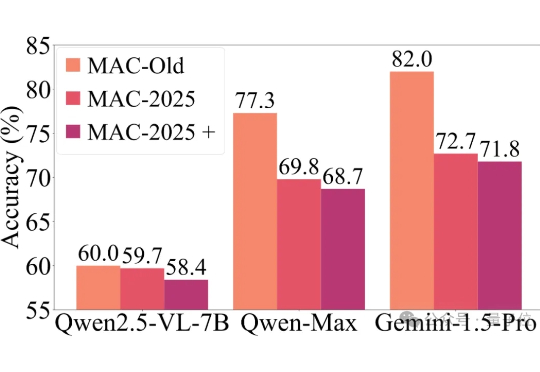
为防AI刷题,Nature等顶刊最新封面被做成数据集,考验模型科学推理能力|上海交通大学
为防AI刷题,Nature等顶刊最新封面被做成数据集,考验模型科学推理能力|上海交通大学近年来,以GPT-4o、Gemini 2.5 Pro为代表的多模态大模型,在各大基准测试(如MMMU)中捷报频传,纷纷刷榜成功。
来自主题: AI技术研报
9099 点击 2025-08-26 10:41
 搜索
搜索
近年来,以GPT-4o、Gemini 2.5 Pro为代表的多模态大模型,在各大基准测试(如MMMU)中捷报频传,纷纷刷榜成功。
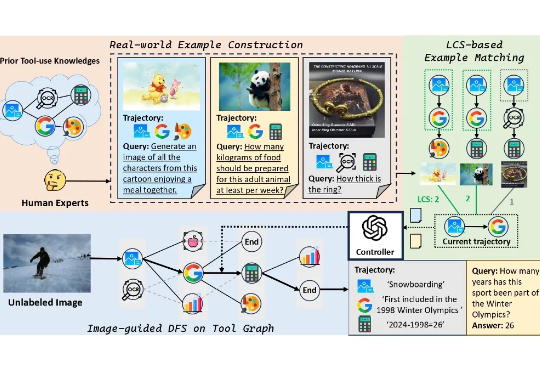
本文提出了一个旨在提升基础模型工具使用能力的大型多模态数据集 ——ToolVQA。现有研究已在工具增强的视觉问答(VQA)任务中展现出较强性能,但在真实世界中,多模态任务往往涉及多步骤推理与功能多样的工具使用,现有模型在此方面仍存在显著差距。

在科研、新闻报道、数据分析等领域,图表是信息传递的核心载体。要让多模态大语言模型(MLLMs)真正服务于科学研究,必须具备以下两个能力

多模态的生成,是 AI 未来的方向。 最近,AI 领域的气氛正在发生微妙的变化。比如,刚刚推出了 Grok 4 的 xAI 却在重点宣传他们的视频生成模型 Grok Image。
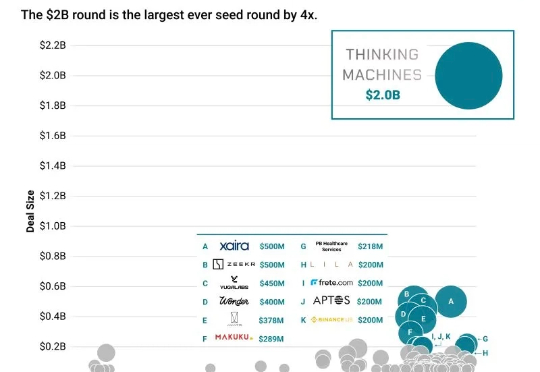
硅谷各个模型公司在这个季度,开始分化到各个领域,除了 Google Gemini 和 OpenAI 还在做通用的模型;Anthropic 分化到 Coding、Agentic 的模型能力;Mira 的 Thinking Machines Lab 分化到多模态和下一代交互。
大模型与多模态之间的关系,可以理解为大模型就像是人脑中的‘前额叶’,主要负责高级认知功能,但只有前额叶的大脑是无法处理复杂任务的,这就需要多个不同模型之间互相协调,从单纯的“前额叶”走向“完整的大脑”,从而处理更加复杂的现实任务。

手机是这个问题的标准解法,但它有个悖论:为了记录生活,你必须先打断生活。掏出手机、解锁、打开相机、对焦、按下快门——这个流程本身就是对「当下」的破坏。 所以,当一个名叫 Looki L1 的 AI 硬件出现在我们面前时,我们的目标非常明确:验证它能否解决这个悖论。

全球首款多模态 AI 硬件 Looki L1 发布,抢先实现了 OpenAI 想象中的交互未来。过去两年,很多人对 AI 的印象,基本都停留在一个对话框里: 有问题,敲几个字,它就给答案。好用是好用,但也让人觉得有点单调——AI 难道就只能困在对话框里吗?
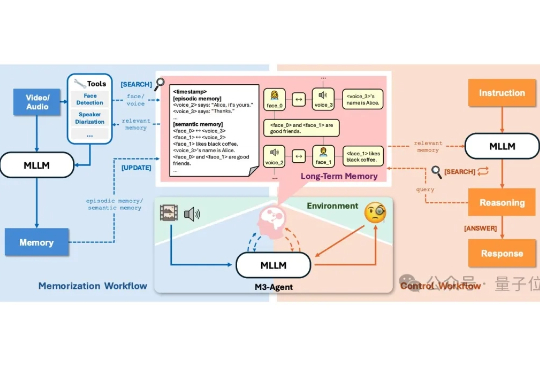
字节Seed发布全新多模态智能体框架——M3-Agent。 像人类一样能听会看、具备长期记忆,并且免费开源!?

鲨疯了!一周连发六款模型。火力全开的昆仑万维,正在把多模态AI卷到新高度。8月11日~15日,这家公司天天都有新模型掉落,覆盖的还都是视频生成、世界模型、统一多模态、智能体以及AI音乐创作这些大热门,几乎每一个都是多模态AI应用的核心场景。