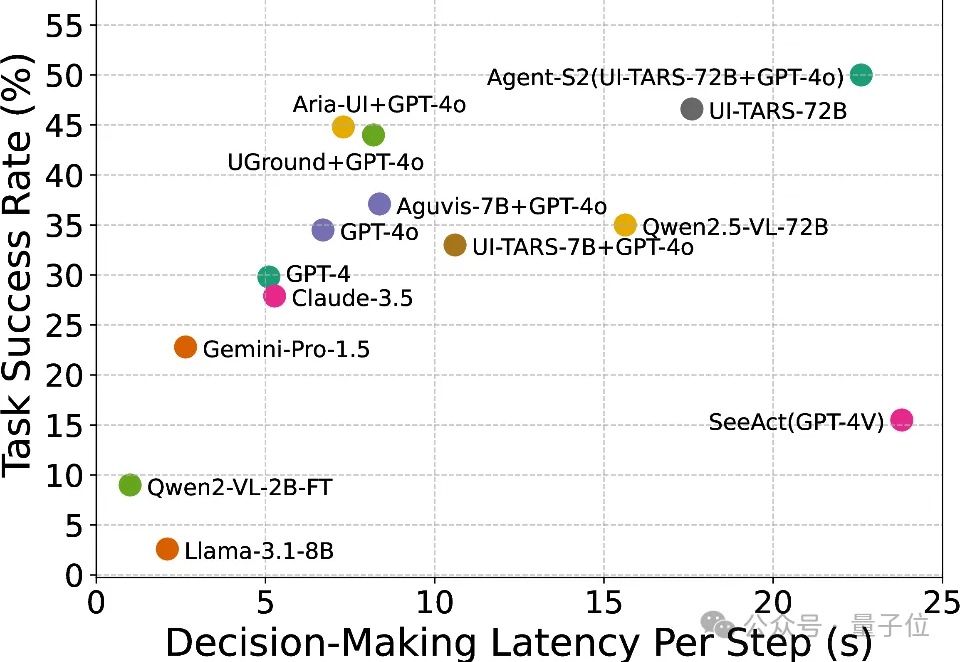
智能体丝滑玩手机,决策延迟0.7秒!MSRA等提出验证器架构,不直接依赖大模型生成最终操作
智能体丝滑玩手机,决策延迟0.7秒!MSRA等提出验证器架构,不直接依赖大模型生成最终操作随着人工智能和大语言模型(LLMs)的不断突破,如何将其优势赋能于现实世界中可实际部署的高效工具,成为了业界关注的焦点。
来自主题: AI技术研报
4320 点击 2025-04-03 15:19
 搜索
搜索
随着人工智能和大语言模型(LLMs)的不断突破,如何将其优势赋能于现实世界中可实际部署的高效工具,成为了业界关注的焦点。
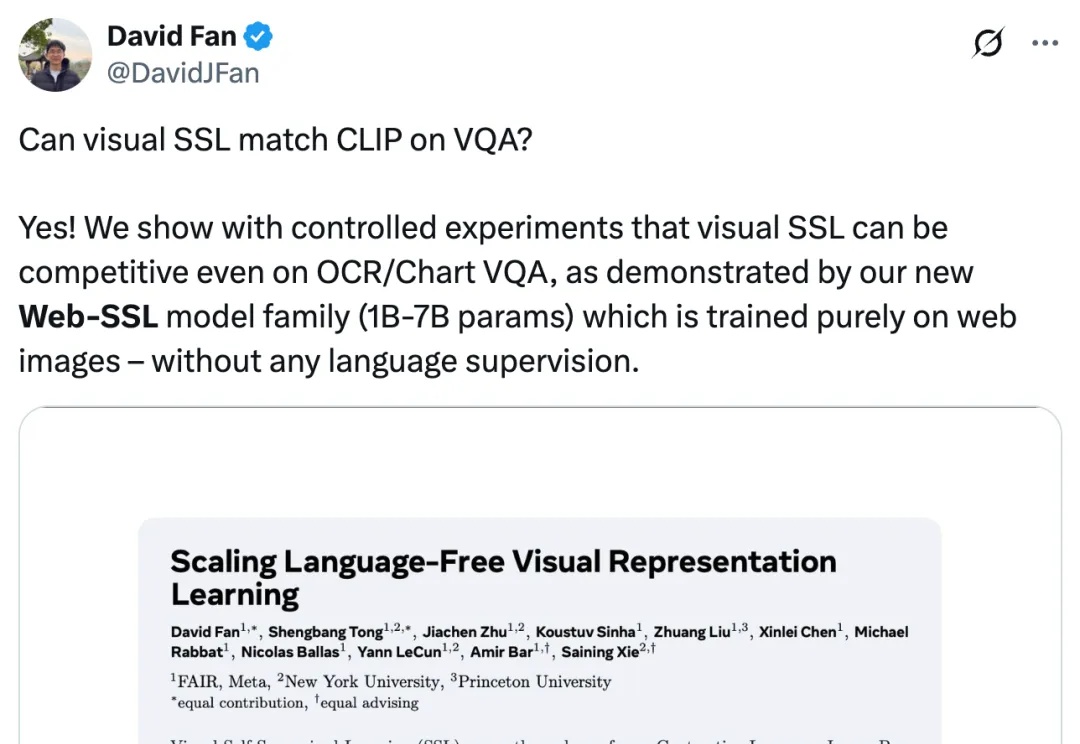
扩展无语言的视觉表征学习。

赛博安慰剂与现实的交锋

PaperBench 是一个由 OpenAI 开发的基准测试,旨在评估 AI Agent 复现尖端 AI 研究的能 力。它专注于测试 AI 是否能理解研究论文、独立开发代码并执行实验以复现研究结果。

当我们遇到新问题时,往往会通过类比过去的经验来寻找解决方案,大语言模型能否如同人类一样类比?在对大模型的众多批判中,人们常说大模型只是记住了训练数据集中的模式,并没有进行真正的推理。
从人设包装到到流量收割
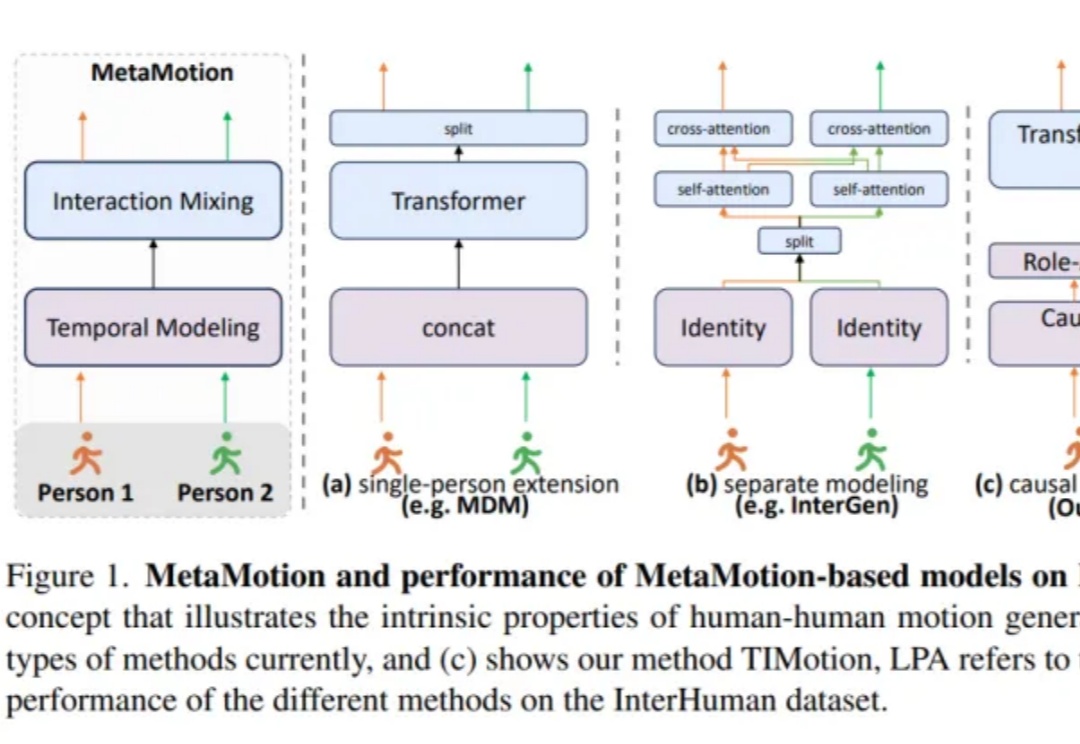
双人动作生成新SOTA!
一个7B奖励模型搞定全学科,大模型强化学习不止数学和代码。

“艺术家与人工智能”的张力正在持续紧张。OpenAI虽然声称避免复制“个别在世艺术家的风格”,但它一直在践行并推动政策允许AI对版权内容的训练;而小部分能够承担高昂诉讼成本的艺术家,却也因为版权法灰色地带而面临不确定的局面,更不要说那些不知名的艺术家们了。
本文从一个需求出发,全程记录如何进行全栈开发。