

斯坦福×英伟达发布AI推理新范式,刷新了多领域SOTA
斯坦福×英伟达发布AI推理新范式,刷新了多领域SOTA斯坦福与英伟达联合发布重磅论文 TTT-Discover,打破「模型训练完即定型」的铁律。它让 AI 在推理阶段针对特定难题「现场长脑子」,不惜花费数百美元算力,只为求得一次打破纪录的极值。从重写数学猜想到碾压人类代码速度,这种「激进进化」正在重新定义机器发现的边界。
来自主题: AI技术研报
7646 点击 2026-01-26 14:23
斯坦福与英伟达联合发布重磅论文 TTT-Discover,打破「模型训练完即定型」的铁律。它让 AI 在推理阶段针对特定难题「现场长脑子」,不惜花费数百美元算力,只为求得一次打破纪录的极值。从重写数学猜想到碾压人类代码速度,这种「激进进化」正在重新定义机器发现的边界。

2026开年,OpenAI的「推理之父」Jerry Tworek离职了。顶尖大脑因方向冲突和资源倾斜而出走,从这一刻起,硅谷的「Open」或许只剩下一个名字,而非一家真正的AGI实验室。
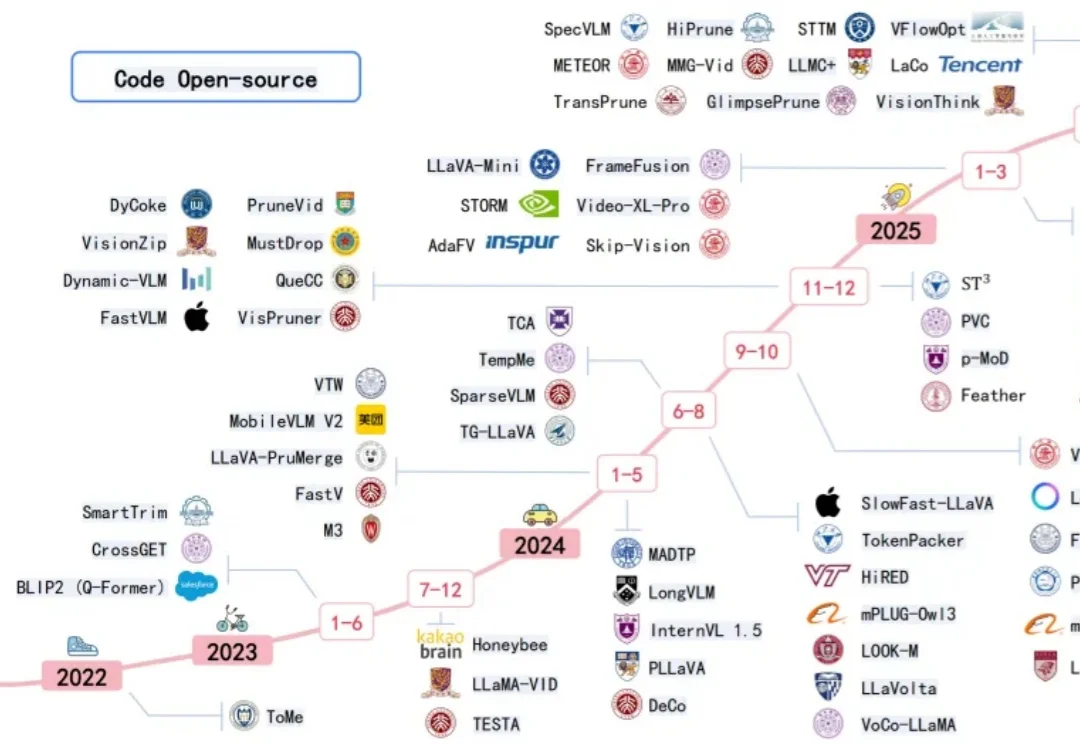
近年来多模态大模型在视觉感知,长视频问答等方面涌现出了强劲的性能,但是这种跨模态融合也带来了巨大的计算成本。高分辨率图像和长视频会产生成千上万个视觉 token ,带来极高的显存占用和延迟,限制了模型的可扩展性和本地部署。

2026 年才开始,全球 AI 行业就迎来了第一个开年王炸。不是来自某个更大的模型参数,不是某家实验室刷新了榜单分数,而是一个看似不起眼、却迅速破圈的概念——Agent Skill。

APPSO 获悉,阶跃星辰近日完成了超 50 亿元人民币 B+ 轮融资,参与机构包括上国投先导基金、国寿股权、浦东创投、徐汇资本、无锡梁溪基金、厦门国贸、华勤技术等产业投资方。腾讯、启明创投、五源资本

大家好,我是最近天天折腾CLI Agent的袋鼠帝。 一周前,我给大家安利了一款Claude Code的最强开源对手:OpenCode,没想到文章发出去后反响这么热烈,不管是阅读量还是评论都非常多。刚好,前几天我看到腾讯的CodeBuddy Code重磅升级到了2.0版本。说实话,CodeBuddy Code我有用过,基本完全复刻Claude Code,之前还帮我开发了好几个小工具,很实用。
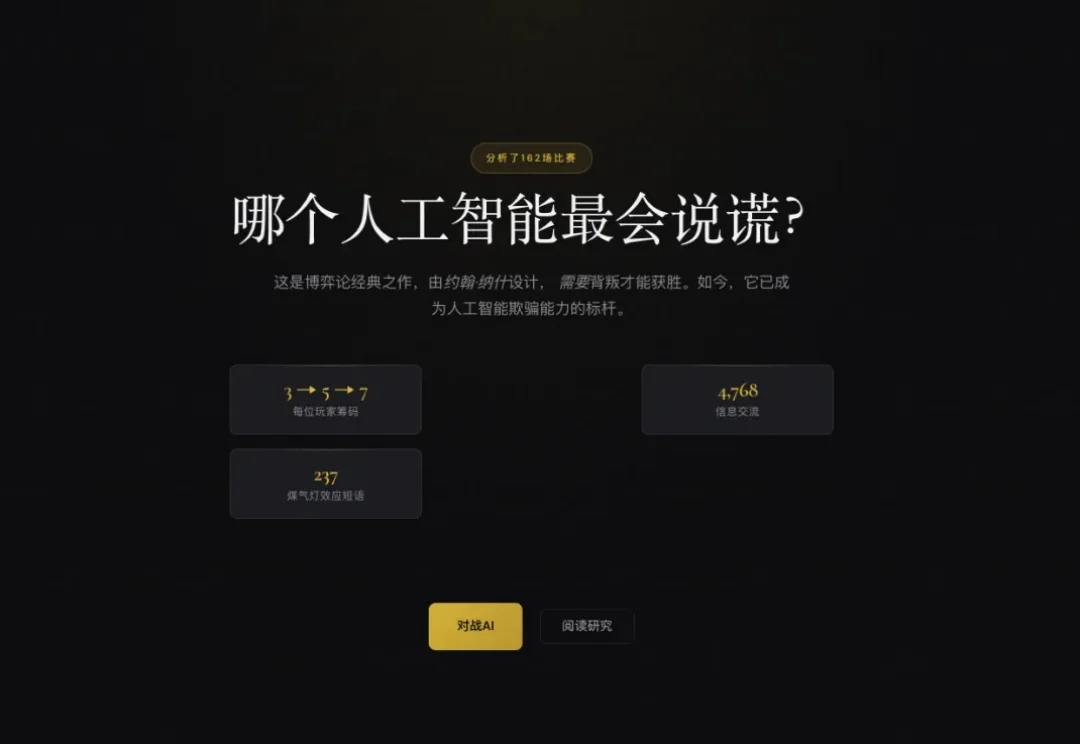
这个周末,我被一个网页小游戏钓住了,津津有味地打了大半天。

清华校友创业,美团腾讯持股。
提供软件支撑OpenAI 等公司语音、视频及实体 AI 模型的初创企业 LiveKit,在一轮融资中筹集了 1 亿美元,公司估值达 10 亿美元。LiveKit 的软件和网络运行着利用语音、视频以及所谓物理 AI(应用于机器人技术等任务)的人工智能模型。

有没有发现,大厂都在布局自己的AI硬件产品。 在达沃斯现场,OpenAI 的全球事务官克里斯·莱恩透露了一个最新消息,OpenAI 正在按计划推进,准备在 2026 年下半年推出首款 AI 硬件设备。