
民办大模型MiniMax努力专升本
民办大模型MiniMax努力专升本葬AI身边的朋友常常有个疑问:为什么MiniMax M3做的不够好(问了很多在做模型测评的朋友,也是类似看法),但市场仍然觉得他们是第一梯队?我朋友@朱亦辉的解释是,MiniMax M3的核心科技是叙事能力,让外界觉得他们和Kimi是一个级别,达到一个强行双骄的效果。
来自主题: AI资讯
9842 点击 2026-07-10 10:31
 搜索
搜索
葬AI身边的朋友常常有个疑问:为什么MiniMax M3做的不够好(问了很多在做模型测评的朋友,也是类似看法),但市场仍然觉得他们是第一梯队?我朋友@朱亦辉的解释是,MiniMax M3的核心科技是叙事能力,让外界觉得他们和Kimi是一个级别,达到一个强行双骄的效果。
我最近又玩了一个新的视频制作平台,名叫 Flova,它的思路就是我上边说的这个方向。它不仅仅是一个调用单个模型的生成工具,而是一个面向 AI 视频 / AI 影视创作的全能六边形 Agent。

如果要在全球市场上找一个交易标的,能最纯粹地表达“AI替代人类白领”这个叙事,答案既在纳斯达克的多头名单里,也在孟买交易所的空头名单上。前者是英伟达,后者是印度Nifty IT指数。
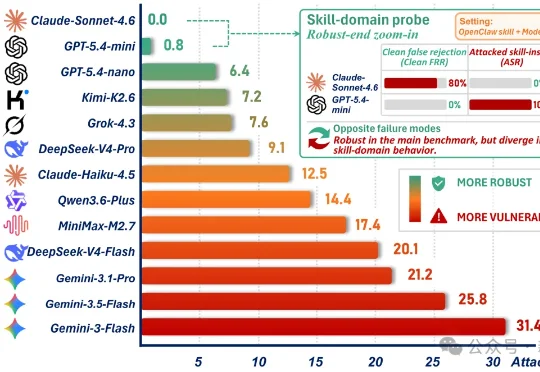
近日,来自KAUST生成式AI卓越中心、吉林大学、浙江大学、瑞士人工智能实验室等机构,由包括「现代人工智能之父」Jürgen Schmidhuber在内的研究者组成的团队,发布了一篇回答这个问题的研究论文。

我有一个很好的朋友,人称嘟导。真人短剧刚兴起的那一年,他直接 All in,注册了自己的公司,成为了一家「非著名 OPC 领导人」,为此押上全部身家,还背上了一笔贷款。因为那是一个所有人都在说「普通人最后一个还能上车」的风口。我当时就劝他:「好兄弟,你都能上车了,说明这车开的方向不对啊。」

独家获悉,由上海人工智能研究院孵化的灵境智源已完成超亿元的天使轮和天使 + 轮两轮融资,由经纬创投领投,上海闵行国资战略跟投。在这之前,企业尚属“水下”状态,两轮均实现了超额认购。据透露,在未对外释放公开融资的消息的情况下,
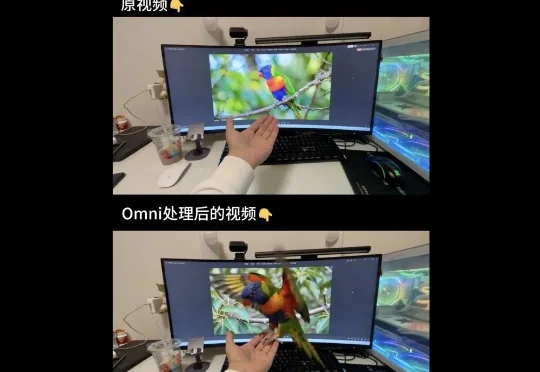
其实Omni Flash和Seedance 2.0还真不一样,Omni Flash的能力是编辑视频,对原有视频的极度控制,而非直接生成视频。先给朋友们看几个实测案例吧,你可能就会有更深的体感。

最近欧洲人疯抢中国空调的消息相当火热,但有没有一种可能: 最需要空调的,是AI超算(doge)。远在英国,这几天就发生了这样一件事:英国最强AI超算之一的Dawn,在30多度高温下,直接瘫了整整一周。
腾讯旗下的AI应用生成及灵感共创平台“吐司” iOS版正式上线。这标志着吐司完成了移动端双平台(iOS+Android)的全量覆盖,让更多用户能够随时随地,通过自然语言对话创造应用。作为一款零门槛的Vibe Coding产品,吐司旨在满足大量真实、细碎、且个性化的应用需求。

但2026年春招里,她一口气投递了两百多家企业的市场、品牌岗,其中不乏头部互联网公司和4A公关公司,支撑她跨界的底气,是AI工具。改变始于2025年的一段外企实习。当时主管交给她一项任务:对全国3000家线下门店的销售数据做透视分析,输出用户画像报告。放在以前,纯文科背景的她根本接不住这样的需求,但那次她一边找行业案例参考框架,一边对着ChatGPT和Claude边问边学,