
MiniMax-M1 登场,MiniMax 再次证明自己是一家模型驱动的 AI 公司
MiniMax-M1 登场,MiniMax 再次证明自己是一家模型驱动的 AI 公司好饭不怕晚,MiniMax 终于把这款金字塔尖的推理模型拿出来了。
来自主题: AI资讯
9086 点击 2025-06-18 15:13
 搜索
搜索
好饭不怕晚,MiniMax 终于把这款金字塔尖的推理模型拿出来了。
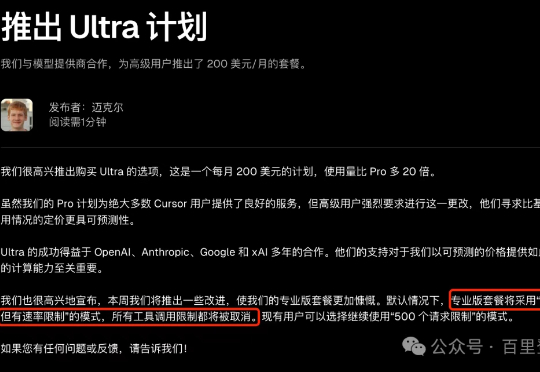
Cursor pro版本直接无限制使用了!

这样复杂精致的视频效果,都是AI生成的?都是最新国产AI大模型的新能力??
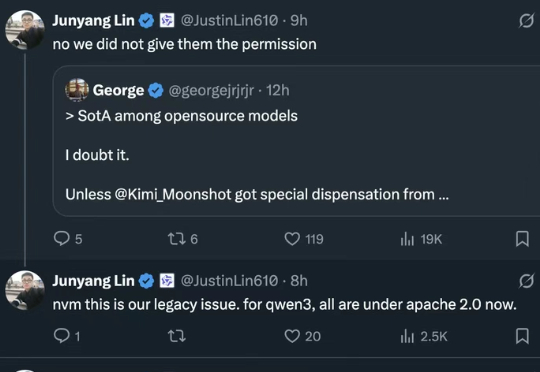
昨天深夜,月之暗面发布了开源代码模型Kimi-Dev-72B。这个模型在软件工程任务基准测试SWE-bench Verified上取得了60.4%的成绩,创下开源模型新纪录,超越了包括DeepSeek在内的多个竞争对手。

YC最新路演显示AI创业风向转向垂直细分领域应用,其占比从2023年的19%飙升至40%。技术门槛因AI工具(如氛围编码)普及而降低,单纯技术背景优势减弱,深入理解特定行业痛点成为新壁垒。创业窗口期缩短,轻量级AI原生团队快速落地产品并实现高增长,通过在成熟赛道重塑工作流创造更大商业价值。

近年来,大型语言模型(LLM)在处理复杂任务方面取得了显著进展,尤其体现在多步推理、工具调用以及多智能体协作等高级应用中。这些能力的提升,往往依赖于模型内部一系列复杂的「思考」过程或 Agentic System 中的 Agent 间频繁信息交互。

AI生成内容著作权保护困境及解决路径。 本文旨在探讨人工智能生成内容的著作权保护问题,以平衡各方利益,推动著作权制度目标的实现,助力文化创意产业与智能科技的深度融合。
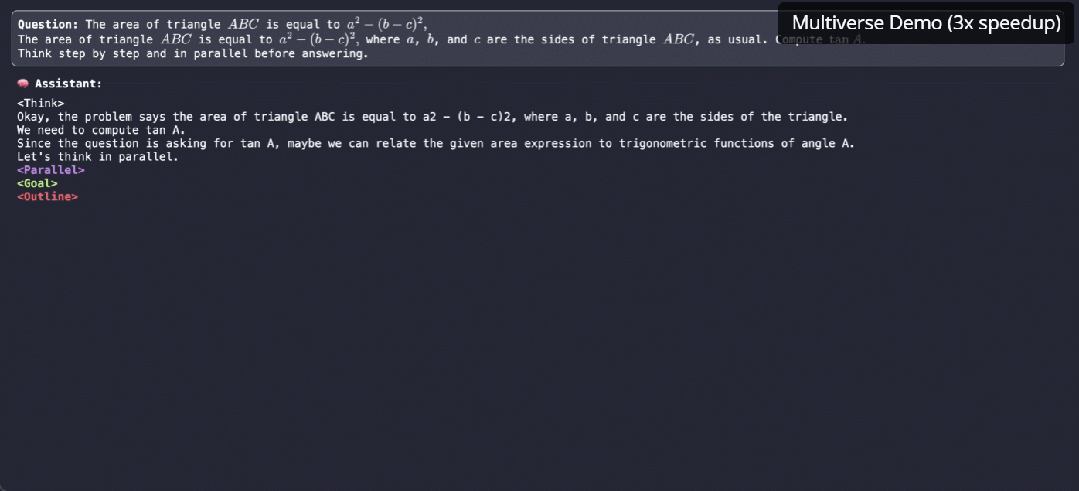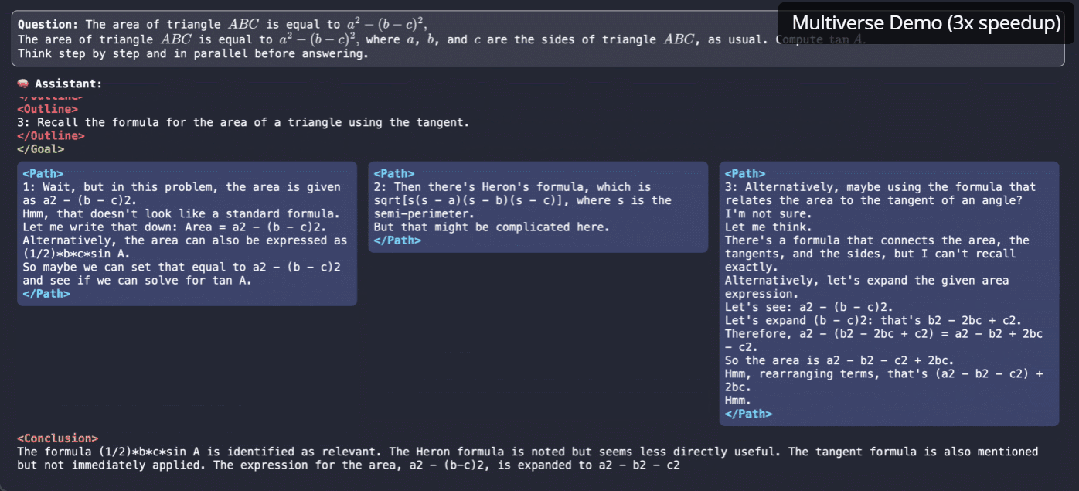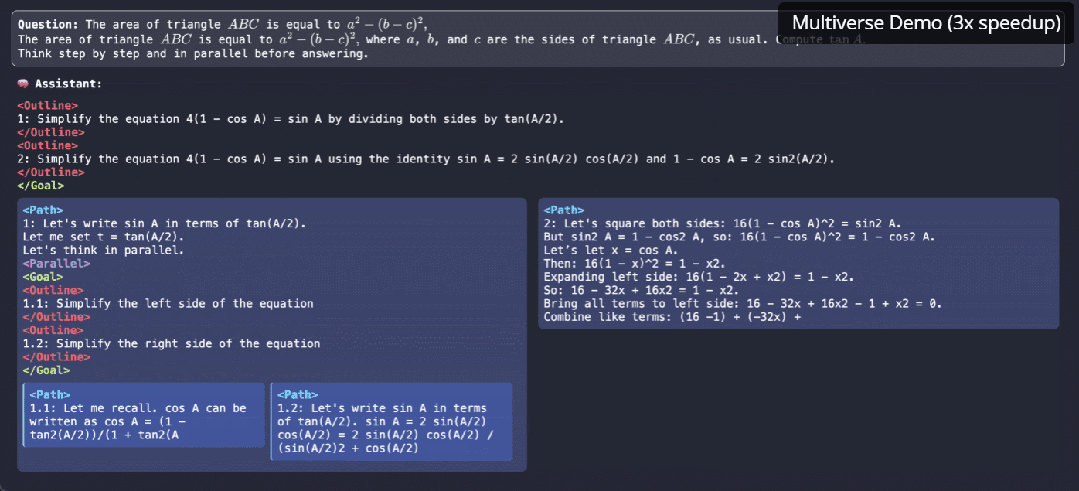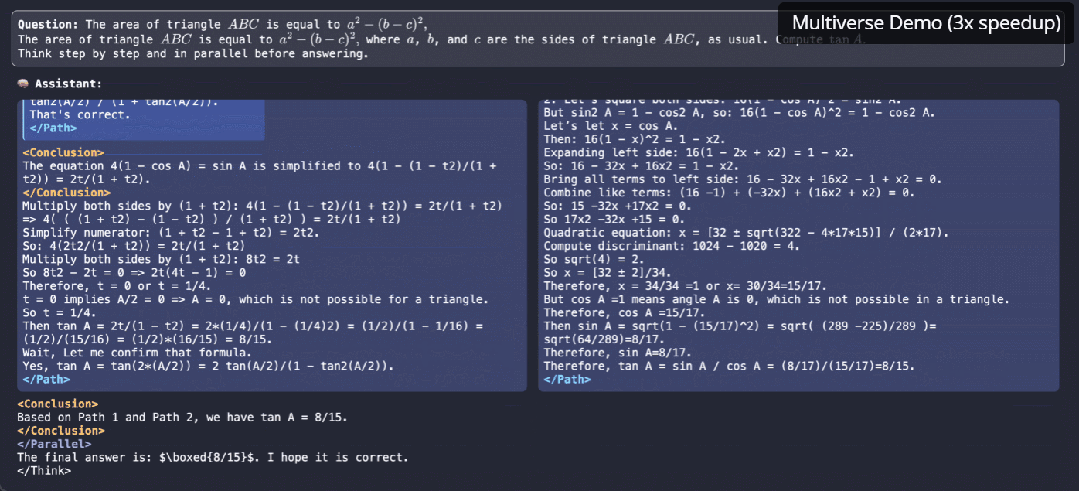
原生并行生成不仅仅是加速,它是我们对 LLM 推理思考方式的根本转变。

这两年AI的发展实在太快了,但直到最近,AI仍被关在数字世界的笼子里。它能思考、能创造,却无法触碰和调动我们物理世界的价值。

AI 也看脸, 每一次网购衣服,都是对自我认知的一次刷新。这不是最近 618 大促吗,再次印证了那句“老话”——看买家秀以为是东方不败,到手一穿像衰神二代。