
多模态检索大升级!智源三大SOTA模型,代码、图文理解能力拉满
多模态检索大升级!智源三大SOTA模型,代码、图文理解能力拉满就在刚刚,智源研究员联合多所高校开放三款向量模型,以大优势登顶多项测试基准。其中,BGE-Code-v1直接击穿代码检索天花板,百万行级代码库再也不用怕了!
来自主题: AI技术研报
7695 点击 2025-05-20 14:45
 搜索
搜索
就在刚刚,智源研究员联合多所高校开放三款向量模型,以大优势登顶多项测试基准。其中,BGE-Code-v1直接击穿代码检索天花板,百万行级代码库再也不用怕了!
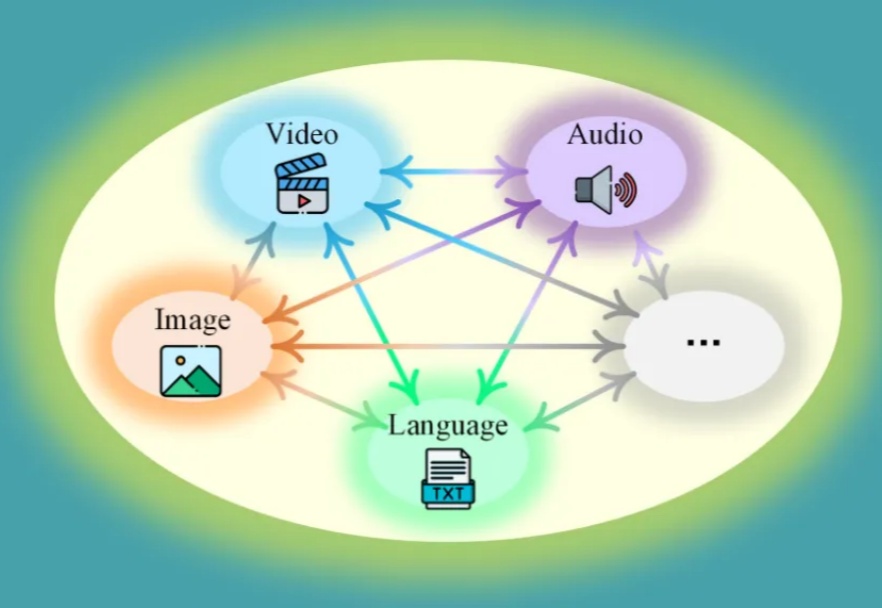
理想中的多模态大模型应该是什么样?十所顶尖高校联合发布General-Level评估框架和General-Bench基准数据集,用五级分类制明确了多模态通才模型的能力标准。当前多模态大语言模型在任务支持、模态覆盖等方面存在不足,且多数通用模型未能超越专家模型,真正的通用人工智能需要实现模态间的协同效应。

统一图像理解和生成,还实现了新SOTA。
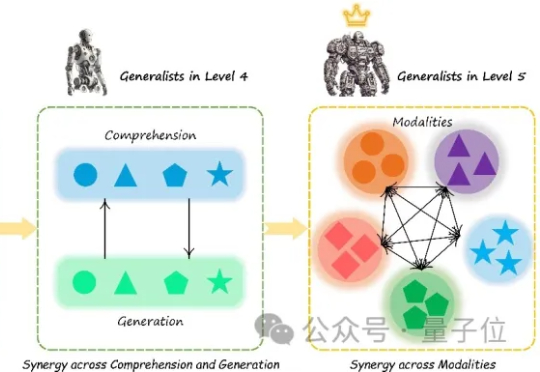
多模态大模型(Multimodal Large Language Models, MLLM)正迅速崛起,从只能理解单一模态,到如今可以同时理解和生成图像、文本、音频甚至视频等多种模态。正因如此,在AI竞赛进入“下半场”之际(由最近的OpenAI研究员姚顺雨所引发的共识观点),设计科学的评估机制俨然成为决定胜负的核心关键。

在 InfoQ 举办的 AICon 全球人工智能开发与应用大会上摯文集团生态技术负责人李波做了专题演讲“大模型在社交生态领域的落地实践”,演讲从摯文集团实际的生态问题出发,从多模态大模型如何进行对抗性生态内容理解、如何进行细粒度用户性质判定,以及如何进行人机协同降本提效等方向展开。

字节拿出了国际顶尖水平的视觉–语言多模态大模型。

在多模态大模型快速发展的当下,如何精准评估其生成内容的质量,正成为多模态大模型与人类偏好对齐的核心挑战。然而,当前主流多模态奖励模型往往只能直接给出评分决策,或仅具备浅层推理能力,缺乏对复杂奖励任务的深入理解与解释能力,在高复杂度场景中常出现 “失真失准”。
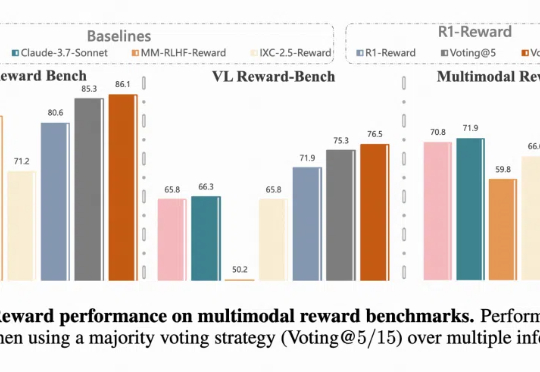
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用,在训练阶段可以提供稳定的 reward,评估阶段可以选择更好的 sample 结果,甚至单独作为 evaluator。

当大模型赛道中不少玩家明确表示放弃基础大模型研发,心思放在更聚焦的方向上时,阶跃星辰站出来——就像这家公司第一次亮相时那样,给外界一个明确的回答:
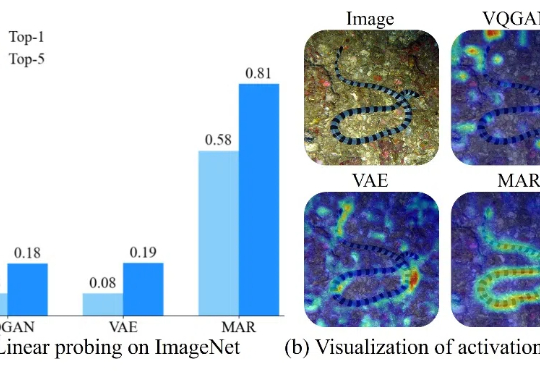
GPT-4o 生图功能的出现揭示了统一理解与生成模型的巨大潜力,然而如何在同一个框架内协调图像理解与生成这两种不同粒度的任务,是一个巨大的挑战。