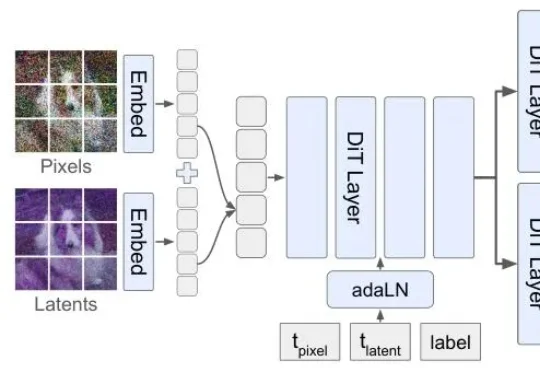
李飞飞团队新作:简单调整生成顺序,大幅提升像素级图像生成质量
李飞飞团队新作:简单调整生成顺序,大幅提升像素级图像生成质量但扩散模型生图,顺序真的对吗?李飞飞团队最新论文提出的Latent Forcing方法直接打破了这一共识,他们发现生成的质量瓶颈不在架构,而在顺序。
来自主题: AI技术研报
9230 点击 2026-02-15 21:27
 搜索
搜索
但扩散模型生图,顺序真的对吗?李飞飞团队最新论文提出的Latent Forcing方法直接打破了这一共识,他们发现生成的质量瓶颈不在架构,而在顺序。

今天,阿里巴巴发布了新一代图像生成基础模型Qwen-Image 2.0,这一模型支持长达一千个token的超长指令、2k分辨率,并采用了更轻量的模型架构,模型尺寸远小于Qwen-Image 2.0的20B,带来更快的推理速度。
新模型对标Nano Banana Pro,能免费体验。Seedance 2.0的热度还没下去,字节新模型又来了!今日,字节图像生成模型Seedream 5.0 Preview在视频编辑应用剪映、剪映海外版Capcut、字节AI创作平台小云雀均已上线,在即梦AI平台开启灰度测试,图片生成可限时免费体验。

何恺明,再次出手精简架构。
今天,首个在国产芯片上完成全程训练的SOTA(最佳水平)多模态模型开源。这是智谱联合华为开源的图像生成模型GLM-Image。从数据到训练的全流程,该模型完全基于昇腾Atlas 800T A2设备和昇思MindSpore AI框架完成构建。

抽奖式的生图体验,确实让很多设计师在尝鲜之后又默默打开了 Photoshop。于是乎,阿里千问团队再次出手,开源了一个叫 Qwen-Image-Layered 的模型,试图从底层逻辑上解决这个问题。
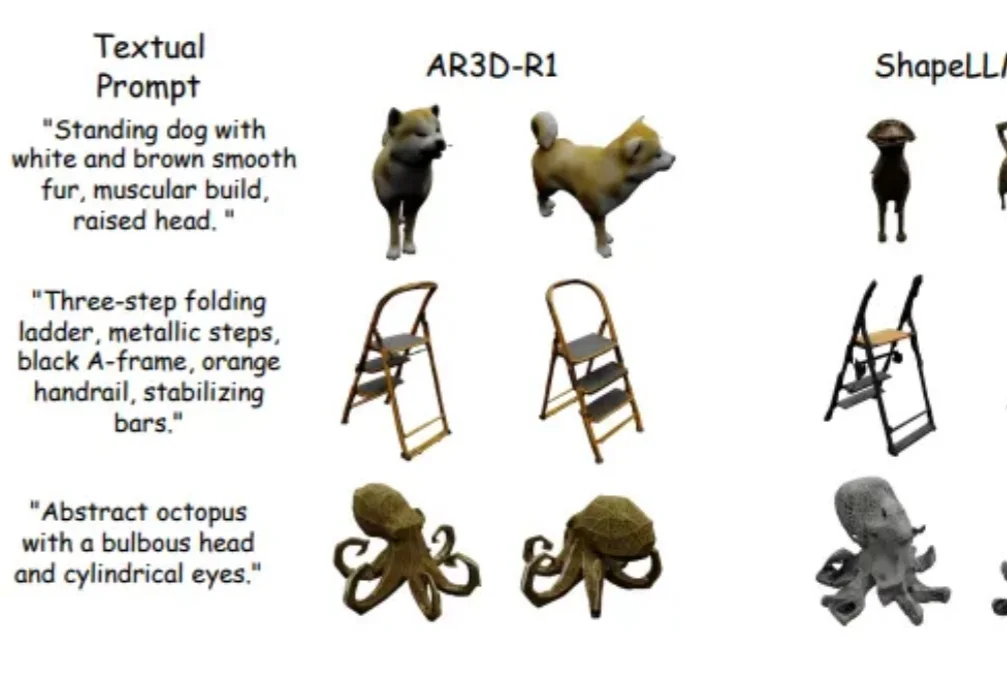
强化学习(RL)在大语言模型和 2D 图像生成中大获成功后,首次被系统性拓展到文本到 3D 生成领域!面对 3D 物体更高的空间复杂性、全局几何一致性和局部纹理精细化的双重挑战,研究者们首次系统研究了 RL 在 3D 自回归生成中的应用!

浙江大学ReLER团队开源ContextGen框架,攻克多实例图像生成中布局与身份协同控制难题。基于Diffusion Transformer架构,通过双重注意力机制,实现布局精准锚定与身份高保真隔离,在基准测试中超越开源SOTA模型,对标GPT-4o等闭源系统,为定制化AI图像生成带来新突破。

尽管扩散模型在单图像生成上已经日渐成熟,但当任务升级为高度定制化的多实例图像生成(Multi-Instance Image Generation, MIG)时,挑战随之显现:

Canvas-to-Image 是一种新型图像生成框架,将多种控制方式(如身份、姿态、空间布局)整合到一个统一画布中,用户可通过直观操作生成高保真、多控制的图像。它简化了创作流程,让用户在单一界面完成复杂创作,为AI创作工具提供了新范式。