开学 AI 大礼包:OpenAI谷歌微软免费课程,从入门到精通,还有实战模板
开学 AI 大礼包:OpenAI谷歌微软免费课程,从入门到精通,还有实战模板现在做 AI 课程的,不计其数,吴恩达、Andrej Karpathy,Greg Isenberg 等人更是大神下凡支教。高校如斯坦福、MIT、哈佛等也有公开课资源。
来自主题: AI资讯
9504 点击 2025-09-03 11:53
 搜索
搜索
现在做 AI 课程的,不计其数,吴恩达、Andrej Karpathy,Greg Isenberg 等人更是大神下凡支教。高校如斯坦福、MIT、哈佛等也有公开课资源。
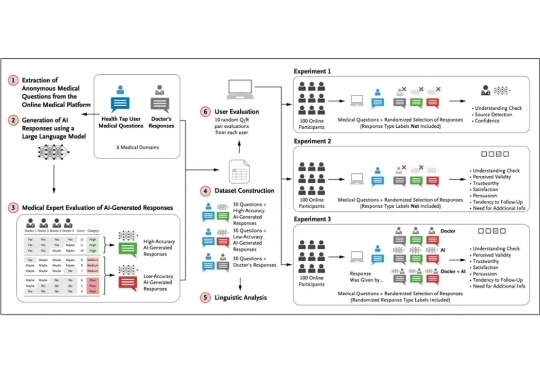
就连医生也未必能区分AI给出的建议与自己的建议 美国正面临医生短缺危机。在权威期刊《新英格兰医学杂志》10月刊中,哈佛医学院教授Isaac Kohane提到,马萨诸塞州是美国人均医生数量最多的州,但该州多家大型医院已拒绝接收新患者。
一名洗碗工,或者蓝领工人,竟然比牛津、哈佛名校出身的高级白领更吃香!「AI教父」Hinton预言成真了。在汹涌的AI风暴下,美国就业市场呈现两极分化:一面是白领遇冷,另一面是蓝领升温。作为身处AI浪潮下「迷失的一代」,美国Z世代大学生中的许多人,已开始转行做蓝领。
真正的 AI 系统不是一个 Chat 窗口,而是一个智能的工作现场。 工具越多,效率反而越低?一项来自《哈佛商业评论》的调查显示,员工每天平均切换应用程序超过 1200 次,一年下来累计浪费的时间高达 5 个完整工作周,占全年总工作时间的 9%。

几百年前开普勒通过观测数据,总结出了行星运动的规律,例如行星沿椭圆轨道运行,这让他能精确预测行星未来的位置。这就像今天的基础模型,通过学习海量数据,可以很好地进行序列预测(比如接下一句话)。
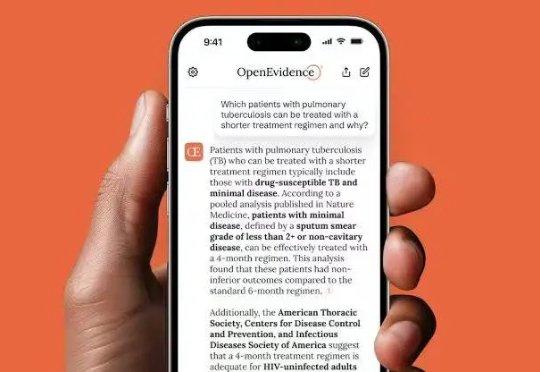
AI医疗的造富神话,又一次上演。近日,AI医疗公司OpenEvidence获得了2.1亿美元的B轮融资,估值飙升至35亿美元(约合人民币251亿元)。

Listen Labs 由两位哈佛校友 Florian Juengermann 与 Alfred Wahlforss 在 2024 年底联合创立,并在 2025 年 4 月连获 Sequoia 领投的种子轮与 A 轮合计 2700 万美元融资,目标是打造一套能自动招募受访者、主持上千场多语访谈、即时归档并复用洞察的“AI 用户研究员”体系。

本期《Upstream》对话 Roy Lee——Cluely 的联合创始人,也是当下最“出圈”的 Z 世代创业者。他的故事堪称反传统:从接连被哈佛、哥大被开除,到靠一个 AI 面试“作弊工具”做出 2.5 亿次曝光的爆款原型。

What?LLM也要看出身!确实,不同的数据集训出的模型“个性”会有大不同,尤其在加之权衡方面。这就像我们经常与自己内心相互竞争的目标和价值观作斗争。
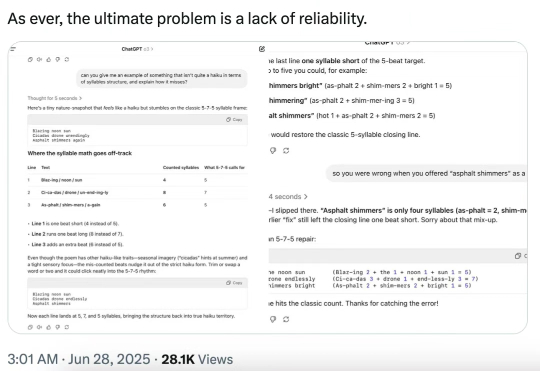
今天,著名的人工智能学者和认知科学家 Gary Marcus 转推了 MIT、芝加哥大学、哈佛大学合著的一篇爆炸性论文,称「对于 LLM 及其所谓能理解和推理的神话来说,情况变得更糟了 —— 而且是糟糕得多。」