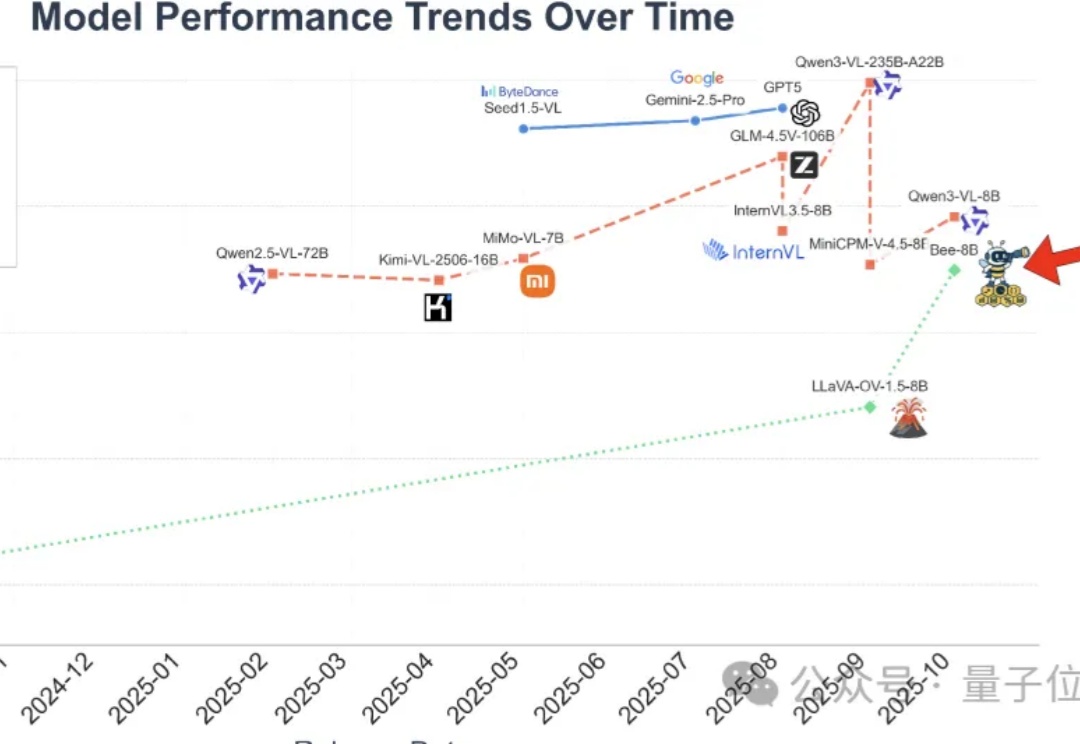
打破数据质量鸿沟!清华腾讯Bee项目发布1500万高质量数据集,刷新MLLM全栈开源SOTA
打破数据质量鸿沟!清华腾讯Bee项目发布1500万高质量数据集,刷新MLLM全栈开源SOTA全开源多模态大模型(MLLM)的性能,长期被闭源和半开源模型“卡脖子”。
来自主题: AI技术研报
8612 点击 2025-11-11 16:39
 搜索
搜索
全开源多模态大模型(MLLM)的性能,长期被闭源和半开源模型“卡脖子”。
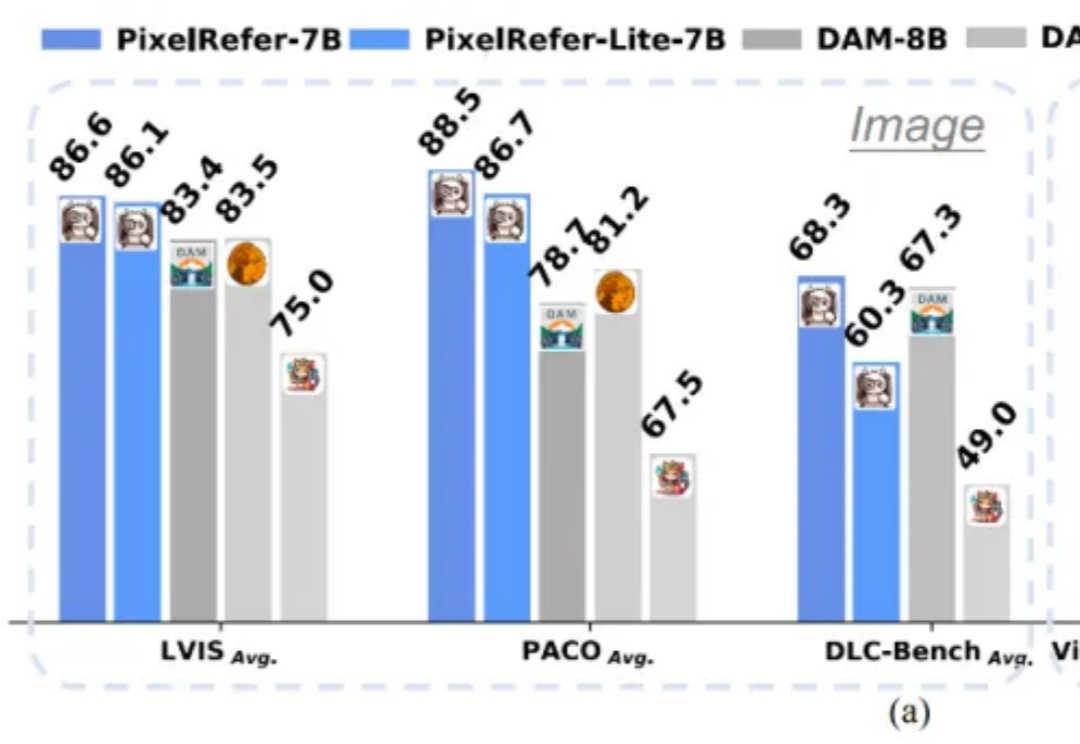
多模态大模型(MLLMs)虽然在图像理解、视频分析上表现出色,但多停留在整体场景级理解。
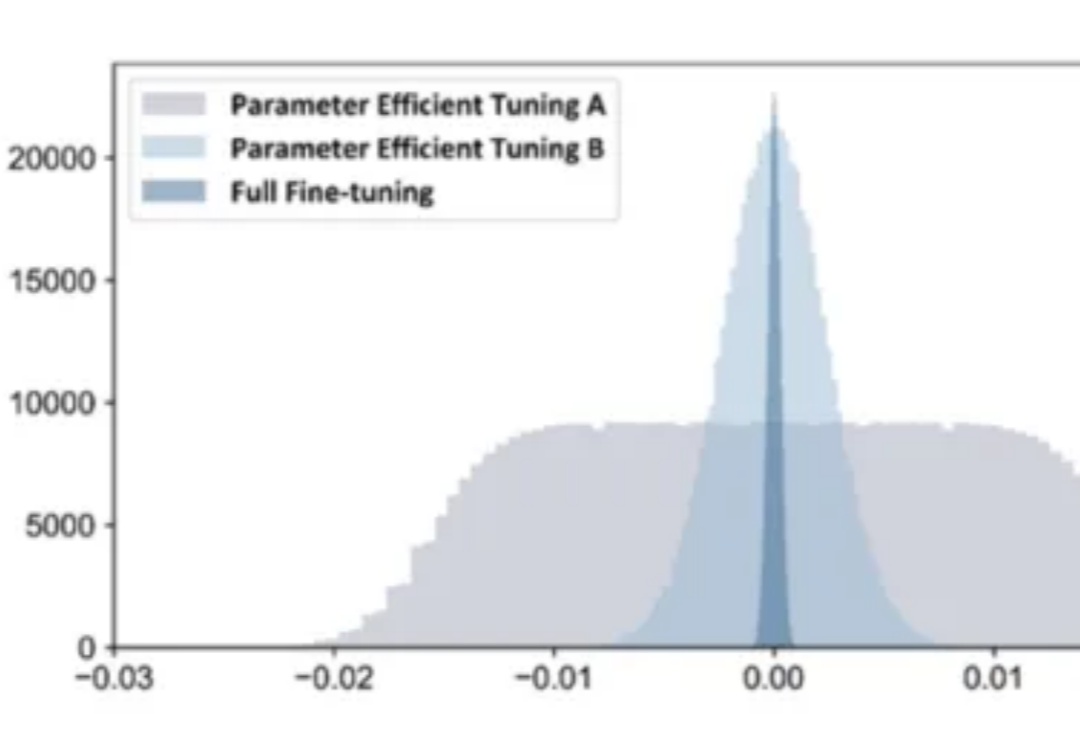
在 AI 技术飞速发展的今天,如何高效地将多个专业模型的能力融合到一个通用模型中,是当前大模型应用面临的关键挑战。全量微调领域已经有许多开创性的工作,但是在高效微调领域,尚未有对模型合并范式清晰的指引。

去年,谢赛宁(Saining Xie)团队发布了 Cambrian-1,一次对图像多模态模型的开放式探索。但团队没有按惯例继续推出 Cambrian-2、Cambrian-3,而是停下来思考:真正的多
OmniVinci是英伟达推出的全模态大模型,能精准解析视频和音频,尤其擅长视觉和听觉信号的时序对齐。它以90亿参数规模,性能超越同级别甚至更高级别模型,训练数据效率是对手的6倍,大幅降低成本。在视频内容理解、语音转录、机器人导航等场景中,OmniVinci能提供高效支持,展现出卓越的多模态应用能力。
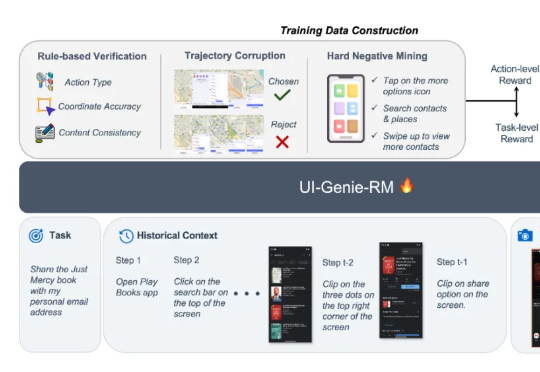
本文来自于香港中文大学 MMLab 和 vivo AI Lab,其中论文第一作者肖涵,主要研究方向为多模态大模型和智能体学习,合作作者王国志,研究方向为多模态大模型和 Agent 强化学习。项目 le

当前机器人领域,基础模型主要基于「视觉-语言预训练」,这样可将现有大型多模态模型的语义泛化优势迁移过来。但是,机器人的智能确实能随着算力和数据的增加而持续提升吗?我们能预测这种提升吗?
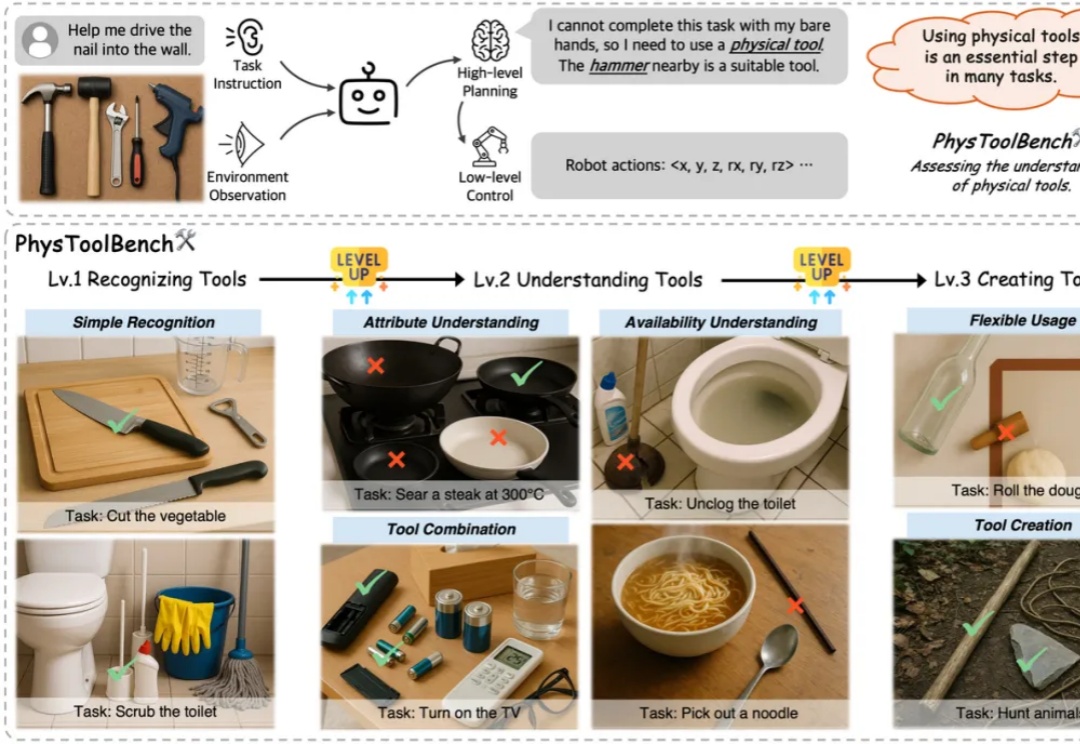
人类之所以能与复杂的物理世界高效互动,很大程度上源于对「工具」的使用、理解与创造能力。对任何通用型智能体而言,这同样是不可或缺的基本技能,对物理工具的使用会大大影响任务的成功率与效率。
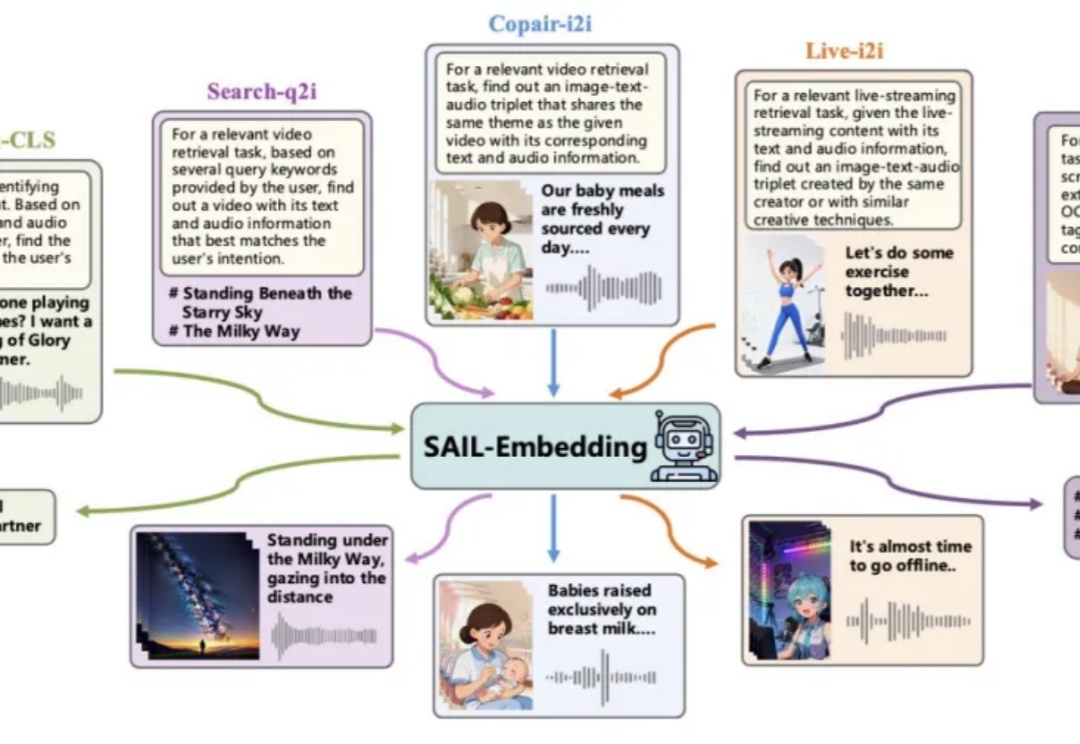
在短视频推荐、跨模态搜索等工业场景中,传统多模态模型常受限于模态支持单一、训练不稳定、领域适配性差等问题。

2025 年被广泛视为 AI 走向深度应用的关键元年,在这一年里,以多模态生成、Agent 为代表的 AI 技术不断探索更多样、更高效、更贴合用户需求的应用形态。其中重要性愈加凸显的一点是:AI 正在走向产业级价值的系统性兑现。