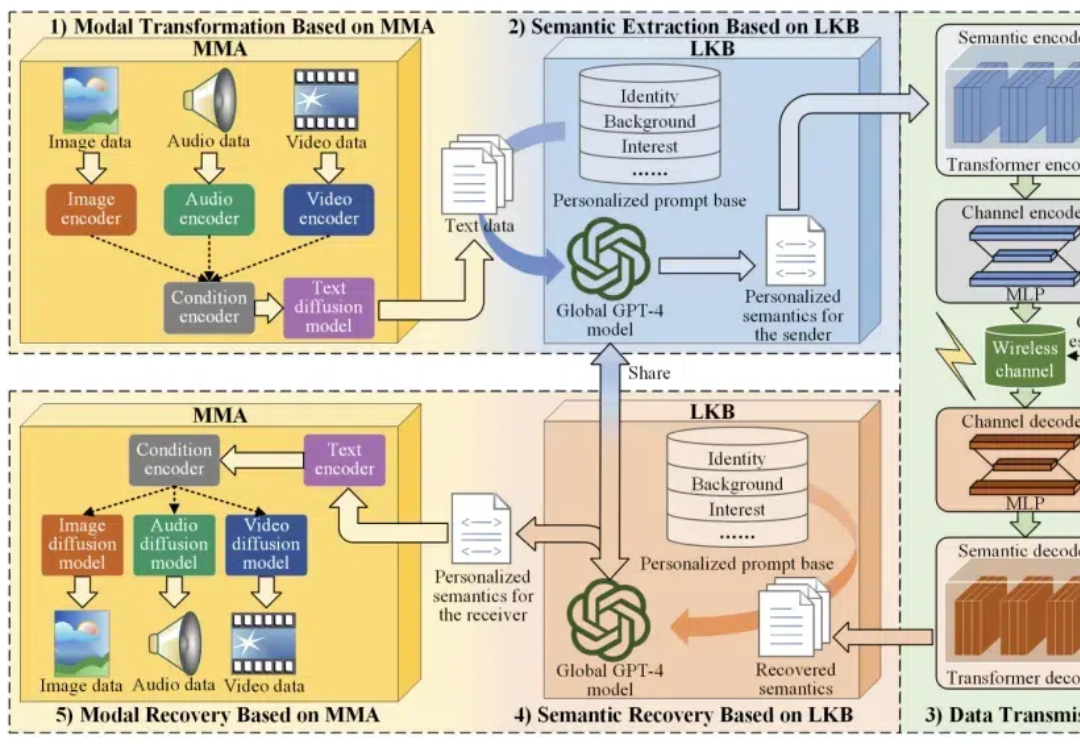
多模态信号,包括文本、音频、图像和视频等,可以被整合到语义通信中,在语义层面提供低延迟、高质量的沉浸式体验。

经过了LLM、RAG、多模态等多轮技术风口的洗礼后,AI智能体的应用现状究竟如何?Langbase公司最近发布的调查报告通过11个关键问题,为我们提供了一份有价值的现状切面。