首个为具身智能而生的大规模强化学习框架RLinf!清华、北京中关村学院、无问芯穹等重磅开源
首个为具身智能而生的大规模强化学习框架RLinf!清华、北京中关村学院、无问芯穹等重磅开源清华大学、北京中关村学院、无问芯穹联合北大、伯克利等机构重磅开源RLinf:首个面向具身智能的“渲训推一体化”大规模强化学习框架。
来自主题: AI技术研报
7654 点击 2025-09-01 16:49
 搜索
搜索
清华大学、北京中关村学院、无问芯穹联合北大、伯克利等机构重磅开源RLinf:首个面向具身智能的“渲训推一体化”大规模强化学习框架。

姚班、伯克利、OpenAI、清华……年仅 30 多岁的吴翼身上已经聚集了众多亮眼的标签。

想象一个课堂:讲台上是永不疲倦的AI讲师,台下是专注于启发和引导的人类导师。本期播客,听听他们关于AI如何重塑教育、老师角色以及适应力为何是新一代职业保障的深刻洞见。

你有没有想过,营销这件事可能彻底变了?两个24岁的UC Berkeley辍学生,刚刚拿到2800万美元融资,要挑战Salesforce和Adobe这样的巨头。他们的武器很简单:用AI让营销软件不再是企业的噩梦,而是真正能解决问题的工具。

陈建宇(星动纪元创始人)、高阳(千寻智能联合创始人)、吴翼(蚂蚁集团强化学习实验室首席科学家)、许华哲(星海图联合创始人)的分享(题图从左至右),基本代表了国内具身智能领域最先进的成果展示。
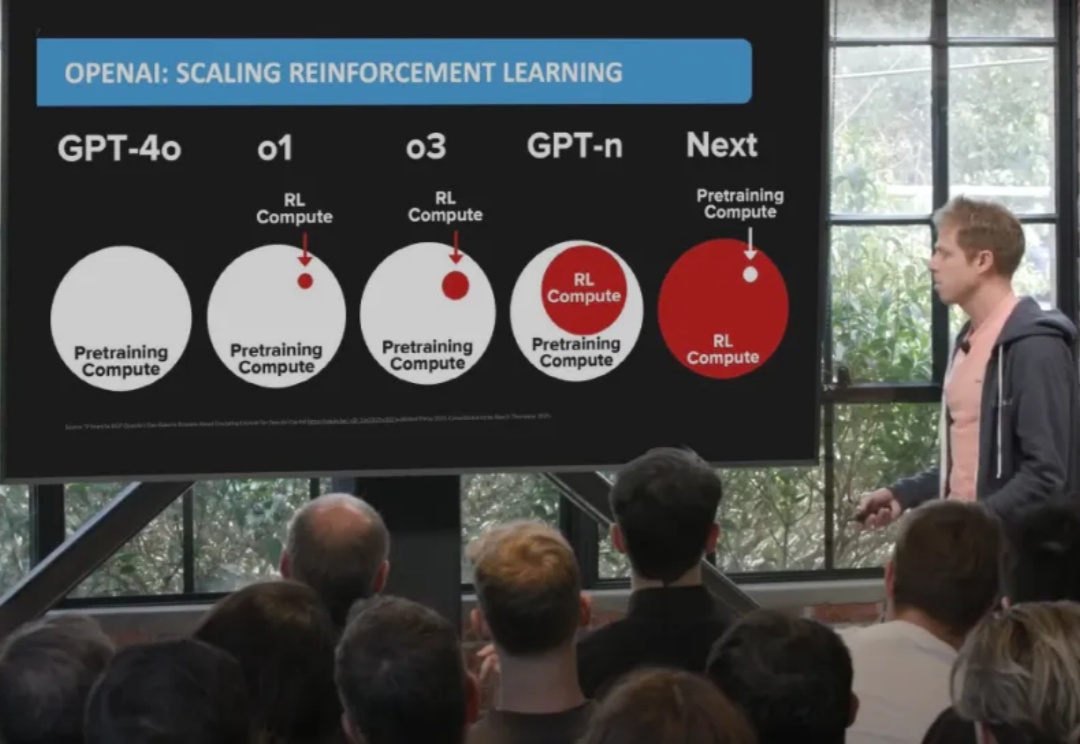
如今,强化学习(Reinforcement Learning,RL)在多个领域已取得显著成果。

GPT-4o引爆全球「吉卜力风格」风潮后,其核心成员——华南理工学霸Lu Liu与伯克利博士Allan Jabri——双双跳槽Meta,两人曾在OpenAI主导多模态AI研究,与奥特曼同台展示关键功能。此次挖角再次凸显OpenAI内部动荡后的人才流失危机。

新晋AI编程冠军DeepSWE来了!仅通过纯强化学习拿下基准测试59%的准确率,凭啥?7大算法细节首次全公开。
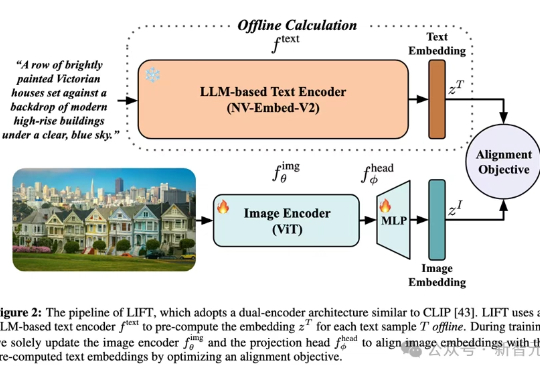
多模态对齐模型借助对比学习在检索与生成任务中大放异彩。最新趋势是用冻结的大语言模型替换自训文本编码器,从而在长文本与大数据场景中降低算力成本。LIFT首次系统性地剖析了此范式的优势来源、数据适配性、以及关键设计选择,在组合语义理解与长文本任务上观察到大幅提升。

几十年来,人工智能领域一直在思考一个看似简单但非常根本的问题: 如果一个智能体要在真实世界中行动、规划,并且和环境互动,它需要一个怎样的「世界模型」?