
云九资本袁语:“投 AI,最重要是找到天庭下凡的人”
云九资本袁语:“投 AI,最重要是找到天庭下凡的人”袁语2016年清明节后在九合创投拿到第一份投资工作,跟着王啸干,投的第一个项目就是VUE——一个帮普通人拍出好视频的创作工具。他说自己一直对"像钢琴一样的东西"着迷,那种能激发创造力的工具。
来自主题: AI资讯
8228 点击 2026-07-08 09:45
 搜索
搜索
袁语2016年清明节后在九合创投拿到第一份投资工作,跟着王啸干,投的第一个项目就是VUE——一个帮普通人拍出好视频的创作工具。他说自己一直对"像钢琴一样的东西"着迷,那种能激发创造力的工具。
7月7日,Fable 5没下线!就在凌晨,Anthropic突然官宣, 最强Claude Fable 5限时免费,延长到了7月12日。比原计划,又多了足足五天的「白嫖」时间。具体用法,和之前一模一样,每周使用限额50%,超出之后想继续用,就得买credits了。

今天,据路透社报道,三位知情人士透露,DeepSeek正在自研AI推理芯片,以减少对英伟达以及华为芯片的依赖。知情人士称,DeepSeek自研芯片的工作大约在一年前启动,其研发仍处于早期阶段。目前,DeepSeek正在接触外部合作伙伴,并与芯片设计企业、晶圆代工厂以及存储企业展开讨论。

陈勇超在 x 平台宣布,正式创立 Apex Intelligence(中文名:超衍智能),主攻自主进化基础模型(Self-Improving Model),公司 Slogan 是"Unlock Undiscovered Discovery"(解锁尙被发现的发现),目标是让大模型从复刻人类已有知识,转向自主发现未知规律。

家人们,最近刷到一个硅谷新瓜——美国有钱人最近流行一种新式鸡娃,把孩子从传统学校撤出来,送进AI私塾。所谓AI私塾,就是上课没有老师、由AI来教的私立学校。最出名的一所叫Alpha School,收着全旧金山最贵的学费:一年7.5万美元,折合人民币约52万。

刚刚,DeepSeek 在官方 API 文档里给出了一个 thinking mode 和 tool call 结合使用的样例。表面上看,这只是一个常规的工具调用演示:用户提出问题,模型判断需要调用工具,工具返回结果后,模型再继续生成答案。

中共北京市委教育科技人才工作领导小组正式印发《北京市加快推进人工智能赋能科学研究实施方案(2026-2028年)》(简称:《实施方案》),成为国内首个覆盖自主实验室、科研智能体、科学大模型、科学数据中心、高价值应用场景等完整体系的AI for Science(AI4S)中长期实施方案。
如果你的日常任务里包含编程,今天给大家介绍一个特别适合团队用的AI开发平台「MonkeyCode」,目前在GitHub已狂揽3.4k Star,开源免费。开源地址:github.com/chaitin/MonkeyCode
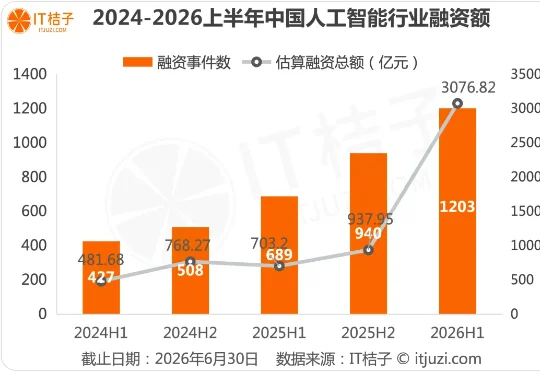
2026年上半年,中国AI创业公司经历了一场狂热的融资热潮,总融资额突破三千亿元,仅6个月的融资体量已超过2025年全年。AI融资金额占市场约48.6%,接近一半,事件数占比约22.5%。

General Intuition 做的事听起来有点绕:用游戏数据训练现实世界里的 AI Agent。换成更直白的话说,General Intuition 做的是让 AI 先在游戏里学会“怎么行动”,再把这种能力迁移到机器人、无人机、自动驾驶、仿真环境里。