
不用GAN不用扩散,无需训练解锁AI生图新境界!判别模型成神秘第三极
不用GAN不用扩散,无需训练解锁AI生图新境界!判别模型成神秘第三极你能想象判别模型也能成为强大的图像合成高手吗?「直接上升合成」(DAS)做到了!它突破传统认知,借助多分辨率优化等创新技术,在图像生成的多个关键任务中表现出色。
来自主题: AI技术研报
6865 点击 2025-02-24 16:37
 搜索
搜索
你能想象判别模型也能成为强大的图像合成高手吗?「直接上升合成」(DAS)做到了!它突破传统认知,借助多分辨率优化等创新技术,在图像生成的多个关键任务中表现出色。

最近,扩散模型在生成模型领域异军突起,凭借其独特的生成机制在图像生成方面大放异彩,尤其在处理高维复杂数据时优势明显。然而,尽管扩散模型在图像生成任务中表现优异,但在图像目标移除任务中仍然面临诸多挑战。现有方法在移除前景目标后,可能会留下残影或伪影,难以实现与背景的自然融合。
2025年2月24日,明势早期项目、AI图像生成平台「LiblibAI-哩布哩布AI」宣布在一年内已连续完成四轮融资。继2024年7月披露的数亿元融资后,又成功斩获数亿元资金,发展势头迅猛,创下国内AI应用赛道融资速度纪录。

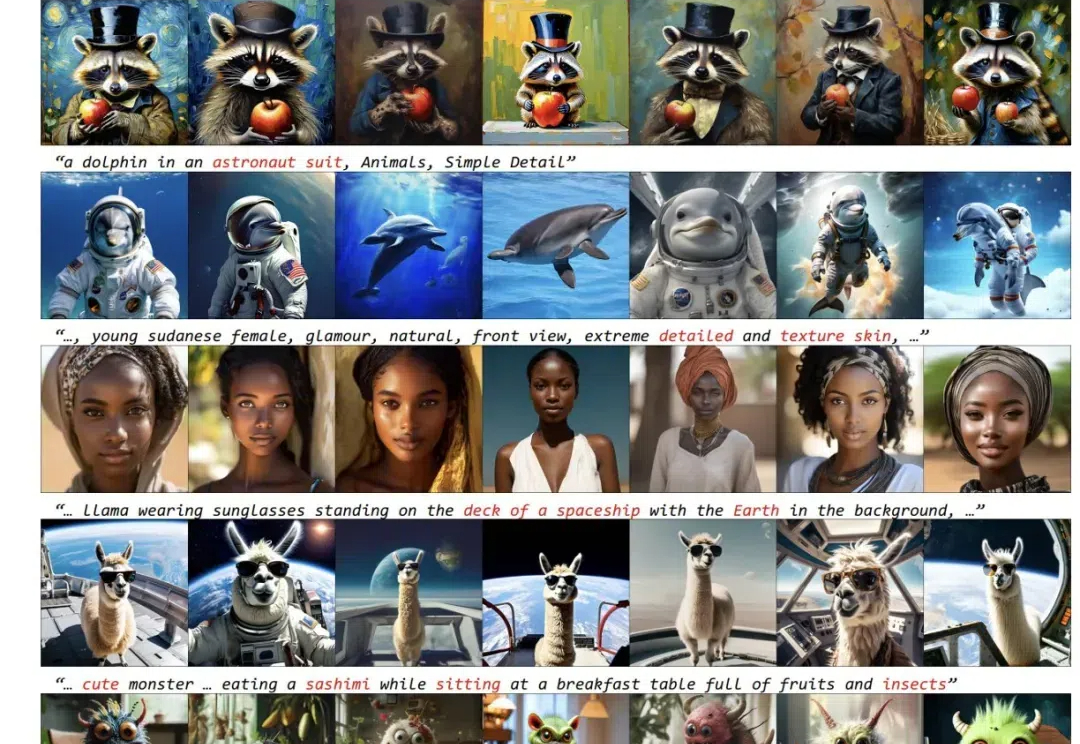
图像生成模型,也用上思维链(CoT)了!此外,作者还提出了两种专门针对该任务的新型奖励模型——潜力评估奖励模型。(Potential Assessment Reward Model,PARM)及其增强版本PARM++。
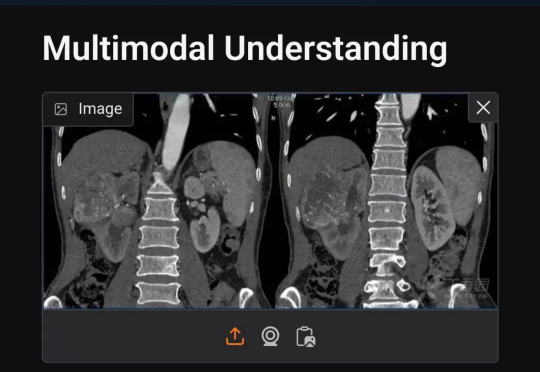
就在除夕前的晚上(2025 年 1 月 27 日),Deepseek 发布了多模态模型 Janus-Pro-7B,该模型在图像生成和多模态理解方面都超过了OpenAI的DALL-E 3(虽然也一般般),我相信能文生图功能一定很优秀了,今天搞点特殊的,测试下图像理解能力对专业的医学影像有没有应用的可行性,以下是常见的五种医学影像测试。

Stability AI推出3D重建方法:2D图像秒变3D,还可以交互式实时编辑。新方法的原理、代码、权重、数据全公开,而且许可证宽松,可以商用。新方法采用点扩展模型生成稀疏点云,之后通过Transformer主干网络,同时处理生成的点云数据和输入图像生成网格。以后,人人都能轻松上手3D模型设计。

2025 年来了,3D 生成也迎来了新突破。 刚刚,Stability AI 在 CES 上宣布为 3D 生成推出一种两阶段新方法 ——SPAR3D(Stable Point Aware 3D),旨在为游戏开发者、产品设计师和环境构建者开拓 3D 原型设计新方式。
随着图像编辑工具和图像生成技术的快速发展,图像处理变得非常方便。然而图像在经过处理后不可避免的会留下伪影(操作痕迹),这些伪影可分为语义和非语义特征。
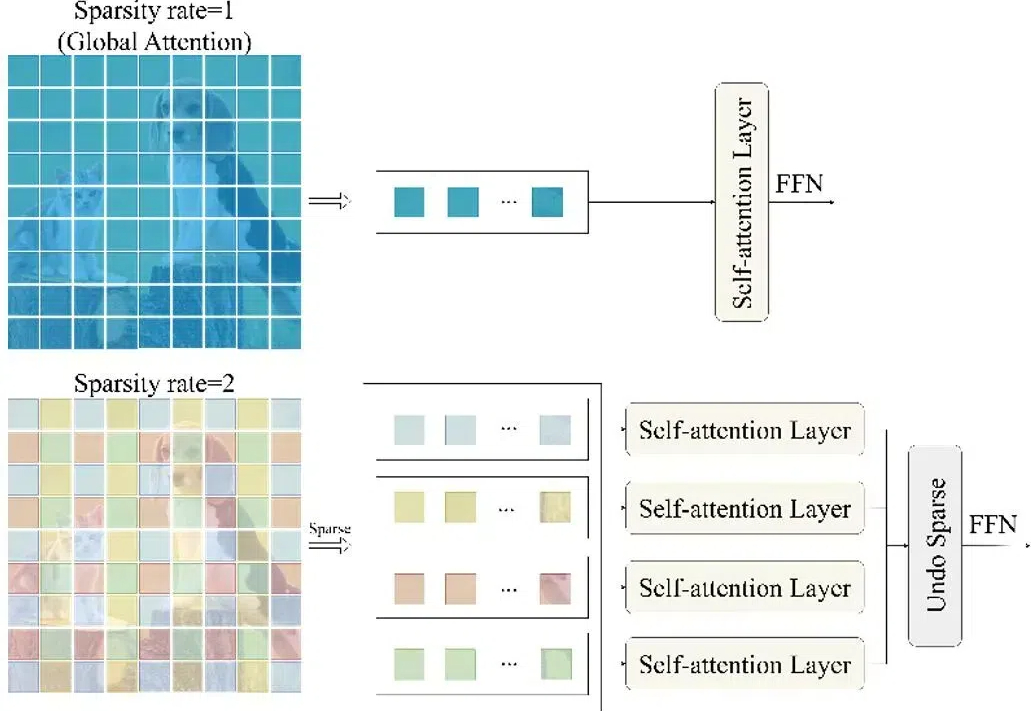
近些年来,以 Stable Diffusion 为代表的扩散模型为文生图(T2I)任务树立了新的标准,PixArt,LUMINA,Hunyuan-DiT 以及 Sana 等工作进一步提高了图像生成的质量和效率。然而,目前的这些文生图(T2I)扩散模型受限于模型尺寸和运行时间,仍然很难直接部署到移动设备上。
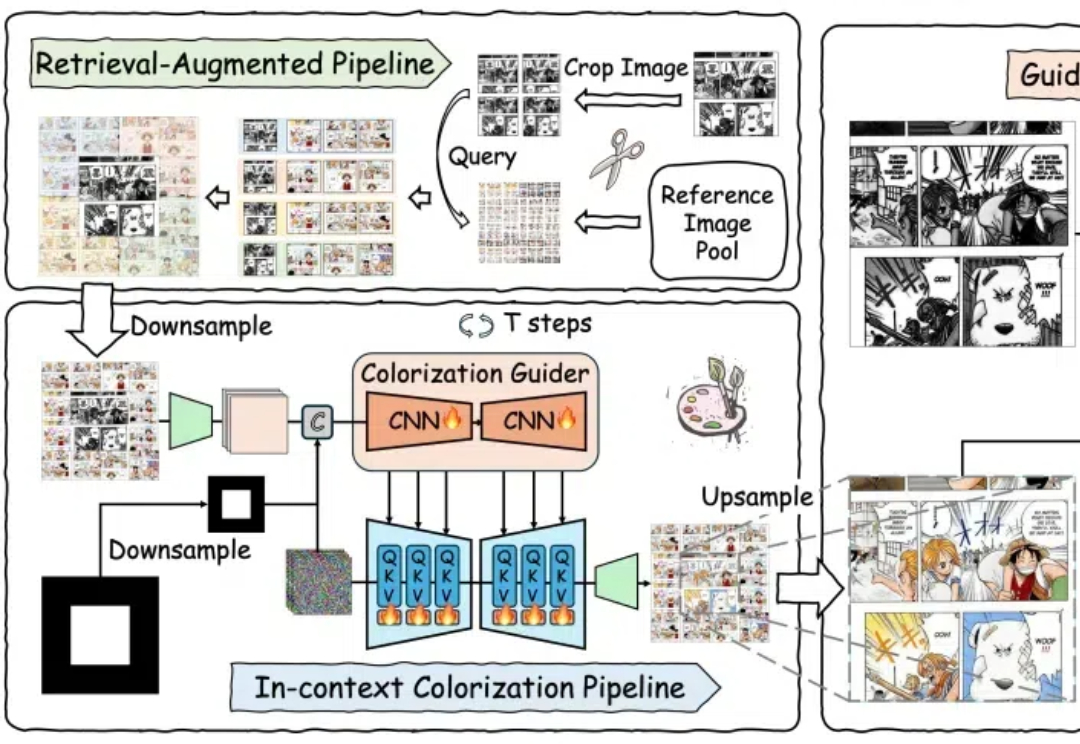
扩散模型在可控图像生成方面取得了空前进展,包括图像修补 ,图像着色和图像编辑。基于扩散模型的生成方案可以显著降低劳动力成本,尤其是在基于参考图像序列着色任务上,它可用于漫画创作,动画制作和黑白电影着色。