凌晨战神Qwen又搞事情!新模型让图像编辑“哪里不对改哪里”
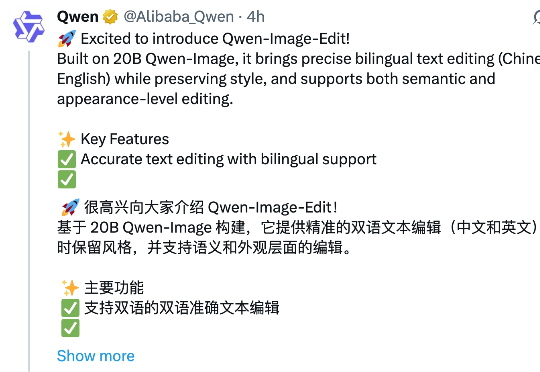
凌晨战神Qwen又搞事情!新模型让图像编辑“哪里不对改哪里”瞧,上面这套“哪里不对改哪里”的操作,就来自“凌晨战神”Qwen团队最新发布的——Qwen-Image-Edit。作为Qwen-Image20B的图像编辑版,Qwen-Image-Edit除了能做上面这种精准的文字修改,还能够新增、消除、重绘、修改元素,而且还支持IP编辑、视角切换、风格迁移等生成式玩法。
来自主题: AI资讯
9227 点击 2025-08-19 21:32

![Black Forest震撼开源FLUX.1 Kontext [dev]:媲美GPT-4o的图像编辑](https://www.aitntnews.com/pictures/2025/6/27/49d75709-5310-11f0-82be-fa163e47d677.jpg)