全球最大开源具身大模型!中国机器人跑完马拉松后开始学思考
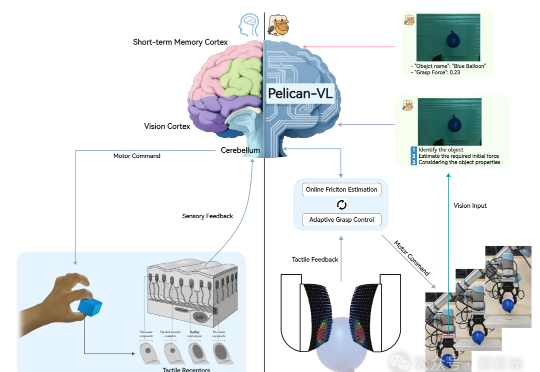
全球最大开源具身大模型!中国机器人跑完马拉松后开始学思考昨天,全球参数量最大的具身智能多模态大模型——Pelican-VL 1.0正式开源。它不仅覆盖了7B到72B级别,能够同时理解图像、视频和语言指令,并将这些感知信息转化为可执行的物理操作。
来自主题: AI资讯
9344 点击 2025-11-15 10:18
 搜索
搜索
昨天,全球参数量最大的具身智能多模态大模型——Pelican-VL 1.0正式开源。它不仅覆盖了7B到72B级别,能够同时理解图像、视频和语言指令,并将这些感知信息转化为可执行的物理操作。

近期,Google DeepMind 发布新一代具身大模型 Gemini Robotics 1.5,其核心亮点之一便是被称为 Motion Transfer Mechanism(MT)的端到端动作迁移算法 —— 无需重新训练,即可把不同形态机器人的技能「搬」到自己身上。不过,官方技术报告对此仅一笔带过,细节成谜。

在具身智能领域,视觉 - 语言 - 动作(VLA)大模型正展现出巨大潜力,但仍面临一个关键挑战:当前主流的有监督微调(SFT)训练方式,往往让模型在遇到新环境或任务时容易出错,难以真正做到类人般的泛化
近日,前字节跳动 AI 技术专家解浚源在朋友圈官宣加入具身智能创业公司千寻智能,并发布了千寻智能最新披露的 Spirit v1 VLA 演示视频。据悉,解浚源目前任职千寻智能具身智能部负责人,全面负责具身大模型的研发工作。

今天,银河通用机器人发布了端到端具身抓取基础大模型「GraspVLA」,全球第一个预训练完全基于仿真合成大数据的具身大模型,展现出了比OpenVLA、π0、RT-2、RDT等模型更全面强大的泛化性和真实场景实用潜力。
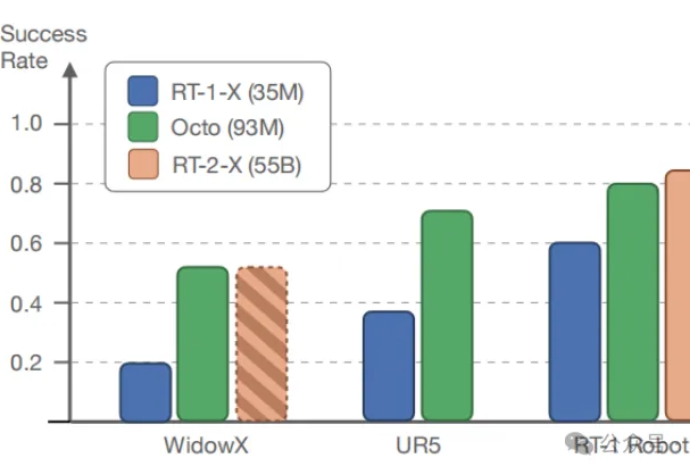
在多样化的机器人数据集上预训练的大型策略有潜力改变机器人学习:与从头开始训练新策略相比,这种通用型机器人策略可以通过少量的领域内数据进行微调,同时具备广泛的泛化能力。

近日,关于 Open AI 被投企业 Physical Intelligence (PI) 的一系列报道,让人们关注到具身智能大模型引发的机器人时代变革。

2024年中关村仿生机器人大赛,今日正式启动!无论是人形仿生机器人、具身大模型、多足仿生机器人,甚至只是仿生灵巧手,统统可以报名了。评委由两院院士坐镇,奖金池更是高达255万!这两位正撸猫和原地弹跳的选手,已经是摩拳擦掌了。

只靠一张物体图片,大语言模型就能控制机械臂完成各种日常物体操作吗?