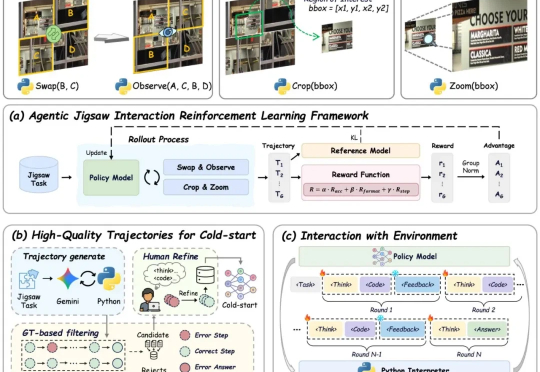
AGILE:视觉学习新范式!自监督+交互式强化学习助力VLMs感知与推理全面提升
AGILE:视觉学习新范式!自监督+交互式强化学习助力VLMs感知与推理全面提升现有视觉语言大模型(VLMs)在多模态感知和推理任务上仍存在明显短板:1. 对图像中的细粒度视觉信息理解有限,视觉感知和推理能力未被充分激发;2. 强化学习虽能带来改进,但缺乏高质量、易扩展的 RL 数据。
来自主题: AI技术研报
7878 点击 2025-10-21 15:30
 搜索
搜索
现有视觉语言大模型(VLMs)在多模态感知和推理任务上仍存在明显短板:1. 对图像中的细粒度视觉信息理解有限,视觉感知和推理能力未被充分激发;2. 强化学习虽能带来改进,但缺乏高质量、易扩展的 RL 数据。

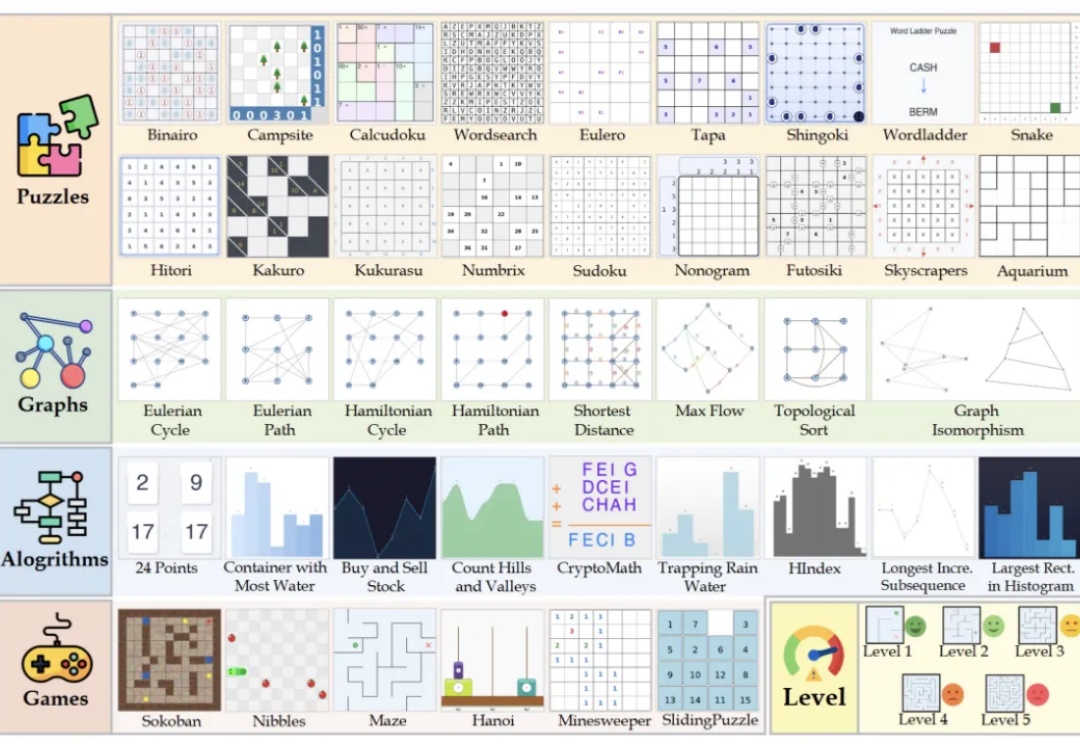
复旦大学NLP实验室研发Game-RL,利用游戏丰富视觉元素和明确规则生成多模态可验证推理数据,通过强化训练提升视觉语言模型的推理能力。创新性地提出Code2Logic方法,系统化合成游戏任务数据,构建GameQA数据集,验证了游戏数据在复杂推理训练中的优势。

美国麻省理工学院李巨团队在国际顶尖学术期刊Nature上发表了一篇研究论文,展示了一种多模态机器人平台CRESt(Copilot for Real-world Experimental Scientists),通过将多模态模型(融合文本知识、化学成分以及微观结构信息)驱动的材料设计与高通量自动化实验相结合,大幅提升催化剂的研发速度和质量。
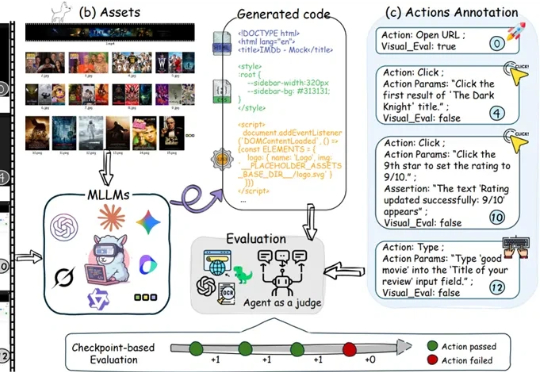
多模态大模型在根据静态截图生成网页代码(Image-to-Code)方面已展现出不俗能力,这让许多人对AI自动化前端开发充满期待。
多模态大模型表现越来越惊艳,但人们也时常困于它的“耿直”。

每隔一阵子,总有人宣告“RAG已死”:上下文越来越长、端到端多模态模型越来越强,好像不再需要检索与证据拼装。但真正落地到复杂文档与可溯源场景,你会发现死掉的只是“只切文本的旧RAG”。

2 天前,国内最大的 AI 多模态模型社区之一的 LiblibAI 进行了一次大升级,正式推出了 2.0 版本。对许多创作者而言,这个平台并不陌生,LiblibAI 一直是国内开源绘画与 LoRA 文化的重要发源地,也常被称为中国版的 CivitAI (大家常说的 C 站)。

多模态大模型首次实现像素级推理,指代、分割、推理三大任务一网打尽!
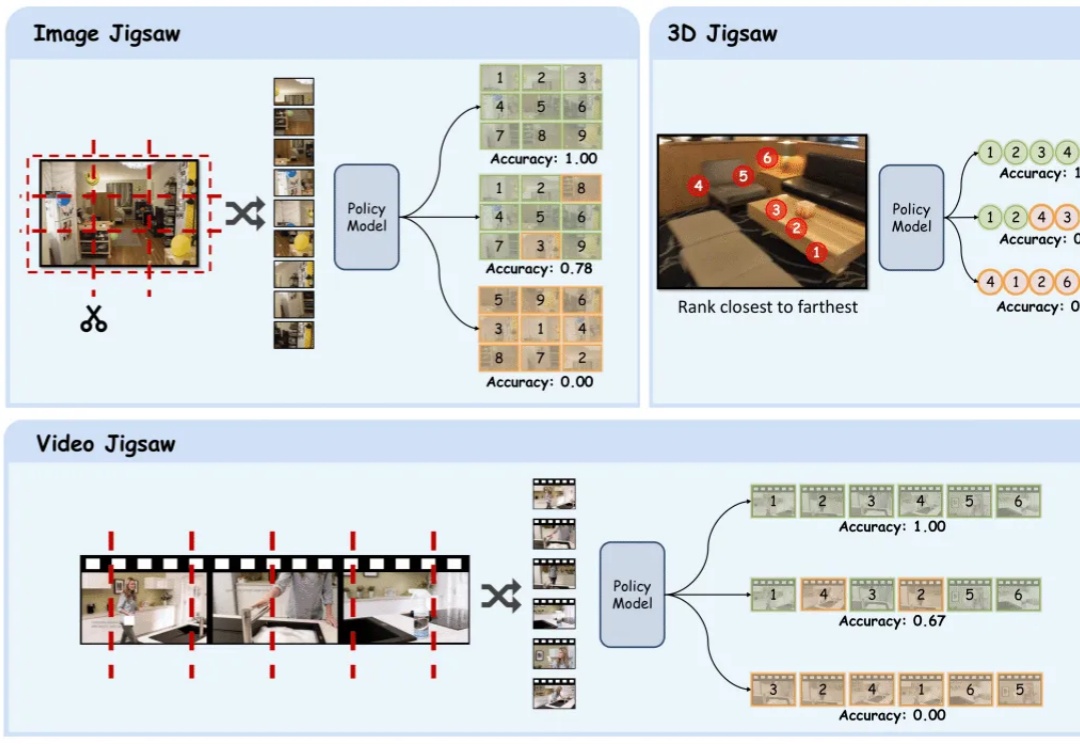
在多模态大模型的后训练浪潮中,强化学习驱动的范式已成为提升模型推理与通用能力的关键方向。

近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)在图文理解、视觉问答等任务上取得了令人瞩目的进展。然而,当面对需要精细空间感知的任务 —— 比如目标检测、实例分割或指代表达理解时,现有模型却常常「力不从心」。