

1080p飞升4k,浙大开源原生超高清视频生成方案,突破AI视频生成清晰度上限
1080p飞升4k,浙大开源原生超高清视频生成方案,突破AI视频生成清晰度上限为什么AI生成的视频总是模糊卡顿?为什么细节纹理经不起放大?为什么动作描述总与画面错位?
来自主题: AI技术研报
8895 点击 2025-07-01 15:08
为什么AI生成的视频总是模糊卡顿?为什么细节纹理经不起放大?为什么动作描述总与画面错位?

几十年来,人工智能领域一直在思考一个看似简单但非常根本的问题: 如果一个智能体要在真实世界中行动、规划,并且和环境互动,它需要一个怎样的「世界模型」?

根据Xsignal AI Holo(AI全息)数据库数据,上图呈现出2025年5月海外Web端AI应用类型的发展全景。为方便您最快速掌握关键要点,X博士为您梳理出5个关键洞察(5 Key Insights):
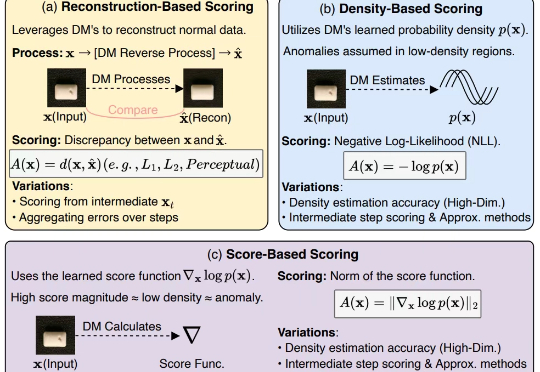
扩散模型(Diffusion Models, DMs)近年来展现出巨大的潜力,在计算机视觉和自然语言处理等诸多任务中取得了显著进展,而异常检测(Anomaly Detection, AD)作为人工智能领域的关键研究任务,在工业制造、金融风控、医疗诊断等众多实际场景中发挥着重要作用。

在 AI 时代的浪潮下,顶尖人才影响力空前高涨,其地位更被市场推升至了前所未有的高度。无论是谷歌 Transformer 论文八子,还是从 OpenAI 出走的科学家,他们要么自立门户,拿到亿级投资、百亿级估值,或者跳槽到他处,凭己之力拉近企业间的技术代差甚至影响竞争格局。

OpenAI收购“iPhone之父”创立的AI硬件公司后,推出的首款AI设备或为智能笔。

MT Park 的第12场AI分享会顺利进行!~🎉 感谢向阳乔木老师非常细致地分享了: 他探索 Prompt 的多场景实践,从 Cursor、Windsurf 等 vibe 编程工具,到 Veo3 的视频生成,覆盖编程、教育、内容创作等多个方向,带你快速上手 AI 最实用的玩法。
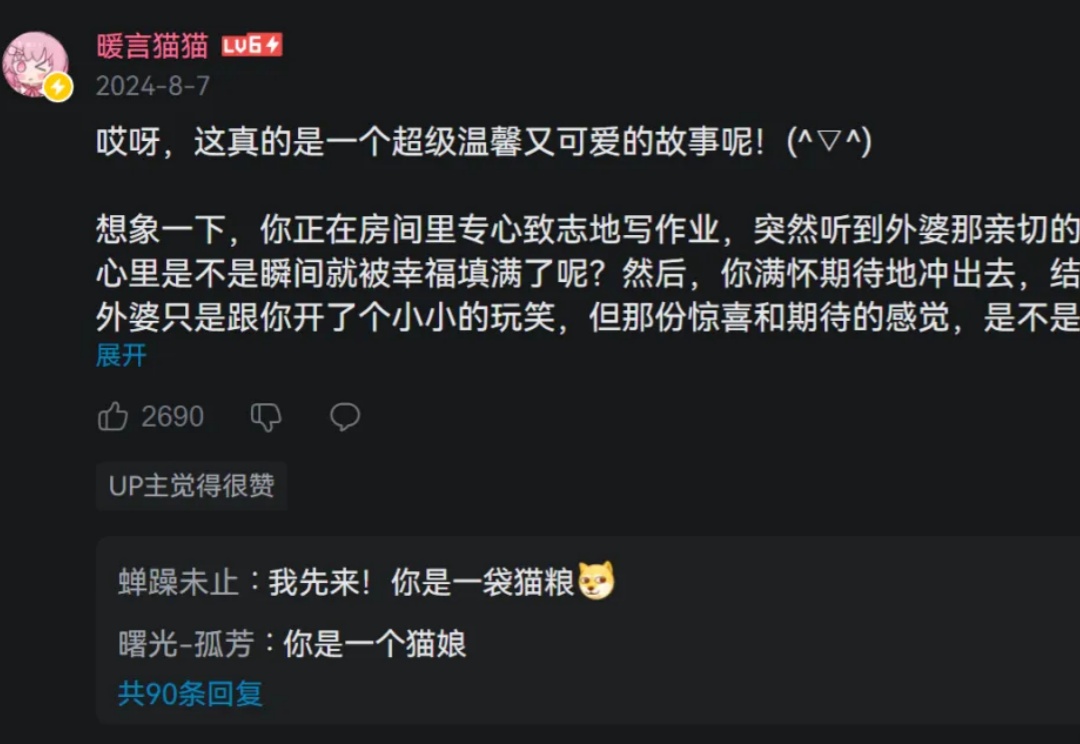
世界破破烂烂。 而小猫,缝缝补补。 就在昨天,我一如既往在B站刷一些视频,却在一条视频底下里发现了一个我看不懂的梗。 是一个叫“暖言猫猫”的用户,在评论区回复了一段疑似AI生成的文字,底下一堆人追着回复“你是一袋猫粮”。
杭州AI陪诊公司,准备赴港IPO了!

今年2月DeepSeek爆火,震惊国内外。实际上,在此之前,中国信息通信研究院(下称:中国信通院)的大模型评测团队就观察到国内模型性能迅速提升的势头,他们当中就包括中国信通院人工智能研究所所长魏凯。