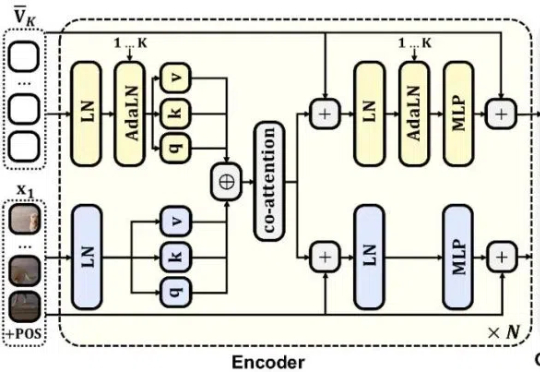
图像分词器造反了!华为 Selftok:自回归内核完美统一扩散模型,触发像素自主推理
图像分词器造反了!华为 Selftok:自回归内核完美统一扩散模型,触发像素自主推理自回归(AR)范式凭借将语言转化为离散 token 的核心技术,在大语言模型领域大获成功 —— 从 GPT-3 到 GPT-4o,「next-token prediction」以简单粗暴的因果建模横扫语言领域。
来自主题: AI技术研报
9592 点击 2025-05-18 14:28
 搜索
搜索
自回归(AR)范式凭借将语言转化为离散 token 的核心技术,在大语言模型领域大获成功 —— 从 GPT-3 到 GPT-4o,「next-token prediction」以简单粗暴的因果建模横扫语言领域。

昨晚,美商务部正式废止《AI扩散规则》,同时加码全球半导体出口管制,精准打击中国AI发展。发布指导意见,在世界任何地方使用华为AI芯片,都违反美国出口管制。 警告公众当美国AI芯片被用于训练/推理中国AI模型时的潜在后果。向美国公司发布关于如何保护供应链免受转移策略影响的指导意见。
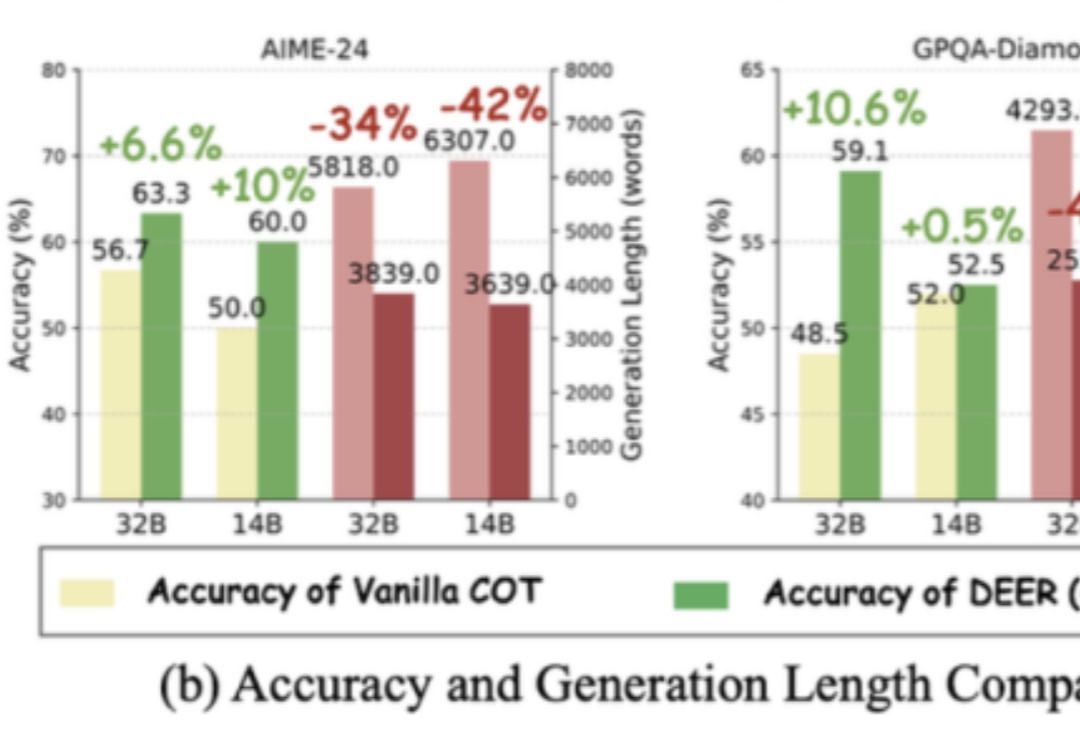
长思维链让大模型具备了推理能力,但如果过度思考,就有可能成为负担。

华为哈勃首次投资机器人公司千寻智能,5月将发新Demo。

央企通信巨头,牵头搞起了一个开源社区?

现在,跑准万亿参数的大模型,可以彻底跟英伟达Say Goodbye了。
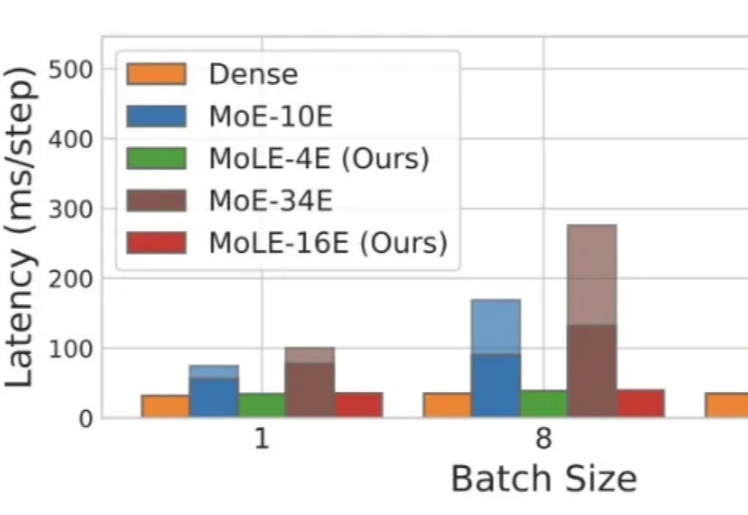
Mixture-of-Experts(MoE)在推理时仅激活每个 token 所需的一小部分专家,凭借其稀疏激活的特点,已成为当前 LLM 中的主流架构。然而,MoE 虽然显著降低了推理时的计算量,但整体参数规模依然大于同等性能的 Dense 模型,因此在显存资源极为受限的端侧部署场景中,仍然面临较大挑战。
英伟达H20也不能用了。中国大模型还能好吗?
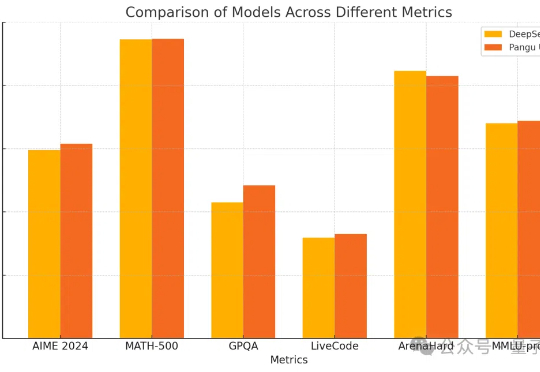
密集模型的推理能力也能和DeepSeek-R1掰手腕了?
一切为了「多终端一致体验」和「用户数据闭环」。