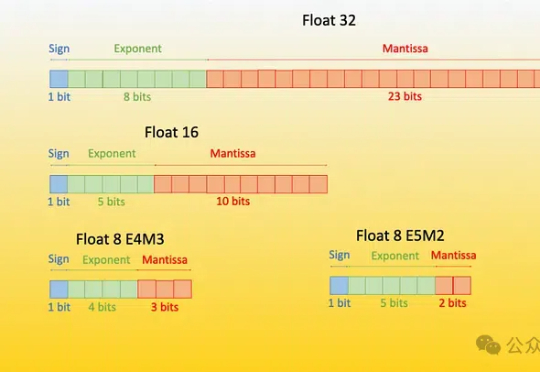
微软再放LLM量化大招!原生4bit量化,成本暴减,性能几乎0损失
微软再放LLM量化大招!原生4bit量化,成本暴减,性能几乎0损失原生1bit大模型BitNet b1.58 2B4T再升级!微软公布BitNet v2,性能几乎0损失,而占用内存和计算成本显著降低。
来自主题: AI技术研报
9736 点击 2025-06-02 18:00
 搜索
搜索
原生1bit大模型BitNet b1.58 2B4T再升级!微软公布BitNet v2,性能几乎0损失,而占用内存和计算成本显著降低。
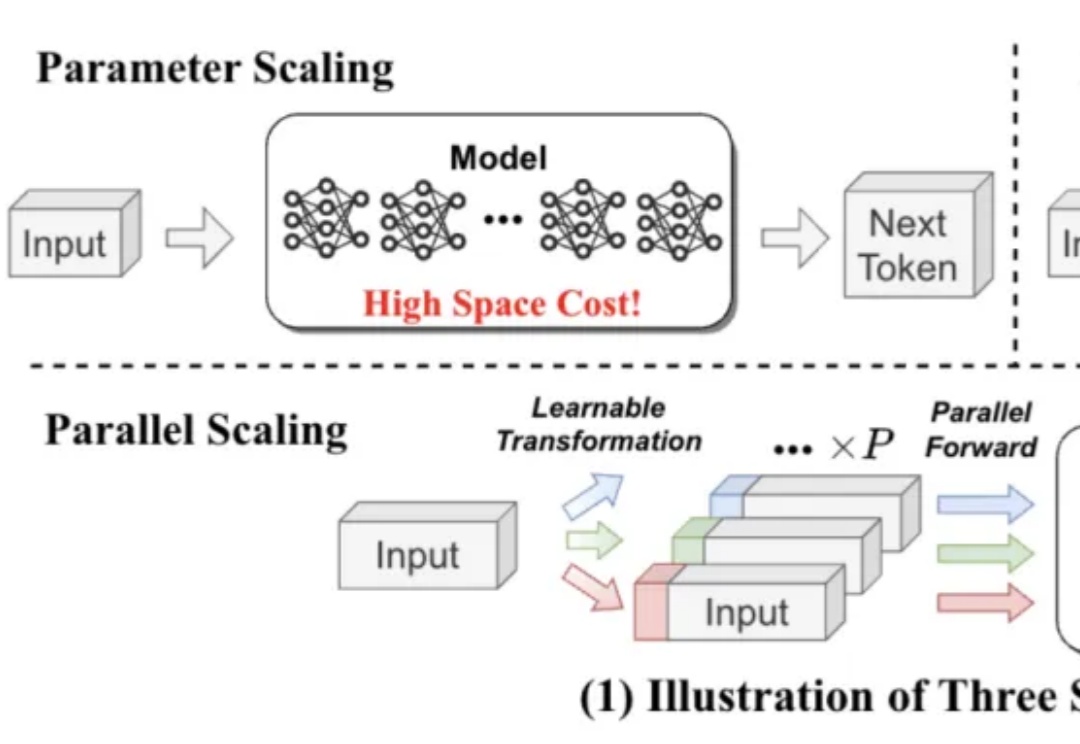
既能提升模型能力,又不显著增加内存和时间成本,LLM第三种Scaling Law被提出了。
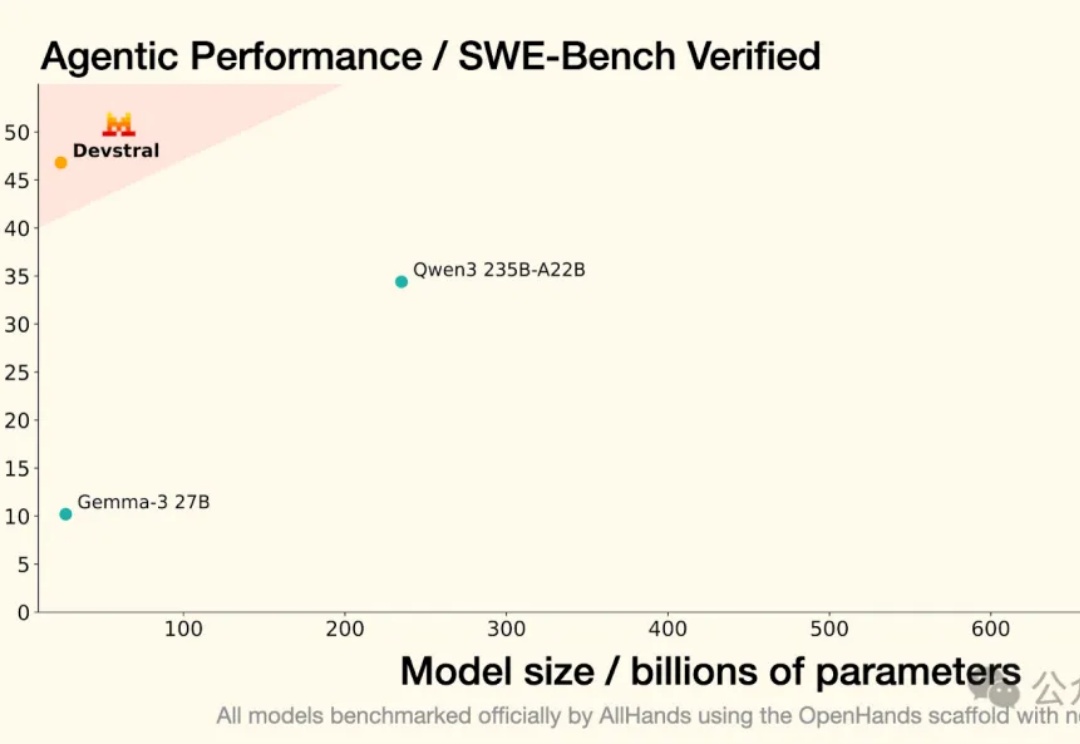
Mistral沉默好久,果然在憋大招。
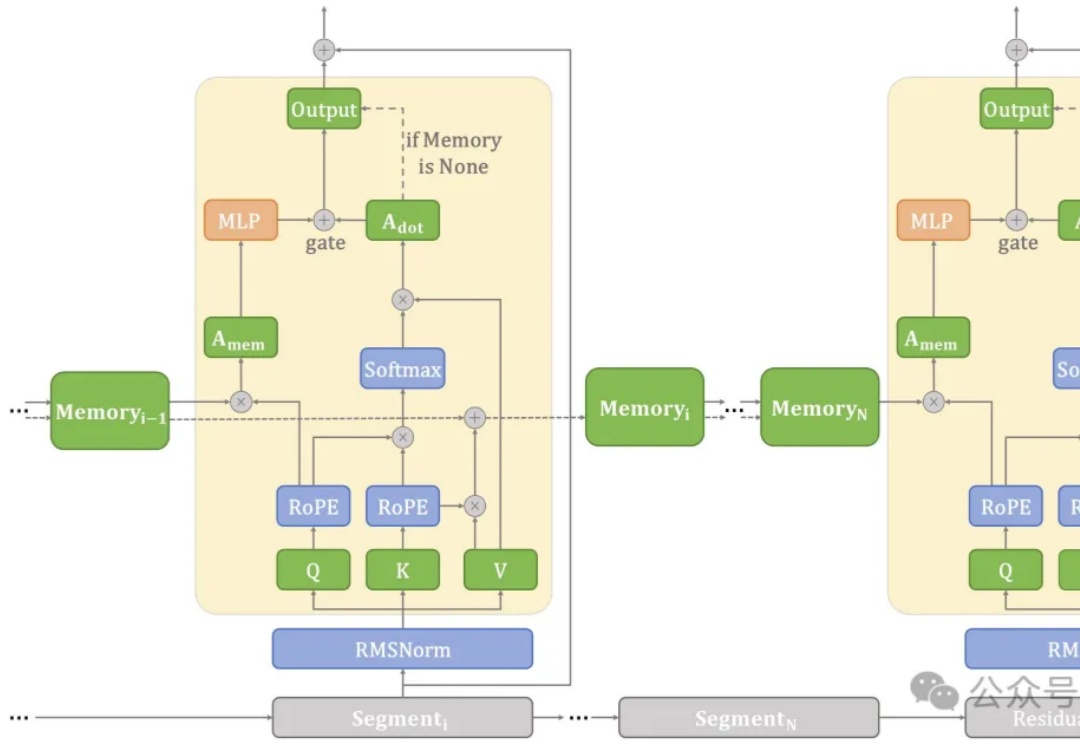
在端侧设备上处理长文本常常面临计算和内存瓶颈。

英伟达官宣新办公室落户中国台湾省台北市,但居然是从太空飞下来的吗?

DeepSeek最新论文深入剖析了V3/R1的开发历程,揭示了硬件与大语言模型架构协同设计的核心奥秘。论文展示了如何突破内存、计算和通信瓶颈,实现低成本、高效率的大规模AI训练与推理。不仅总结了实践经验,还为未来AI硬件与模型协同设计提出了建议。
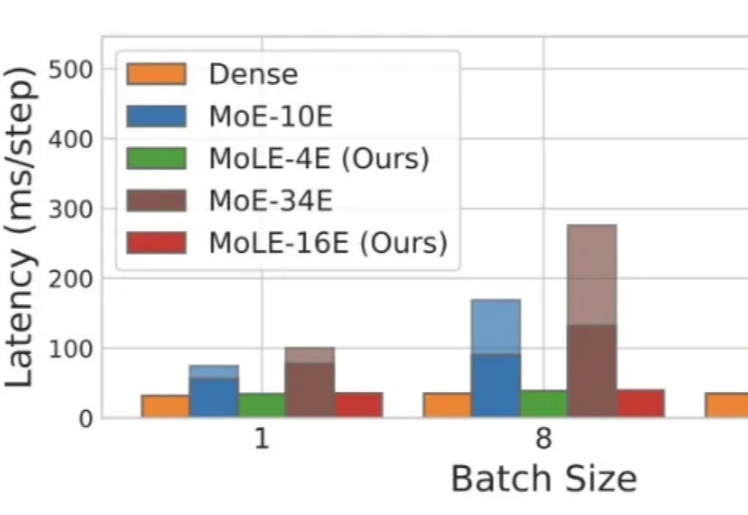
Mixture-of-Experts(MoE)在推理时仅激活每个 token 所需的一小部分专家,凭借其稀疏激活的特点,已成为当前 LLM 中的主流架构。然而,MoE 虽然显著降低了推理时的计算量,但整体参数规模依然大于同等性能的 Dense 模型,因此在显存资源极为受限的端侧部署场景中,仍然面临较大挑战。

微软研究院开源的原生1bit大模型BitNet b1.58 2B4T,将低精度与高效能结合,开创了AI轻量化的新纪元。通过精心设计的推理框架,BitNet不仅突破了内存的限制,还在多项基准测试中表现出色,甚至与全精度模型不相上下。

3月末,多家海外存储头部企业,宣布从4月起提高部分产品报价,国内厂商也随之上调价格,终结了DRAM内存与NAND闪存的降价势头。

在大模型争霸的时代,算力与效率的平衡成为决定胜负的关键。