
谷歌一篇论文引爆存储芯片崩盘!AI内存需求暴降6倍,推理狂飙8倍
谷歌一篇论文引爆存储芯片崩盘!AI内存需求暴降6倍,推理狂飙8倍谷歌一篇论文,直接让存储巨头们「集体失眠」,一夜市值蒸发几百亿!最新博客官宣TurboQuant算法,直接将缓存压到3-bit,内存占用只有1/6。
来自主题: AI资讯
8990 点击 2026-03-26 12:01
 搜索
搜索
谷歌一篇论文,直接让存储巨头们「集体失眠」,一夜市值蒸发几百亿!最新博客官宣TurboQuant算法,直接将缓存压到3-bit,内存占用只有1/6。
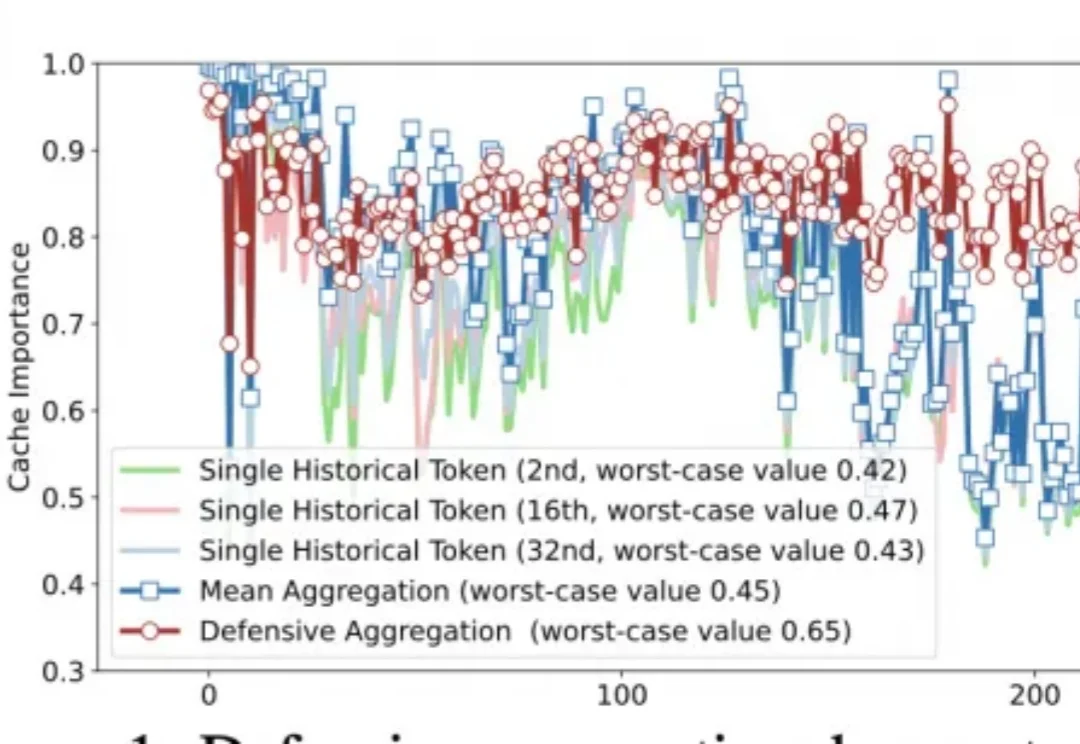
随着大模型长上下文能力快速增长,海量 KV Cache 存储需求急剧增加,各类 KV Cache 压缩方法如雨后春笋般涌现。然而,这些方案在真实场景中的工程落地却常常陷入困境。

我们在很多地方都看到了一个词,叫「压缩即智能」
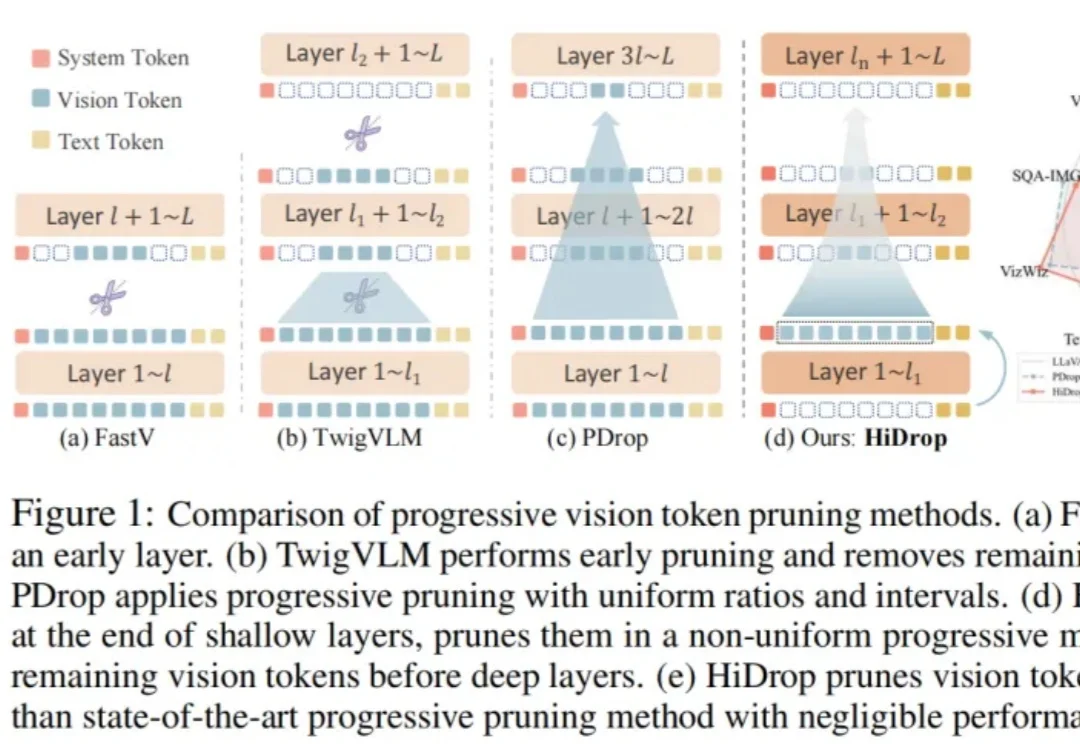
随着多模态大语言模型(MLLM)支持更长上下文,高分辨率图像和长视频会产生远多于文本的视觉 Token,在自注意力二次复杂度下迅速成为效率瓶颈。
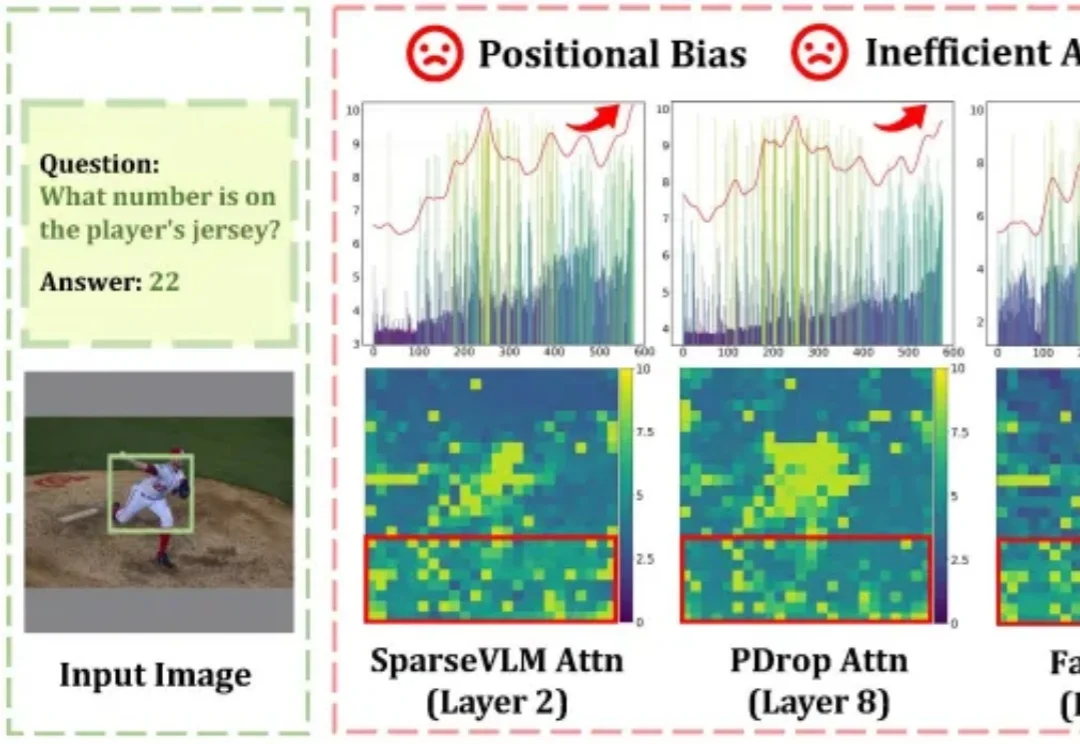
随着高分辨率图像理解与长视频处理需求的爆发式增长,大型视觉语言模型(LVLMs)所需处理的视觉 Token 数量急剧膨胀,推理效率成为落地部署的核心瓶颈。Token 压缩是缩短序列、提升吞吐的直接手段,但现有方法普遍依赖注意力权重来判断 Token 重要性,这一路线暗藏两个致命缺陷:
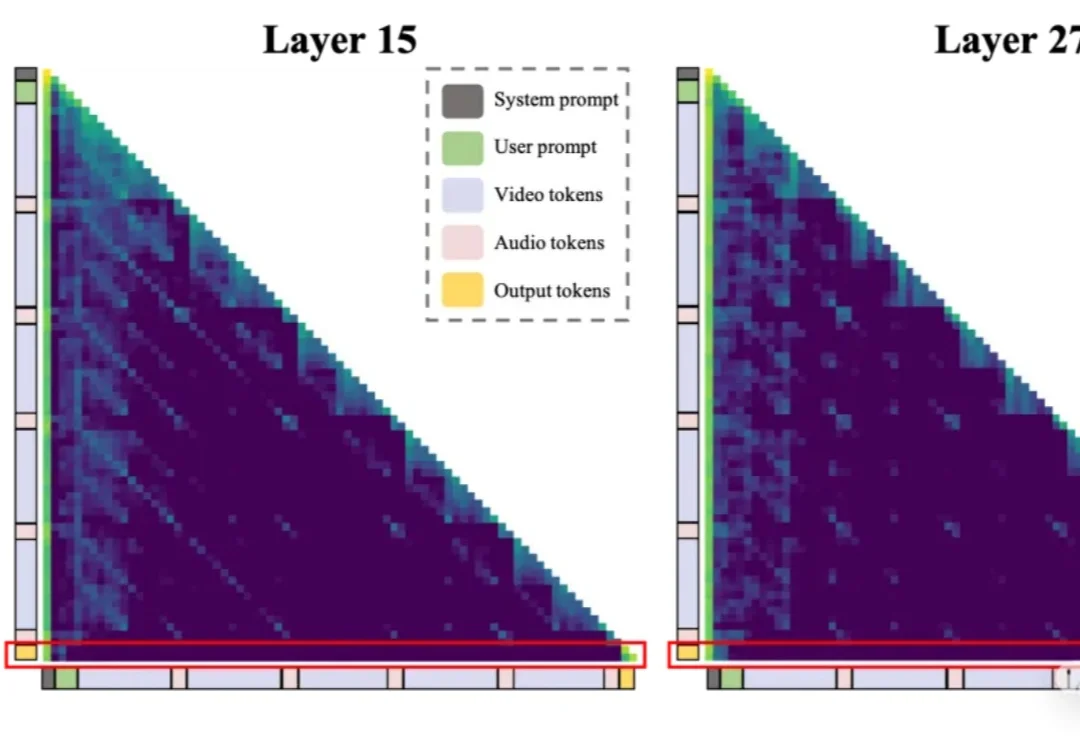
一段几十秒的音视频,上万Token,一半以上是冗余——Omni-LLM的计算浪费,比想象中更严重。

基础模型时代,大模型能力的爆发,很大程度上源于在海量文本上的预训练。然而问题在于,文本本质上只是人类对现实世界的一种抽象表达,是对真实世界信息的有损压缩。
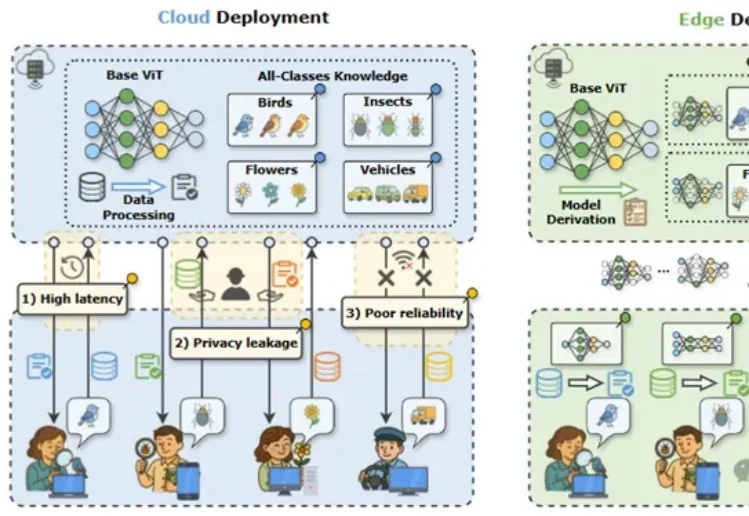
近年来,视觉大模型在自动驾驶、智慧医疗等场景中得到广泛应用,但在真实业务环境中,“大而全”的通用模型往往并不是最优选择。

长期以来,计算机视觉领域陷入了一个 “表征(Representation)” 的执念。我们习惯设计各种精巧的 Encoder,试图将动态世界压缩成一组特征向量。然而,视频作为现实的高维投影,其熵值之高、动态之复杂,让这种试图 “定格” 的表征显得力不从心。
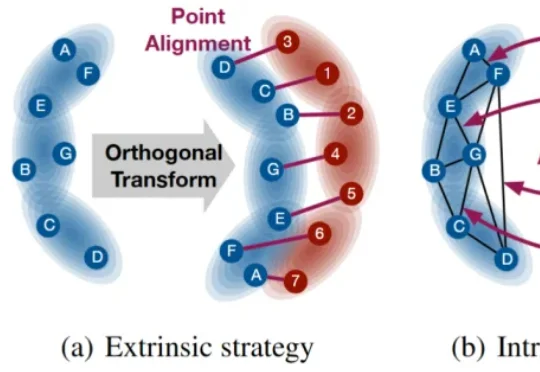
本文提出一种具有 SE(p) 不变传输性质的度量 SEINT:通过构造无需训练的 SE(p) 不变表示,将高维结构信息压缩为可用于 Optimal Transport (OT) 对齐的一维表征,从而在保持不变性与严格度量性质的同时显著提升效率。