
RAG效果不理想,怎么优化?Recall太低,是Milvus的问题吗?
RAG效果不理想,怎么优化?Recall太低,是Milvus的问题吗?RAG 系统上线后答案出错,绝大多数团队的第一反应都是换更贵的模型、反复调试 prompt。
来自主题: AI技术研报
5847 点击 2026-05-20 15:13
 搜索
搜索
RAG 系统上线后答案出错,绝大多数团队的第一反应都是换更贵的模型、反复调试 prompt。

jina-embeddings-v5-omni正式发布,我们把 v5-text 向量模型的能力延伸到图像、音频和视频。文本侧不变,v5-omni 产出的文本向量与 v5-text逐字节一致,无需重建任何已有索引。
前几天在 Milvus 社区,一位做以图搜图的朋友提了一个问题:
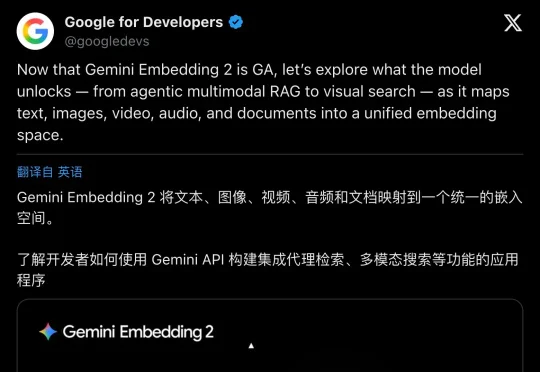
Google悄悄干了一件大事——Gemini Embedding 2正式进入GA阶段,成为Gemini API中第一个原生多模态embedding模型。它能把文本、图片、视频、音频、PDF文档全部映射进同一个统一向量空间,支持100多种语言。
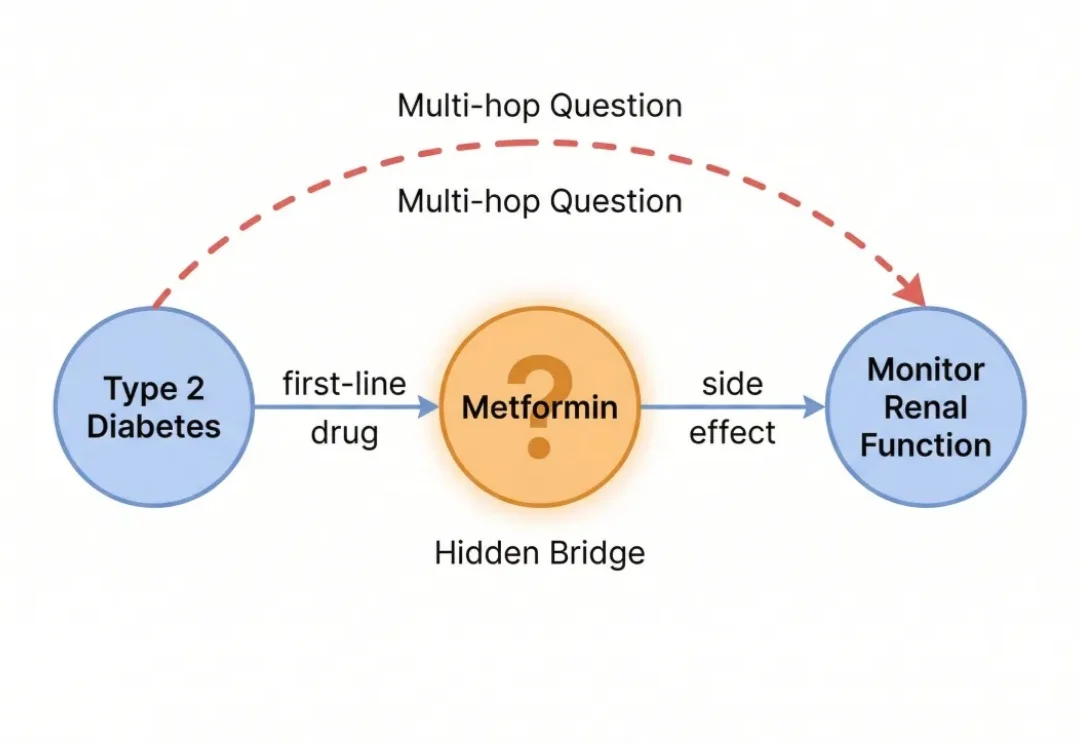
做 RAG 多跳问答的朋友,应该没有人还没被图数据库PUA 过。
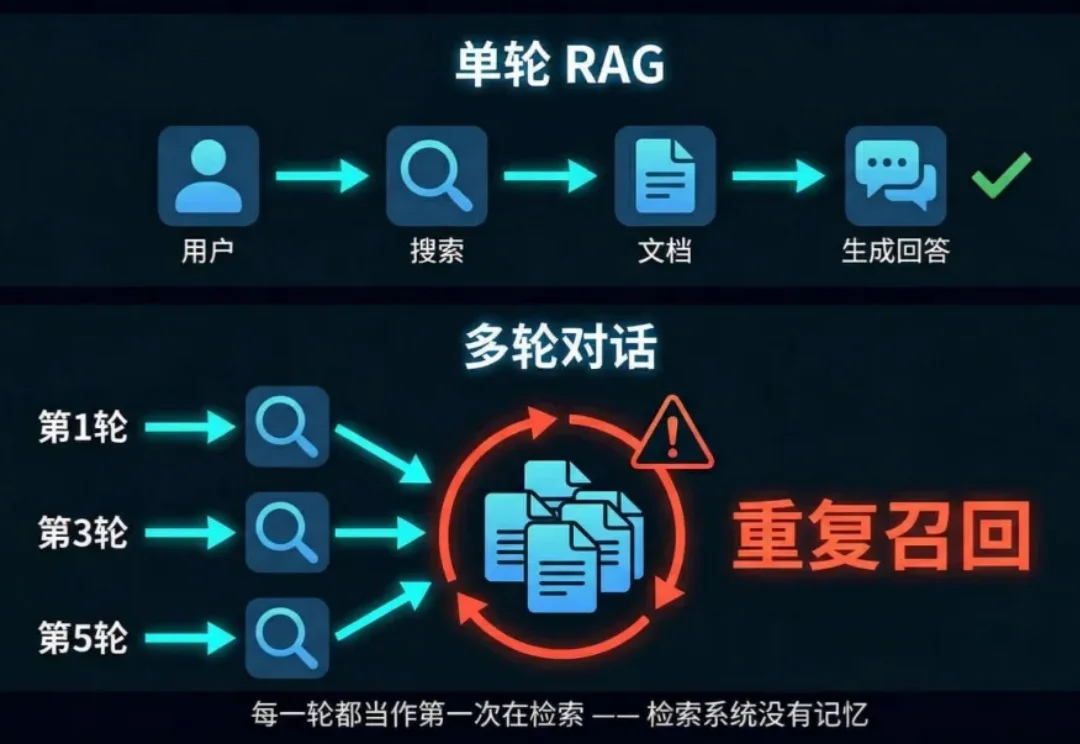
做 RAG 的团队,基本都会在多轮对话上吃过亏。

AI产品、生态协同双升级,中兴通讯交出战略升级满新答卷。

近日,哈尔滨工业大学(深圳)联合深圳河套学院、Independent Researcher提出了隐式思考模型 LRT(Latent Reasoning Tuning),通过一个轻量级的推理网络,将大模型冗长的「思维链」压缩为紧凑的隐式向量表征,一次前向计算即可完成推理,无需逐 token 生成数千字的中间推理过程。
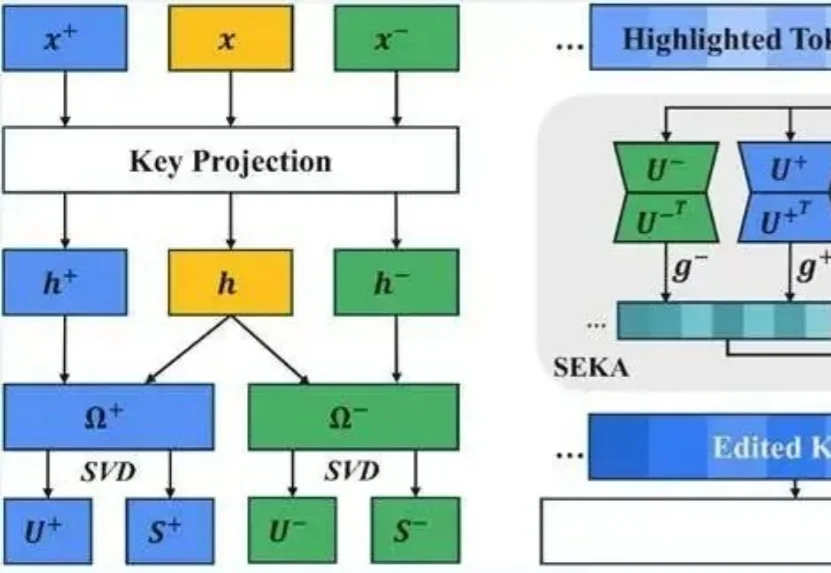
想让大模型重点关注提示词里的某句话可没那么容易。

在此背景下,浙江大学研究团队提出了 EasySteer——一个基于 vLLM 构建的高性能、可扩展 LLM Steering 统一框架。该框架通过与 vLLM 推理引擎的深度集成,相比现有 Steering 框架实现了 10.8-22.3 倍的推理加速,同时提供更细粒度的干预控制,并为八大应用场景提供了预计算 Steering 向量与完整复现示例,方便研究者快速上手和对照复现。