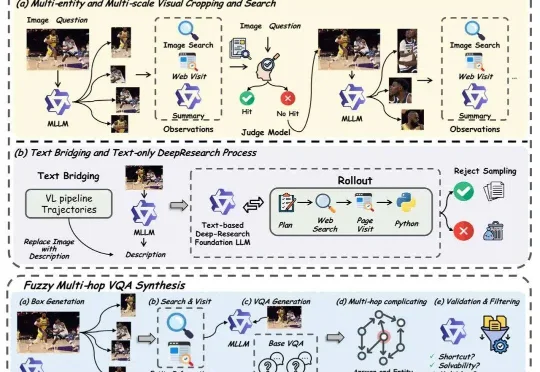
ICLR2026 Oral | 当情感识别不再是分类题:EmotionThinker 让 SpeechLLM 学会“解释情绪”
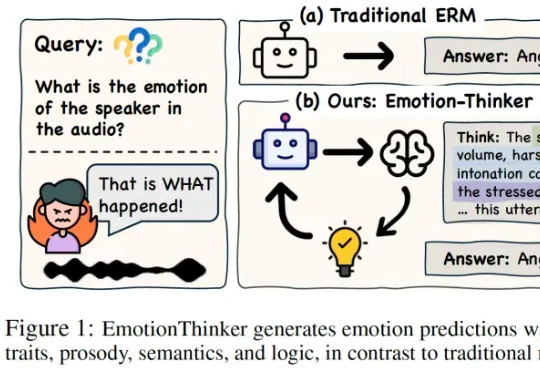
ICLR2026 Oral | 当情感识别不再是分类题:EmotionThinker 让 SpeechLLM 学会“解释情绪”SpeechLLM 是否具备像人类一样解释 “为什么” 做出情绪判断的能力?为此,研究团队提出了EmotionThinker—— 首个面向可解释情感推理(Explainable Emotion Reasoning)的强化学习框架,尝试将 SER 从 “分类任务” 提升为 “多模态证据驱动的推理任务”。
来自主题: AI技术研报
9133 点击 2026-02-25 14:28