李开复力推DeepSeek!零一万物发布模型一体机,搭载华为GPU,自家产品也全线替换了
李开复力推DeepSeek!零一万物发布模型一体机,搭载华为GPU,自家产品也全线替换了第一家全面拥抱DeepSeek的“六小虎”,出现了! 不卖关子,它就是李开复亲任CEO的零一万物。 今日正式上线万智企业大模型一站式平台,宣布提供企业级DeepSeek部署定制解决方案。
来自主题: AI资讯
8770 点击 2025-03-17 21:38
 搜索
搜索
第一家全面拥抱DeepSeek的“六小虎”,出现了! 不卖关子,它就是李开复亲任CEO的零一万物。 今日正式上线万智企业大模型一站式平台,宣布提供企业级DeepSeek部署定制解决方案。

傍上中国移动和华为两个“大哥”, 乐聚人形机器人迎来“智变”。
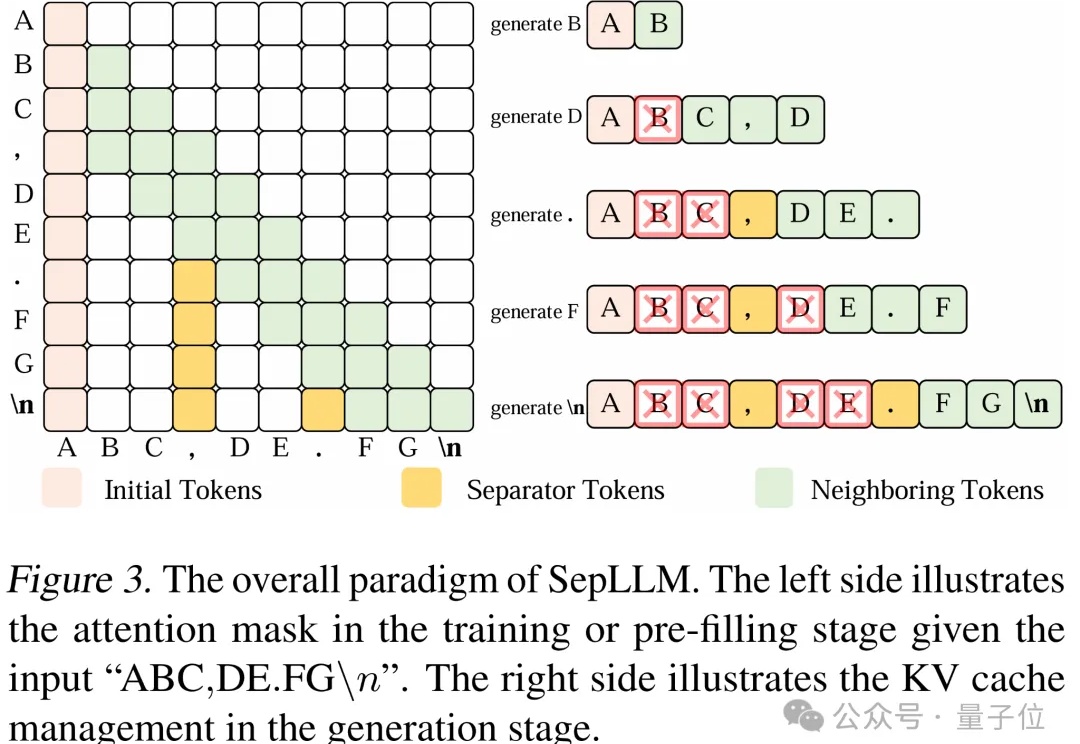
文字中貌似不起眼的标点符号,竟然可以显著加速大模型的训练和推理过程?

国内芯片设计研究团队,刚刚在国际学术顶会上获奖了。

国产GPU适配DeepSeek,商用前景广阔。

近年来,AI成为了国内手机市场上的最大热点。根据市研机构IDC的定义,AI手机有几个关键指标和特性:算力大于30TOPS的NPU、支持生成式AI模型的SoC、可以端侧运行各种大模型。而就在过去一年,国内AI手机市场迅猛发力。华为、小米、vivo、OPPO、荣耀等手机厂商,均已迅速在旗下产品上接入各自的云端或端侧AI大模型。

2月18日,上海交通大学医学院附属瑞金医院举办了“2025医疗人工智能与精准诊疗发展论坛”,瑞金医院携手华为共同发布瑞智病理大模型RuiPath。

DeepSeek掀起的算力热潮还在持续。中国电信昨日宣布推出了息壤智算一体机-DeepSeek版,在硬件层面以华为昇腾芯片为基础,提供8卡、16卡、32卡等多种规格型号。此前,京东云也发布DeepSeek大模型一体机,支持华为昇腾、海光、寒武纪、摩尔线程、天数智芯等国产AI加速芯片。《科创板日报》了解到,华鲲振宇也推出了DeepSeek大模型一体机方案。

“春节回来,咨询融科的客户多了很多很多。”DeepSeek爆红后,其研发团队所在的北京融科资讯中心也意外火了起来。投资界获悉,DeepSeek北京办公室还将迎来一位新邻居——此前华为租下数千平方米面积,正在装修。
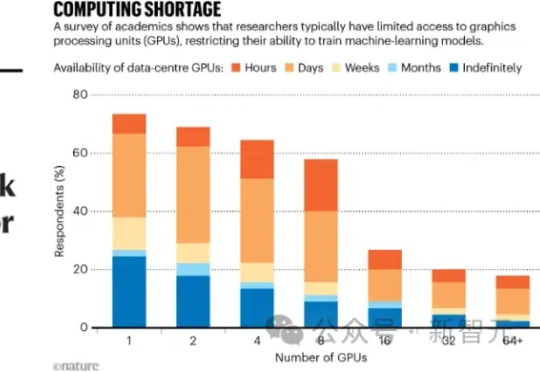
梁文峰说,钱从来都不是问题,唯一担心的是缺算力。不过,基于国产昇腾算力的DeepSeek R1系列推理API,性能已经直接对标高端GPU了!而且,华为已经率先携手国内15所头部高校,打造出了独一份的科教创新卓越/孵化中心,通过产教融合、科教融汇破解高校科研的算力困局。