
京东斩获中国AI最高奖项的唯一特等奖
京东斩获中国AI最高奖项的唯一特等奖近日,中国人工智能学会发布2024年度“吴文俊人工智能科学技术奖”公告,京东科技人工智能团队凭借“多模态交互式数字人关键技术及产业应用”项目荣获中国智能科学技术最高奖——吴文俊人工智能科学技术奖的特等奖,也是本年度唯一的特等奖。
来自主题: AI资讯
10314 点击 2025-03-20 09:07
 搜索
搜索
近日,中国人工智能学会发布2024年度“吴文俊人工智能科学技术奖”公告,京东科技人工智能团队凭借“多模态交互式数字人关键技术及产业应用”项目荣获中国智能科学技术最高奖——吴文俊人工智能科学技术奖的特等奖,也是本年度唯一的特等奖。
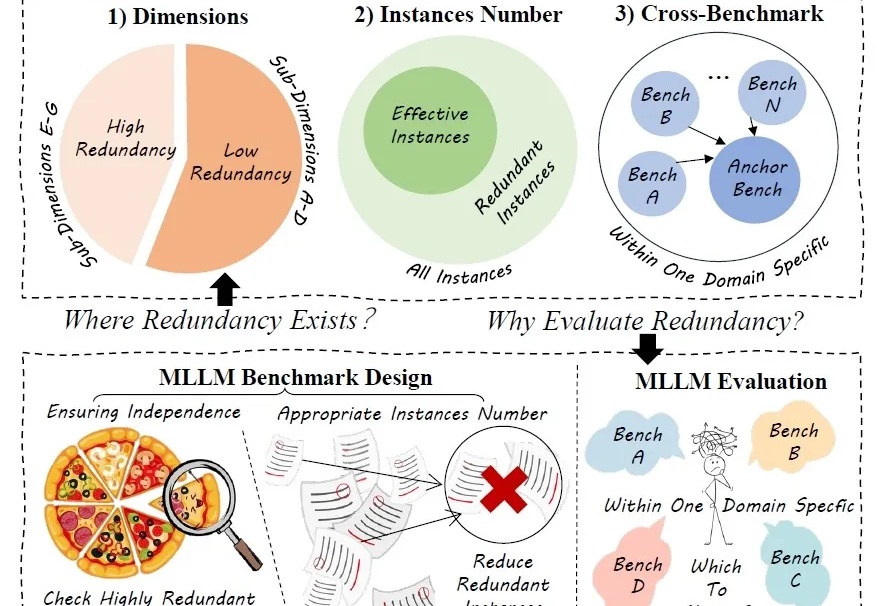
评估多模态AI模型的那些复杂测试,可能有一半都是“重复劳动”!

多模态大模型虽然在视觉理解方面表现出色,但在需要深度数学推理的任务上往往力不从心,尤其是对于参数量较小的模型来说更是如此。

通过收集六名志愿者一周的多模态生活数据,研究人员构建了300小时的第一视角数据集EgoLife,旨在开发一款基于智能眼镜的AI生活助手。项目提出了EgoButler系统,包含EgoGPT和EgoRAG两个模块,分别用于视频理解与长时记忆问答,助力AI深入理解日常生活并提供个性化帮助。

全球首个开源多模态推理大模型来了!38B参数模型性能直逼DeepSeek-R1,同尺寸上横扫多项SOTA。而这家中国公司之所以选择无偿将技术思路开源,正是希望同DeepSeek一样,打造开源界的技术影响力。
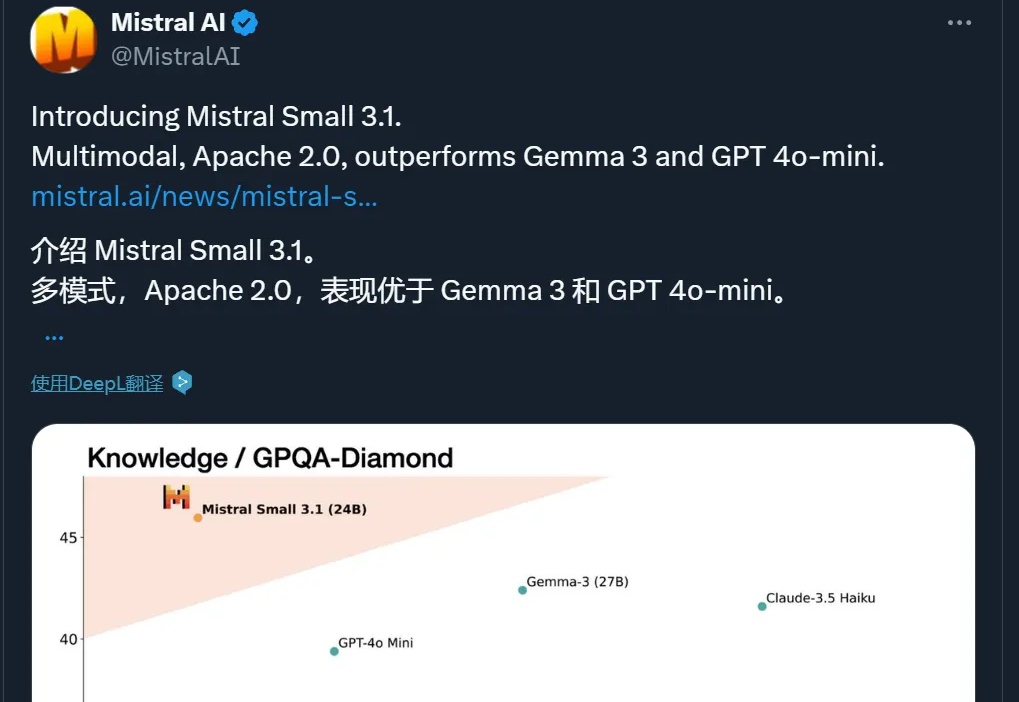
多模态,性能超 GPT-4o Mini、Gemma 3,还能在单个 RTX 4090 上运行,这个小模型值得一试。
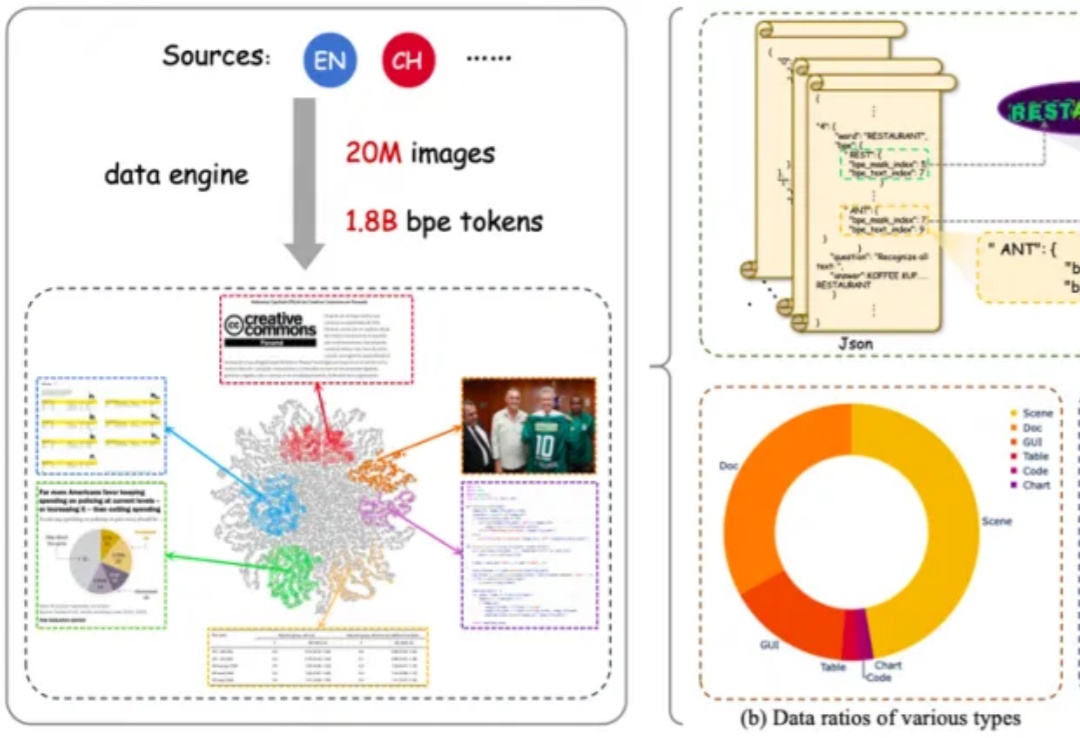
CLIP、DINO、SAM 基座的重磅问世,推动了各个领域的任务大一统,也促进了多模态大模型的蓬勃发展。

尽管 DeepSeek-R1 在单模态推理中取得了显著成功,但已有的多模态尝试(如 R1-V、R1-Multimodal-Journey、LMM-R1)尚未完全复现其核心特征。

在实际应用过程中,闭源模型(GPT-4o)等在回复的全面性、完备性、美观性等方面展示出了不俗的表现。

就在刚刚,谷歌Gemma 3来了,1B、4B、12B和27B四种参数,一块GPU/TPU就能跑!而Gemma 3仅以27B就击败了DeepSeek 671B模型,成为仅次于DeepSeek R1最优开源模型。