Mac用户可以在oMLX中使用TurboQuant了,搭配Gemma-4-31B,谷歌全家桶实测很能打!
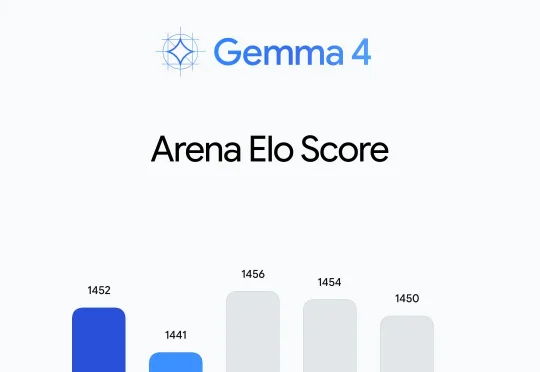
Mac用户可以在oMLX中使用TurboQuant了,搭配Gemma-4-31B,谷歌全家桶实测很能打!对本地部署玩家,尤其是Mac用户来说,长上下文推理最大的痛点往往不是“模型不够聪明”,而是稍微多用点上下文,统一内存就被撑爆了”,这一点在最近的Gemma-4 31B的部署中尤为明显,在同等上下文的情况,显存占用比Qwen3.5-27B高约一倍不止,直接劝退了不少人。但好消息是,谷歌近期提出的TurboQuant KV缓存量化算法,正是为了解决这个痛点而生。
来自主题: AI技术研报
8603 点击 2026-04-09 09:47